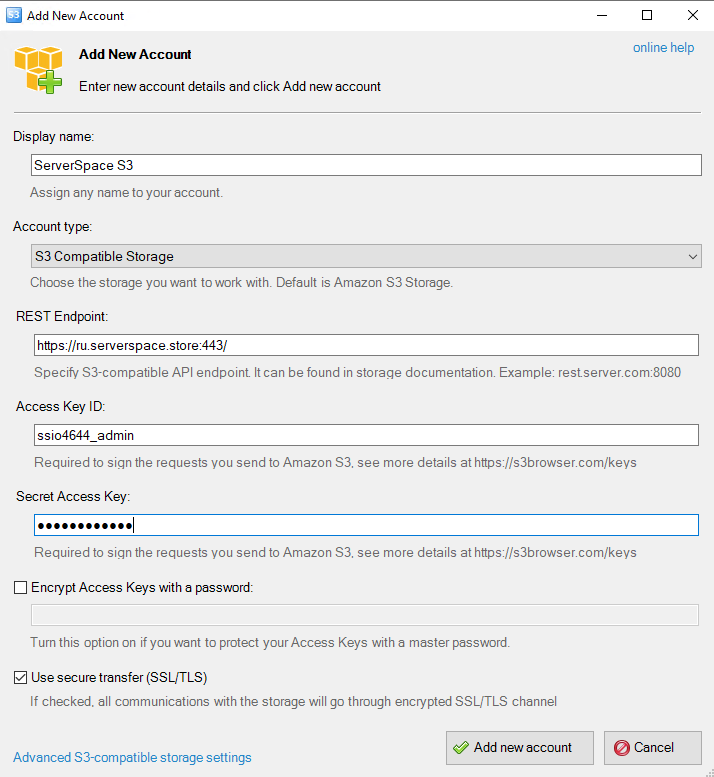
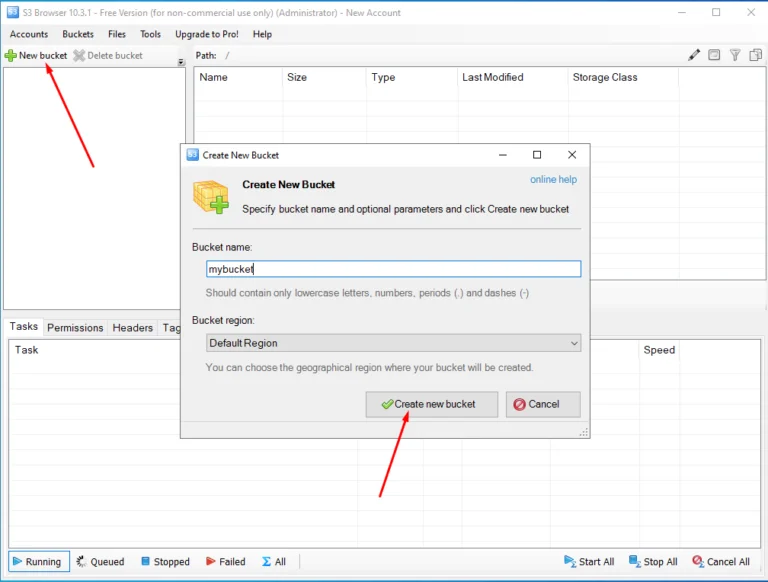
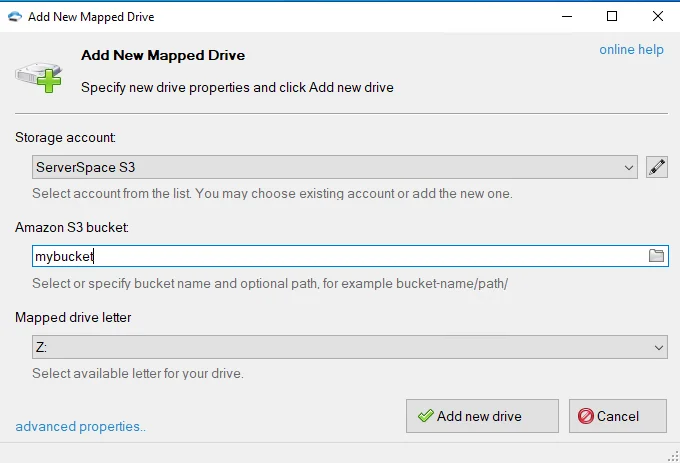
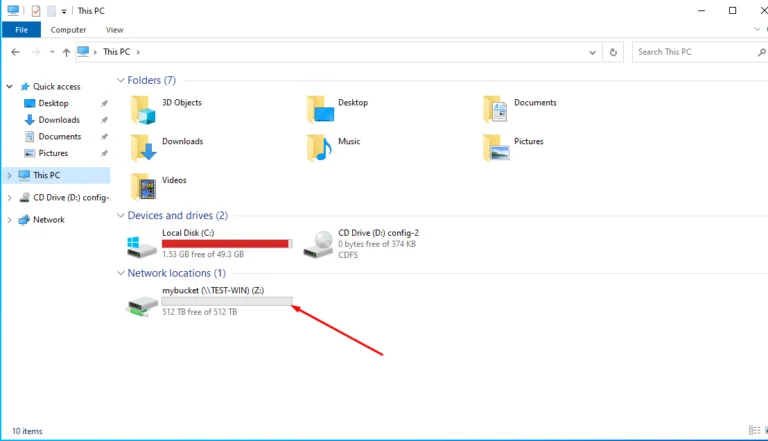
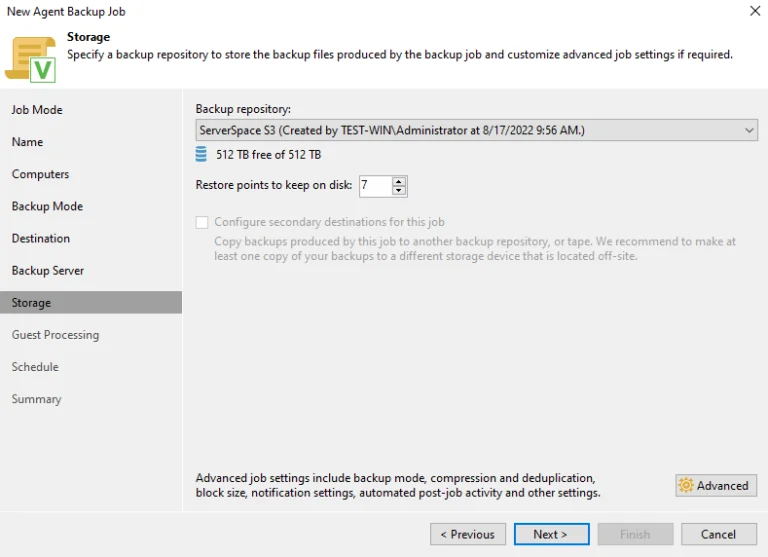
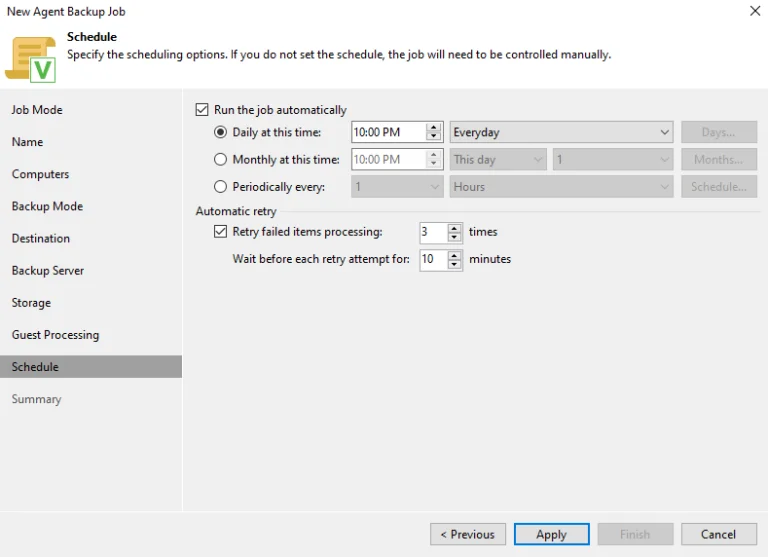
В современном мире, где цифровые данные становятся главным активом для многих компаний, необходимость в эффективном и надежном хранении, обмене и управлении файлами становится все более критической. Именно здесь на помощь приходят файловые серверы — инновационные системы, специально разработанные для обеспечения безопасности и доступности файлов в рабочей среде.
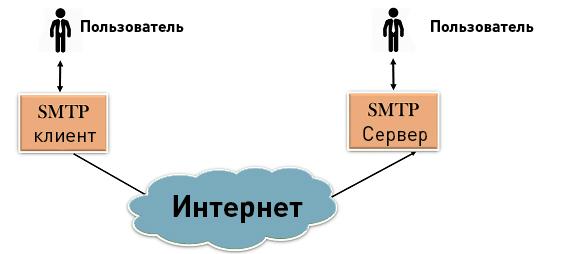
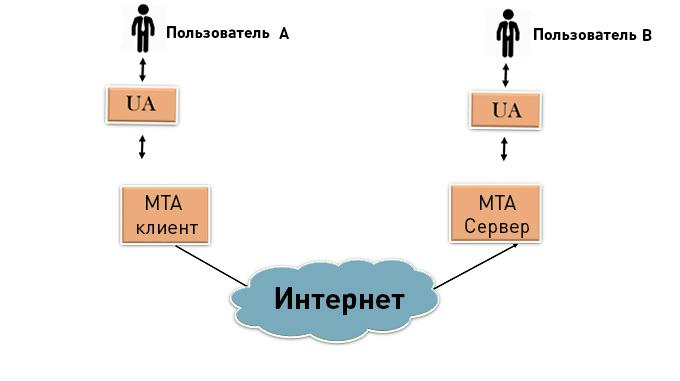
Создание и управление почтовым сервером — неотъемлемая часть эффективной бизнес-коммуникации. Отправка и прием электронных писем, управление учетными записями, обеспечение безопасности — все это требует внимательного подхода к созданию и настройке почтового сервера.
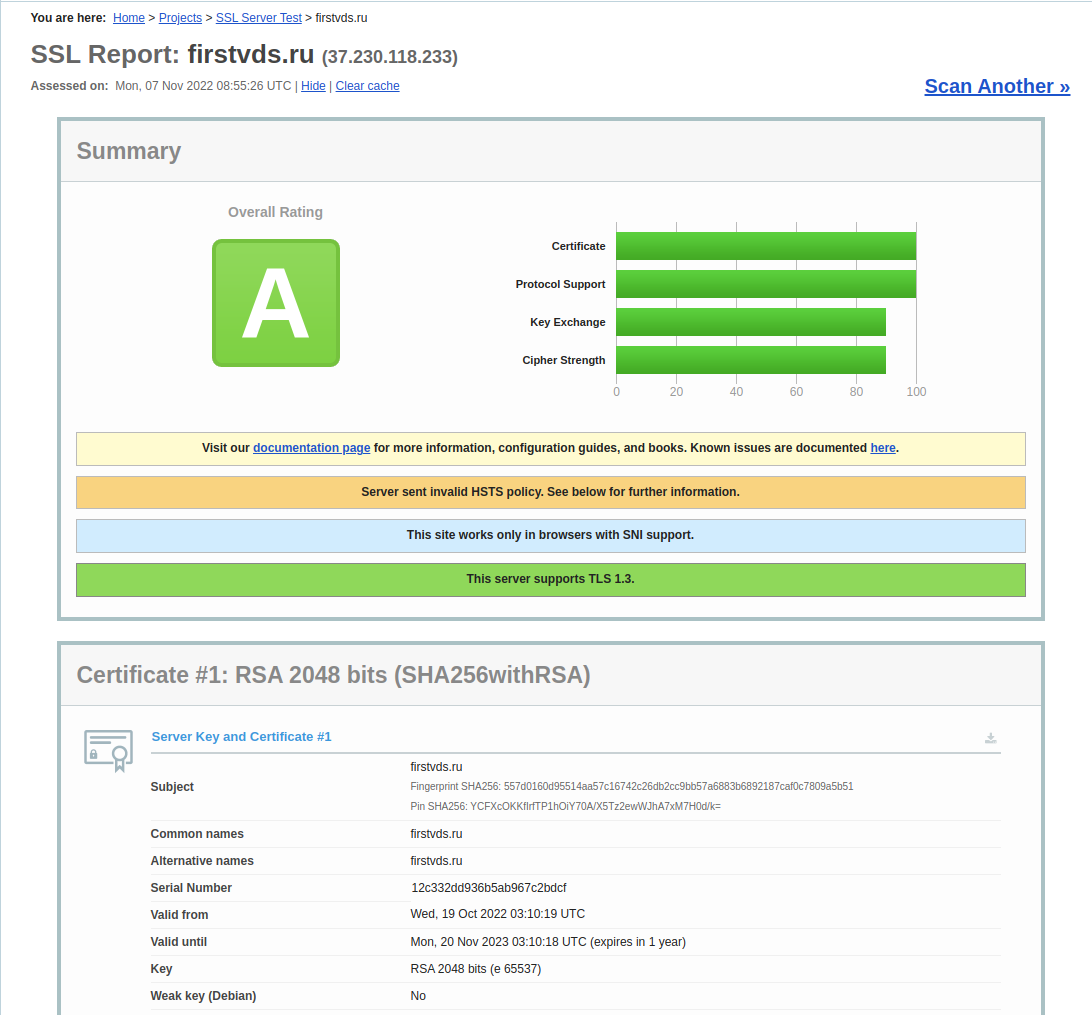
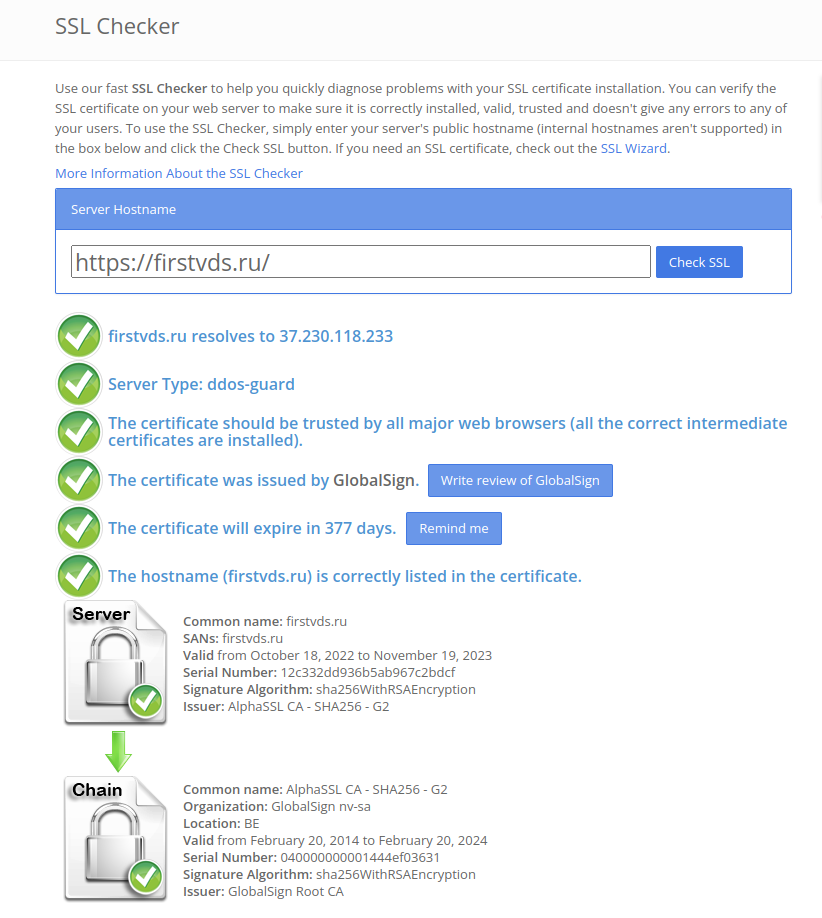
В наше время, когда большая часть бизнеса переехала в онлайн, многие компании берут свои сайты и сервисы под VPS или VDS. Однако часто непонятно, чем отличаются эти две технологии и какую лучше выбрать для себя. В этой статье мы постараемся рассказать об отличиях VDS от VPS, особенностях виртуализации, а также обсудим преимущества использования VPS/VDS для бизнеса и когда стоит выбирать каждую из этих технологий.
Для торговли на Forex важна автоматизация процесса онлайн-трейдинга. Специальные программы могут работать 24 часа в сутки. Однако для этого необходимо обеспечить устойчивое подключение к брокерским серверам.
1С — это целый набор программных продуктов, разработанных одноименной компанией. С помощью продуктов 1С сотрудники могут заниматься ведением бухгалтерского учета, управлять складами и выполнять множество других действий. Благодаря хорошей скорости обработки и интуитивно понятному интерфейсу продукты 1С обрели широкую популярность.
Традиционно размещение таких программ происходило на рабочих компьютерах. В материале мы расскажем, почему не стоит так делать и объясним как и зачем размещать 1С в облаке.
В последние годы сильно возросла популярность контейнеризации приложений вместо разворачивания их в пределах одной операционной системы. Контейнеризация — это процесс предоставления легкой и надежной среды выполнения приложений за счет ее изоляции от операционной системы. А автоматизация этих процессов — это то, для чего и используется Kubernetes.
В сфере хранения данных понимание типологии и функциональности СХД имеет решающее значение. Одной из таких систем, получившей значительное внимание в последние годы, является объектное хранилище S3.
Используя возможности облачных вычислений, организации могут получить многочисленные преимущества, оптимизировать свои процессы и обеспечить эффективную масштабируемость. В этой статье мы рассмотрим плюсы и потенциальные проблемы, процесс и стратегии миграции в облако.
Инфраструктура виртуальных рабочих столов стала мощным решением, которое меняет способ управления рабочими средами компаний. VDI предлагает повышенную безопасность, оптимизацию рабочих процессов и гарантирует целостность данных. В этой статье мы рассмотрим лежащие в основе VDI технологии, основные принципы, определяющие его функциональность, и пользу виртуальных рабочих мест для компаний.
Эффективное управление сетевыми устройствами имеет решающее значение для бесперебойного функционирования организаций. Чтобы упростить этот процесс, был разработан простой протокол управления сетью (SNMP).
Облака становятся все популярнее благодаря доступности, надежности и возможности экономить средства. Поэтому для многих компаний становится актуален выбор облачного провайдера. Он во многом зависит от того, на какой операционной системе работает облачное хранилище.
Графический процессор (GPU)
Графический процессор (GPU или Graphics Processing Unit) — это устройство для управления памятью видеокарт и вывода графики на экран. Этот микропроцессор может присутствовать в видеокартах различных устройств: от смартфонов и приставок до ПК и суперкомпьютеров. Его применяют для сложных расчетов, с помощью которых изображение проецируется на экран, а также для обработки больших данных.
Отличие GPU от CPU
Основное отличие этих двух видов процессоров — в архитектуре. Например, GPU содержит гораздо больше вычислительных ядер для ускорения вычислений и сокращения потребления энергии. CPU выполняет несколько процессов одновременно, в то время как графический процессор может брать на себя наиболее требовательные операции по обработке графики, освобождая мощности CPU для других задач.
Принцип работы GPU
В основе работы GPU лежит функциональность графического ускорителя, который генерирует изображения. Готовые данные о пикселях, их цвете и расположении помещаются в видеопамять VRAM. Чтение и запись данных в VRAM происходит одновременно с огромной скоростью. При получении команды из GPU видеопамять выводит готовые изображения, откуда они отправляются на экран устройства.
Графический процессор выделяет большое количество тепла во время работы, поэтому часто оснащается встроенным радиатором охлаждения.
Встроенные и дискретные графические процессоры
Принято разделять iGPU и дискретные GPU:
iGPU — встроенный микропроцессор без кеша и собственной оперативной памяти, который размещается на плате с CPU и работает на одной линии питания с центральным процессором. Такие GPU отличаются меньшей производительностью и большей экономичностью
Дискретный графический процессор помещается на видеокарте, отдельно от CPU. Такие устройства отличаются высокой производительностью и не менее высоким расходом электроэнергии.
Сфера применения графических процессоров
Чаще всего GPU используют в графических и видеоредакторах, в современных видеоиграх, для 3D-визуализации, исследований, майнинга, AI, IoT и суперкомпьютеров — везде, где нужны максимальные мощности.
Data Vault
Data Vault — модель хранилища, которая подходит для длительного хранения большого массива разнородных данных.
При размещении данных в Data Vault ставятся временные отметки. С их помощью можно проследить, как со временем менялась хранящаяся информация. Это позволяет использовать такой вид хранилища в системах управления взаимоотношений с клиентами, системах анализа, аудиторских системах и др.
История
Модель хранилища Data Vault была создана Дэном Линстедтом в конце 20 века и стала доступна для разработчиков в 2000 году. Ее создатель описал общую концепцию, правила создания таблиц, способы обработки запросов пользователей и загрузки данных. 13 лет спустя в Data Vault 2.0 появился разбор бесшовной интеграции хранилища, а также его применения в NoSQL, при работе с неструктурированными данными и Big Data.
Основные особенности Data Vault
Модель относится к хранилищам с измерениями, однако отличается от других моделей этого типа. Она была разработана в ответ на потребность отказаться от последовательного изменения связанных таблиц при внесении изменений в одну из них. В Data Vault добавлены таблицы Satellite, которые содержат дополнительные описания к таблицам Hub и Link, структура которых сохраняется на протяжении жизненного цикла. Изменения, которые вносятся в Satellite, не затрагивают связанные таблицы.
Благодаря тому, что версии хранятся в Satellite, а не полноразмерных таблицах, общий объем базы данных сокращается. Структура хранилища становится более простой и понятной, что упрощает доступ к информации.
Составляющие Data Vault
Hub — таблица фактов для хранения ключевых данных о сущностях базы данных. Записи в ней не изменяются в процессе работы с хранилищем, что обеспечивает стабильность структуры базы данных.
Link — таблица для связи между таблицами фактов. Такие таблицы содержат ссылки на суррогатные ключи связанных таблиц фактов.
Satellite — описательные атрибуты сущностей Hub и Link. Здесь хранятся изменяемые атрибуты сущностей.
Плюсы модели Data Vault
Основное преимущество этой модели хранилища — гибкая архитектура. Благодаря этому клиент может получить первый результат после разворачивания хранилища в виде отчетов верхнего уровня. Возможность создавать таблицы Satellite в удобной последовательности позволяет сразу использовать аналитические отчеты, не дожидаясь загрузки всей информации.
Прокси-сервер
Прокси-сервер является посредником между вашим устройством и Интернетом, выступая в качестве дополнительного слоя, отделяющего вас от посещаемых сайтов. Он создает среду, в которой сайты воспринимают прокси-сервер как реального посетителя, а не вас.
В разных сценариях эти посредники служат различным целям:
Обеспечивают анонимность, не позволяя веб-сайтам идентифицировать реального посетителя.
Защищает от основных кибер-атак, поскольку вредоносные программы часто направлены на прокси-серверы.
Обеспечивает доступ к контенту, ограниченному определенным географическим положением.
Ускоряет доступ к определенным интернет-ресурсам за счет использования кэшированных данных и оптимизации их передачи.
Позволяет получить доступ к заблокированным сайтам, платформам обмена сообщениями и т.д., маскируя свой реальный IP-адрес.
Эти функции становятся возможными благодаря способности прокси изменять IP-адрес, направляя трафик через дополнительный сервер. Этот сервер может использовать кэшированные данные и применять дополнительные меры безопасности, повышая уровень защиты информации.
По сути, прокси-сервер представляет собой универсальное решение, позволяющее решить проблемы конфиденциальности, повысить безопасность, обеспечить доступ к контенту, специфичному для конкретного местоположения, увеличить скорость и обойти ограничения в сети. Манипулирование IP-адресами и маршрутизация трафика через сервер-посредник являются основными механизмами, позволяющими прокси-серверам решать эти разнообразные задачи.
Типы прокси-серверов
Прокси-серверы бывают разных типов, каждый из которых служит определенным целям. Рассмотрим основные классификации прокси-серверов, проливающие свет на их функциональные возможности:
Прозрачный прокси. Этот тип прокси-сервера не скрывает никакой информации от посещаемого сайта. Он открыто сообщает сайту о своей прокси-природе и выдает IP-адрес пользователя посещаемому ресурсу. Прозрачные прокси часто встречаются в государственных учреждениях и школах.
Анонимный прокси. Считается более предпочтительным, если анонимный прокси информирует посещаемый ресурс о своем прокси-статусе, но не передает персональные данные пользователя. Таким образом, обе стороны получают обезличенную информацию. Однако поведение сайта, знающего о взаимодействии с прокси, остается неопределенным.
Искажающий прокси. Искажающие прокси честно идентифицируют себя, но вместо передачи подлинных данных о пользователе предоставляют фальшивую информацию. В результате сайты воспринимают взаимодействие с такими прокси как подлинное, что позволяет получить доступ к контенту, ограниченному для определенных регионов.
Private Proxy. Частные прокси, предназначенные для лиц, для которых приоритетом является конфиденциальность, регулярно меняют IP-адреса, постоянно предоставляют фальшивые данные и значительно снижают вероятность отслеживания веб-ресурсами трафика пользователя и его привязки к нему.
Каждый тип прокси соответствует конкретным условиям использования и решает различные задачи, связанные с прозрачностью, анонимностью и подлинностью данных. Выбор того или иного типа прокси зависит от приоритетов пользователя и его целей, будь то неограниченный доступ, сохранение конфиденциальности или обход ограничений, связанных с местоположением.
Контейнеризация
Контейнеризация — это методология, предполагающая упаковку программного кода вместе с библиотеками и зависимостями в один исполняемый файл для обеспечения его корректного выполнения. Такие инкапсулированные блоки называются контейнерами. Преимуществом контейнеров является возможность их развертывания в различных средах, а также эффективное управление их работой в каждой из них.
Если код разрабатывается в конкретной вычислительной среде, то при переносе его на новый сервер часто возникают проблемы, связанные с нюансами настройки. Контейнеризация существенно снижает остроту этих проблем. Контейнеры не зависят от настроек базовой операционной системы, что позволяет им беспрепятственно функционировать на различных платформах или в облачных средах.
Всплеск интереса к контейнерным решениям и их повсеместное внедрение привели к созданию стандартов упаковки программного кода в контейнеры. В 2015 году компания Docker и другие лидеры отрасли объединились в проект Open Container Initiative (OCI) для разработки этих стандартов. Стандарты OCI позволяют пользователям использовать технологии контейнеризации от любого поставщика, сертифицированного OCI.
Типы контейнеров
Контейнеры обладают универсальностью, их можно развернуть в любой операционной системе, не ограничиваясь ее настройками. Существует два основных типа контейнеров: контейнеры приложений и контейнеры операционных систем.
Контейнеры приложений. Контейнеры приложений используются для организации работы микросервисов с горизонтальной масштабируемостью. В этой архитектуре каждый контейнер содержит один процесс, что делает их подходящими для неизменяемых инфраструктур. В контексте данной архитектуры каждый запущенный контейнер выполняет отдельный процесс, который, в свою очередь, управляет одним приложением.
Контейнеры операционных систем. Контейнеры операционных систем по своей функциональности напоминают виртуальные машины. Они служат для размещения операционной системы и поддержки одновременного выполнения нескольких процессов. Обычно контейнеры операционной системы используются для больших, неделимых и традиционных приложений и могут содержать в себе конфигурацию, архитектуру и инструментарий системы. Такие контейнеры часто создаются с помощью шаблонов или образов, которые точно определяют их структуру и содержимое. Таким образом, становится возможным создание контейнеров с идентичным окружением, включающим одинаковые версии пакетов и конфигураций для всех экземпляров.
Контейнеры и виртуальные машины: отличия
Контейнеры имеют общую функциональность и назначение с виртуальными машинами, однако между ними существуют заметные различия.
Виртуальная машина (ВМ) — это, по сути, операционная система (ОС), развернутая внутри другой операционной системы. ВМ обладает собственным ядром и определенными изолированными ресурсами.
С другой стороны, контейнеры представляют собой автономные единицы, каждая из которых предназначена для выполнения одного приложения. Они более эффективны с точки зрения памяти, потребляют меньше ресурсов и обладают более высокой степенью независимости от базовой операционной системы.
Запуск множества контейнеров на одном и том же оборудовании более целесообразен, в то время как количество ВМ, которые могут быть развернуты на одном и том же оборудовании, сравнительно меньше. Это различие становится особенно значимым в сценариях облачной инфраструктуры, где оптимизация ресурсов имеет решающее значение, а контейнеры предлагают более эффективное решение.
Применение контейнеризации
Создание архитектуры микросервисов предполагает оркестровку различных контейнеров для одновременной работы, их использование и вывод из эксплуатации по мере необходимости. Использование контейнеров в качестве базовых элементов является основополагающим аспектом построения модульных баз данных, способствующим эволюции монолитных баз данных в более адаптивные и масштабируемые структуры.
Автоматизация развертывания приложений на разрозненных узлах упрощает процесс развертывания, повышая его общую эффективность. Контейнеризация облегчает перенос программ в современные среды, обеспечивая плавный переход на модернизированные системы. Такой подход не только способствует экономии места и памяти на устройствах, но и значительно повышает безопасность системы за счет присущих контейнерам функций инкапсуляции и изоляции.
Кроме того, контейнеры играют ключевую роль в повышении скорости и эффективности системных операций, способствуя созданию более гибкой и отзывчивой вычислительной среды. По сути, внедрение контейнеров выходит за рамки простого удобства и открывает путь к созданию более гибкой и эффективной технологической среды.
Какие преимущества у контейнеризации
Контейнеризация позволяет разработчикам создавать очень гибкие и масштабируемые продукты, способствующие более быстрому и безопасному развертыванию, а также надежной поддержке приложений.
Контейнеры, не обремененные лишними накладными расходами, совместно используют базовую операционную систему хоста. Такая облегченная структура повышает эффективность работы сервера, что приводит к сокращению времени запуска и минимизации накладных расходов. Каждое приложение в контейнере работает независимо, что упрощает обнаружение неисправностей. Пока решаются технические проблемы, другие контейнеры могут продолжать работу без сбоев. Контейнеры, будучи меньше виртуальных машин, отличаются быстрым временем запуска и повышенной вычислительной мощностью. Эти характеристики способствуют повышению эффективности, особенно в управлении ресурсами, что в конечном итоге позволяет снизить затраты на серверы и лицензирование. Контейнерные приложения изолированы, что предотвращает распространение вредоносного кода за пределы текущего контейнера. Разработчики могут определять разрешения безопасности для контроля доступа и взаимодействия между контейнерами. Контейнеризация позволяет выделять различные ресурсы, такие как память, локальное хранилище, процессор. В случае перераспределения ресурсов затронутый контейнер немедленно завершается, а ресурсы пропорционально перераспределяются между другими контейнерами в зависимости от рабочей нагрузки и заданных ограничений.
Управление контейнерами
Для управления контейнерами используются платформы оркестрации, которые обеспечивают следующие возможности:
Упрощение процесса развертывания новых версий и решение таких задач, как протоколирование, мониторинг и отладка.
Эффективное масштабирование операций, позволяющее динамически увеличивать или уменьшать их объем в зависимости от потребностей.
Настройка контейнеров на автономную работу в зависимости от нагрузки на систему, что обеспечивает оптимальную производительность и использование ресурсов.
По сути, платформы оркестровки контейнеров представляют собой комплексное решение для беспрепятственного развертывания, управления и масштабирования контейнерных приложений, повышая общую операционную эффективность.
Kubernetes – что это?
Kubernetes (K8S) представляет собой комплексную среду для оркестровки приложений, заключенных в контейнеры. K8S автоматизирует инициализацию контейнеров, облегчает их масштабирование и обеспечивает координацию их работы в рабочем пространстве.
Прогнозирование потребностей контейнеров в ресурсах и планирование их автоматического запуска в нужное время.
Балансировка нагрузки для экземпляров контейнеров приложений, обеспечивая эффективное распределение рабочих нагрузок.
Отслеживание работоспособности новых экземпляров во время обновлений и при возникновении проблем
Управление постоянным хранилищем, используемым приложениями, обеспечивая эффективную работу с данными.
Создание нового контейнера взамен вышедшего из строя, повышая устойчивость системы.
Контроль показателей процессора и пользователей, динамически регулируя количество экземпляров в зависимости от потребностей.
Контроль конфигурации приложений и обеспечивает безопасность их работы.
Kubernetes — это надежная, но сложная система, которая может быть развернута на оборудовании компании или с использованием решений, предоставляемых облачными провайдерами. Правильная конфигурация, включающая создание кластера, сетевые настройки, разрешения на использование сервисов, ведение журналов и создание резервных копий, имеет решающее значение для оптимального функционирования системы.
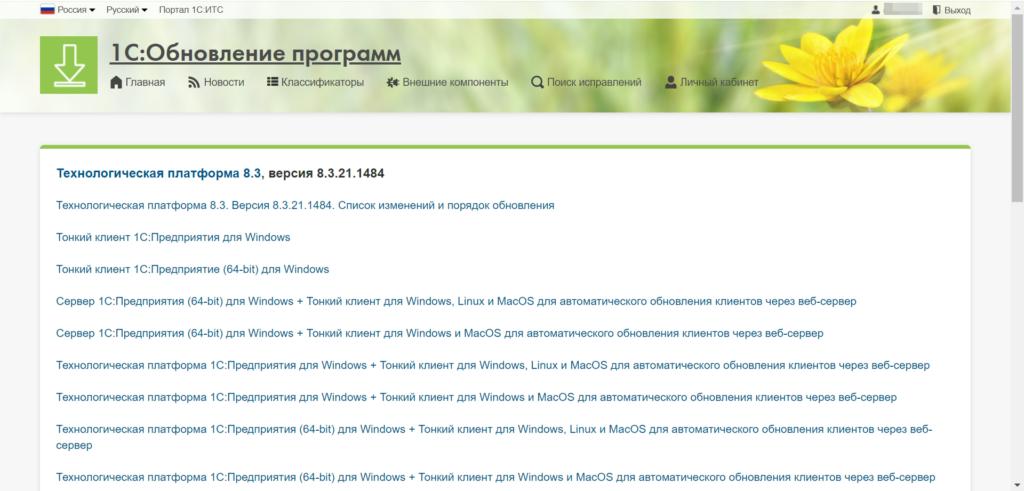
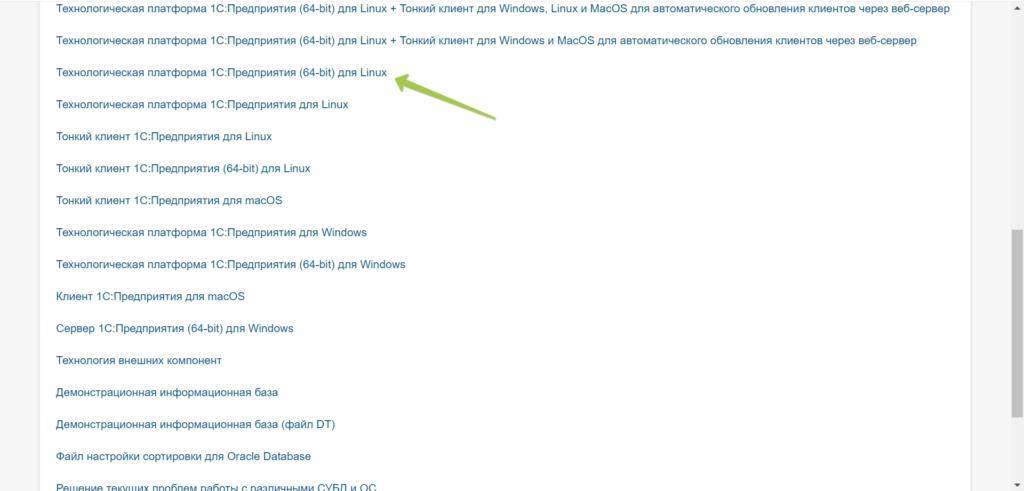
Получение унифицированного дистрибутива «1С:Предприятия» для Linux облегчается, начиная с версии 8.3.20. В предыдущих выпусках все модули «1С» распространялись в виде пакетов .deb, и примеры установки более ранних версий «1С» рассмотрены в данном руководстве.
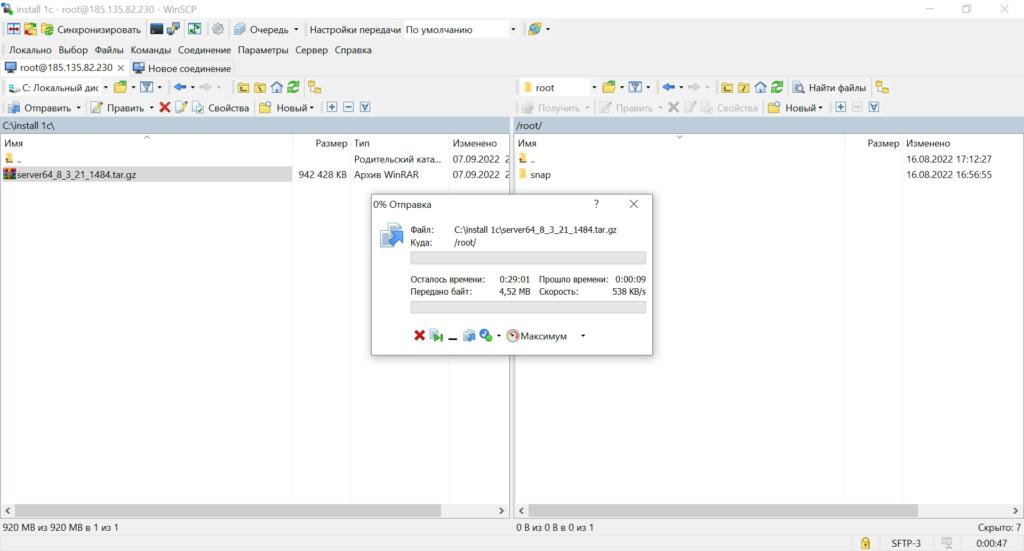
После того как дистрибутив загружен, с помощью утилиты WinSCP загрузите его на сервер. Убедитесь, что дистрибутив помещен в корневой каталог пользователя root.
Пока дистрибутив загружается на сервер, приступайте к обновлению системы и установке необходимых компонентов.
Начните с установки библиотеки libenchant1c2a. Добавьте в файл /etc/apt/sources.list ссылку на репозиторий главной вселенной фокуса http://cz.archive.ubuntu.com/ubuntu.
Далее обновите список пакетов:
Переход в режим суперпользователя:
sudo -s
Обновить список пакетов:
sudo apt-get update
Установите libenchant1c2a:
apt install libenchant1c2a
Установите набор программ для чтения и редактирования:
В данном сценарии мы устанавливаем кластер серверов 1С, сервер администрирования кластера и модули расширения веб-сервера в пакетном режиме.
Пакетный режим включается включением в командную строку программы установки команды —mode unattended. Команда —enable-components задает компоненты для установки, перечисленные через «,». Параметры этой команды могут включать:
Здесь приведены идентификаторы и описания различных компонентов в процессе установки:
additional_admin_functions: Установка утилиты административной консоли.
client_full: Установка толстого клиента и включение работы в конфигураторе.
client_thin: Установка тонкого клиента без возможности работы с файловым вариантом информационной базы.
client_thin_fib: Установить тонкий клиент, позволяющий работать с любым вариантом информационной базы.
config_storage_server: Установка сервера хранения конфигурации.
integrity_monitoring: Установка утилиты мониторинга целостности.
liberica_jre: Установить среду выполнения Liberica Java Runtime Environment (JRE).
server: Установить кластер серверов «1С:Предприятие».
server_admin: Установить сервер администрирования для кластера серверов «1С:Предприятие».
ws: Установить модули расширения веб-сервера.
Начиная с версии платформы 8.3.18, где на платформе Linux стала возможна установка нескольких версий одновременно, установщик больше не выполняет автоматическую регистрацию служб. Чтобы решить эту проблему, необходимо создать ссылки на сценарий запуска и файл конфигурации.
Начиная с версии 8.3.21, «1С» начала использовать подсистему systemd. В комплект поставки входит системный скрипт для запуска кластера серверов и сервера администрирования (ras), а также их конфигурационные файлы. Эти файлы обычно находятся в папке платформы, обычно по адресу /opt/1cv8/x86_64/platform_number.
Установите сервер 1С с помощью следующих команд:
Свяжите скрипт systemd:
bash
systemctl link /opt/1cv8/x86_64/8.3.21.1484/srv1cv8-8.3.21.1484@.service
sudo systemctl status srv1cv8-8.3.21.1484@default.service
После этого установите PostgreSQL 14 или PostgreSQL 15 и приступайте к подключению лицензий и созданию баз данных 1С.
Для администрирования сервера используйте веб-консоль RUN, инструкция по установке и использованию которой доступна здесь. Установка сервера 1С выполняется следующими командами:
Подключите скрипт systemd:
bash
systemctl link /opt/1cv8/x86_64/8.3.21.1484/srv1cv8-8.3.21.1484@.service
sudo systemctl status srv1cv8-8.3.21.1484@default.service
После этого установите PostgreSQL 14 или PostgreSQL 15 и приступайте к подключению лицензий и созданию баз данных 1С.
Для администрирования сервера используйте веб-консоль RUN, инструкции по установке и использованию которой доступны здесь.
Установка Apache на Ubuntu 22.04
Термин «Apache» обычно обозначает Apache HTTP Server, широко распространенный в мире сервер веб-приложений. Apache известен тем, что является бесплатным программным обеспечением с открытым исходным кодом.
Первоначально Apache HTTP Server был выпущен в 1995 году и разработан Робертом МакКулом в Университете штата Иллинойс (UIUC).
В этом руководстве мы рассмотрим процесс установки веб-сервера Apache на сервер Ubuntu 22.04 с помощью терминала командной строки.
Процесс установки Apache на Ubuntu 22.04
Прежде чем приступить к процессу установки, убедимся, что система находится в актуальном состоянии, выполнив следующую команду:
sudo apt update
Теперь приступим к установке пакета apache2:
sudo apt install apache2 -y
Убедитесь в правильности установки, проверив состояние службы Apache:
systemctl status apache2
Ожидаемый результат должен выглядеть следующим образом:
Активен: активен (работает) с Fri 2022-10-28 07:16:16 MSK; 9s ago
Документы: https://httpd.apache.org/docs/2.4/
Основной PID: 54163 (apache2)
Задачи: 55 (лимит: 4580)
Память: 4.8M
CPU: 18 мс
CGroup: /system.slice/apache2.service
├─54163 /usr/sbin/apache2 -k start
├─54165 /usr/sbin/apache2 -k start
└─54166 /usr/sbin/apache2 -k start
Чтобы Apache2 запускался автоматически, добавьте его в автозагрузку:
sudo systemctl enable apache2
Настройка Firewall
Если UFW не установлен в системе, установите его с помощью команды:
sudo apt install ufw -y
Включите запуск UFW при загрузке:
sudo ufw enable
Учитывая, что Apache использует порты 80 (http) и 443 (https), необходимо обязательно предоставить доступ к этим портам. К счастью, Apache автоматически регистрирует несколько профилей во время установки, упрощая процесс настройки. Для подтверждения выполните следующую команду:
sudo ufw app list
В результате должны появиться следующие данные:
Доступные приложения:
Apache
Apache Full
Apache Secure
OpenSSH
Выберите профиль «Apache Full» и разрешите доступ:
sudo ufw allow ‘Apache Full’
Убедитесь, что правила брандмауэра действуют:
sudo ufw status
Ожидаемый результат:
Статус: активен
To Action From
— —— —-
Apache Full ALLOW Anywhere
Apache Full (v6) ALLOW Anywhere (v6)
Если UFW настроен правильно, то вы должны иметь возможность получить доступ к целевой странице Apache в своем веб-браузере, используя IP-адрес сервера:
В эпоху Больших Данных резко возросла потребность в эффективной работе с гетерогенными массивами данных, включающей такие задачи, как структурирование, хранение и использование информации. Хотя электронные таблицы и текстовые редакторы являются удобными инструментами, они зачастую не обеспечивают достаточной скорости выполнения задач и не обладают необходимой отказоустойчивостью для эффективного управления Большими Данными. В качестве решения для организации табличных данных появляется система управления базами данных (СУБД) MySQL, использующая декларативный подход к формированию запросов.
При использовании MySQL пользователь избавлен от необходимости разбираться в тонкостях методов поиска данных. Вместо этого они могут формулировать запросы на человекоподобном языке для получения нужной информации. Важнейшую роль в эффективном управлении этой системой играет язык программирования SQL.
Создать или удалить
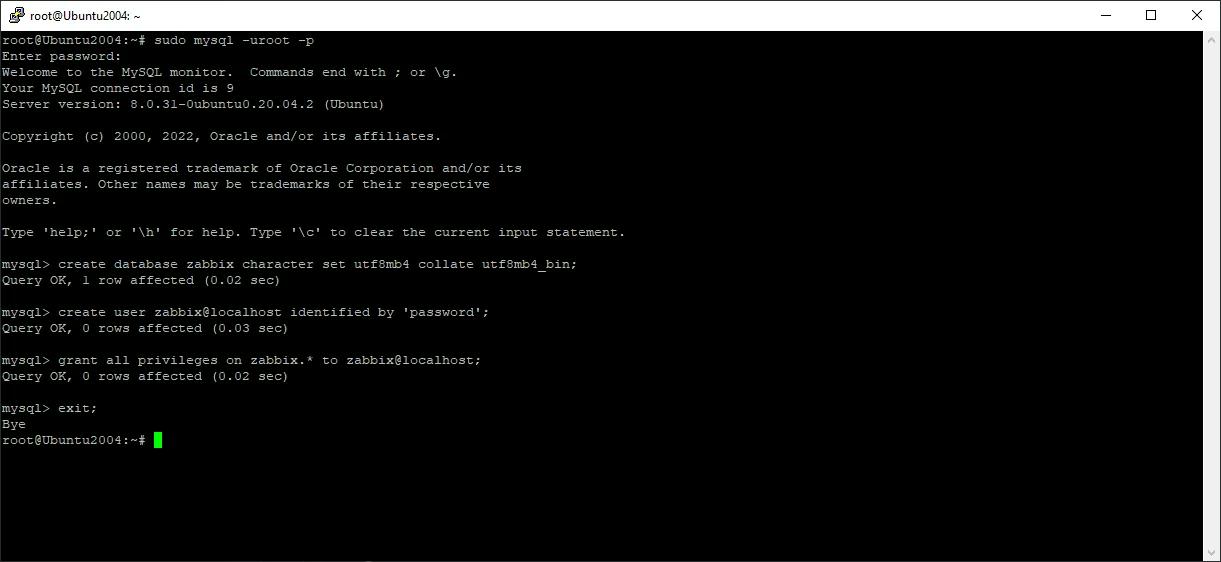
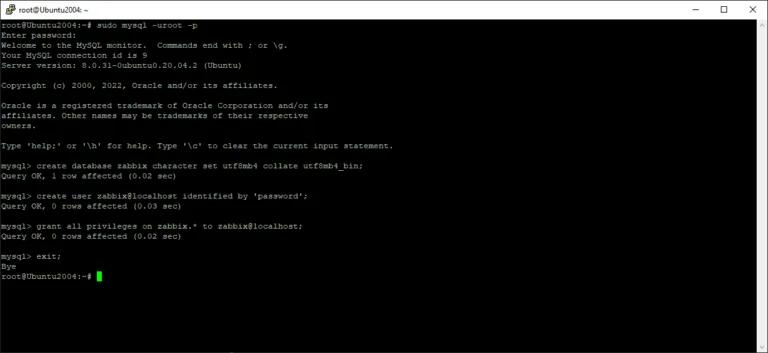
При работе с MySQL, особенно если он установлен как программа управления базами данных, а пользователь обладает правами администратора, первым шагом является получение доступа к системе MySQL. Это можно сделать, выполнив следующую команду:
mysql -u root -p -h localhost
Создайте базу данных командой ниже, затем нам нужно проверить, была ли она создана?
CREATE database product;
SHOW DATABASES;
Как видно, регистр букв может быть как прописным, так и строчным, хотя это различие относится только к синтаксическим командам. Создание нашей базы данных не представляет собой ничего сложного, как показано в таблице выше. Поясним синтаксис: «CREATE» служит командой для создания базы данных, «DATABASE» обозначает тип базы данных, а «product» — это просто метка для базы данных.
Для удаления нужная команда может быть выполнена следующим образом:
DROP DATABASE product;
SHOW DATABASES;
Как видно, наша база данных успешно удалена с помощью этой команды. Однако может возникнуть ошибка, свидетельствующая об отсутствии доступа к объекту. В этом случае необходимо обратиться к администратору и запросить необходимые права доступа к базе данных с помощью следующей команды:
GRANT ALL on *.* to ‘your_user_name’@’domain_name’;
Вывод
В эпоху больших данных эффективная обработка, хранение, контроль, обновление и использование огромных наборов данных в режиме реального времени стали обязательными. Традиционным инструментам, таким как текстовые редакторы или базовые электронные таблицы, не хватает скорости и отказоустойчивости, необходимых для обработки обширных массивов данных. В ответ на эту проблему система управления базами данных MySQL (СУБД) стала надежным решением для управления таблицами.
MySQL использует декларативный подход к запросам данных, позволяя пользователям выражать свои требования на языке, напоминающем человеческую речь, чему способствует стандартизированный язык программирования SQL. Такой подход не только обеспечивает целостность и надежность данных, но также способствует удобству взаимодействия с обширными наборами данных и извлечения информации из них.
Настройка прокси-сервера
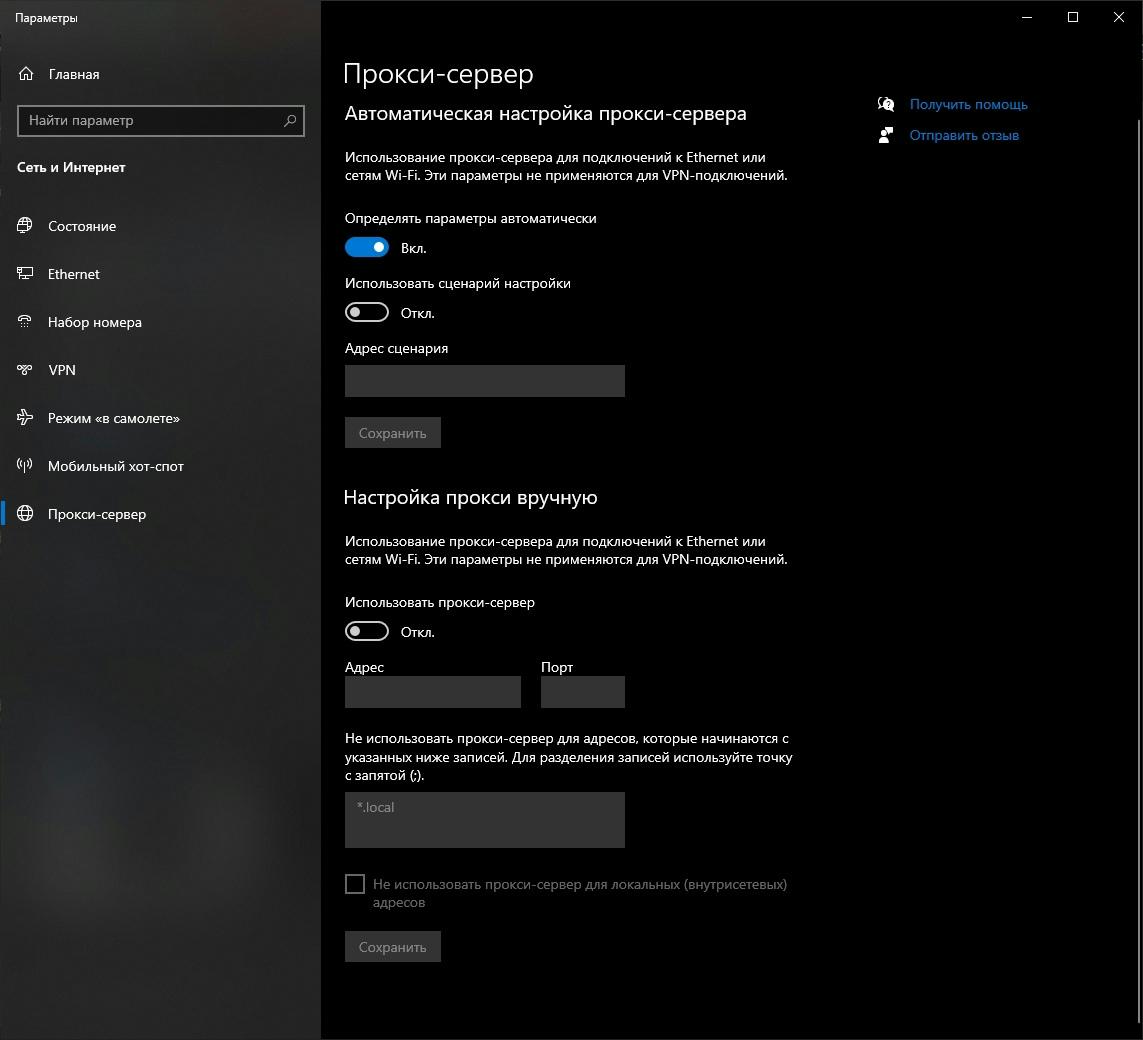
Прокси-сервер на Windows
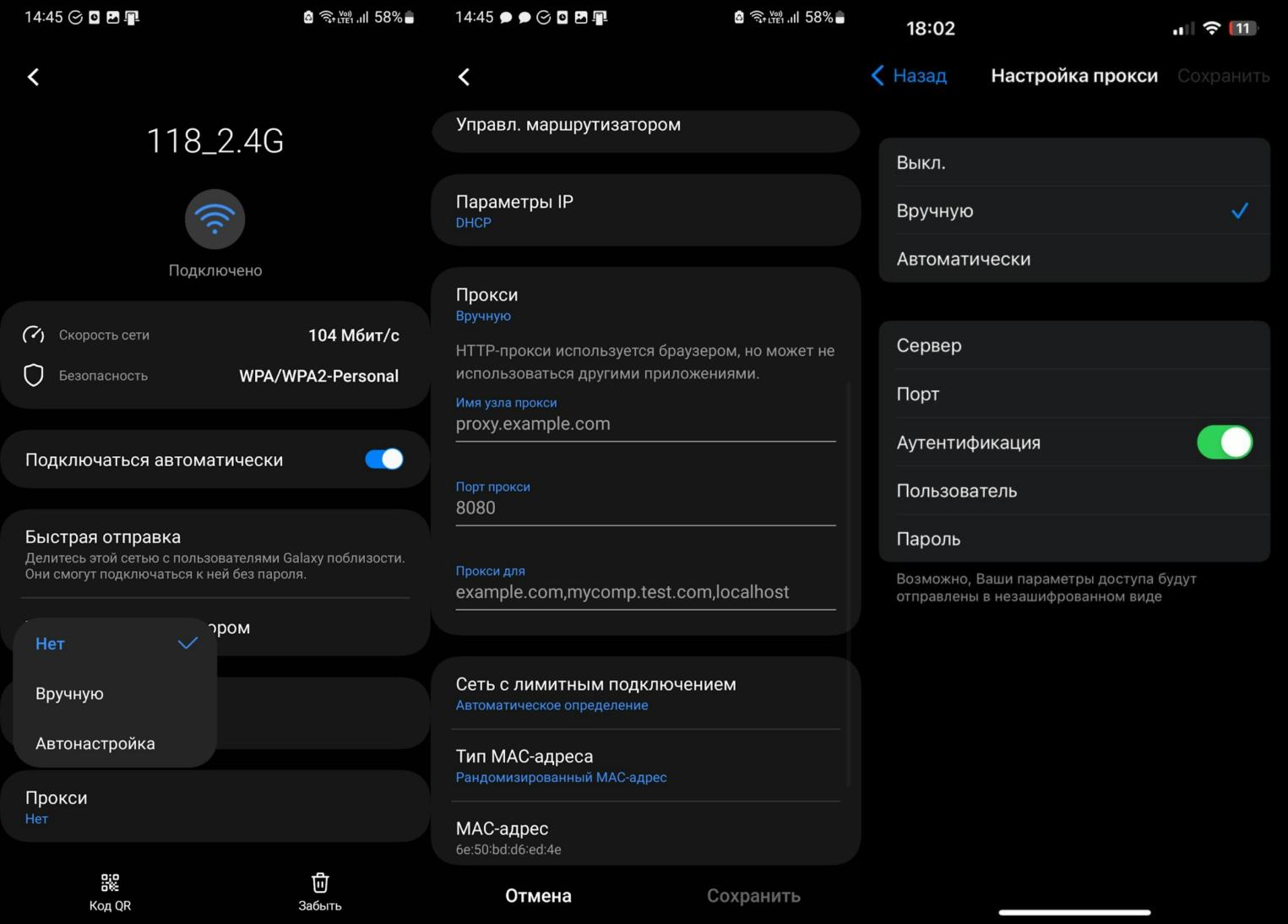
Для конфигурации Windows начните процесс с поиска «Proxy» в строке поиска или перейдите в раздел Настройки → Сеть и Интернет → Proxy Server.
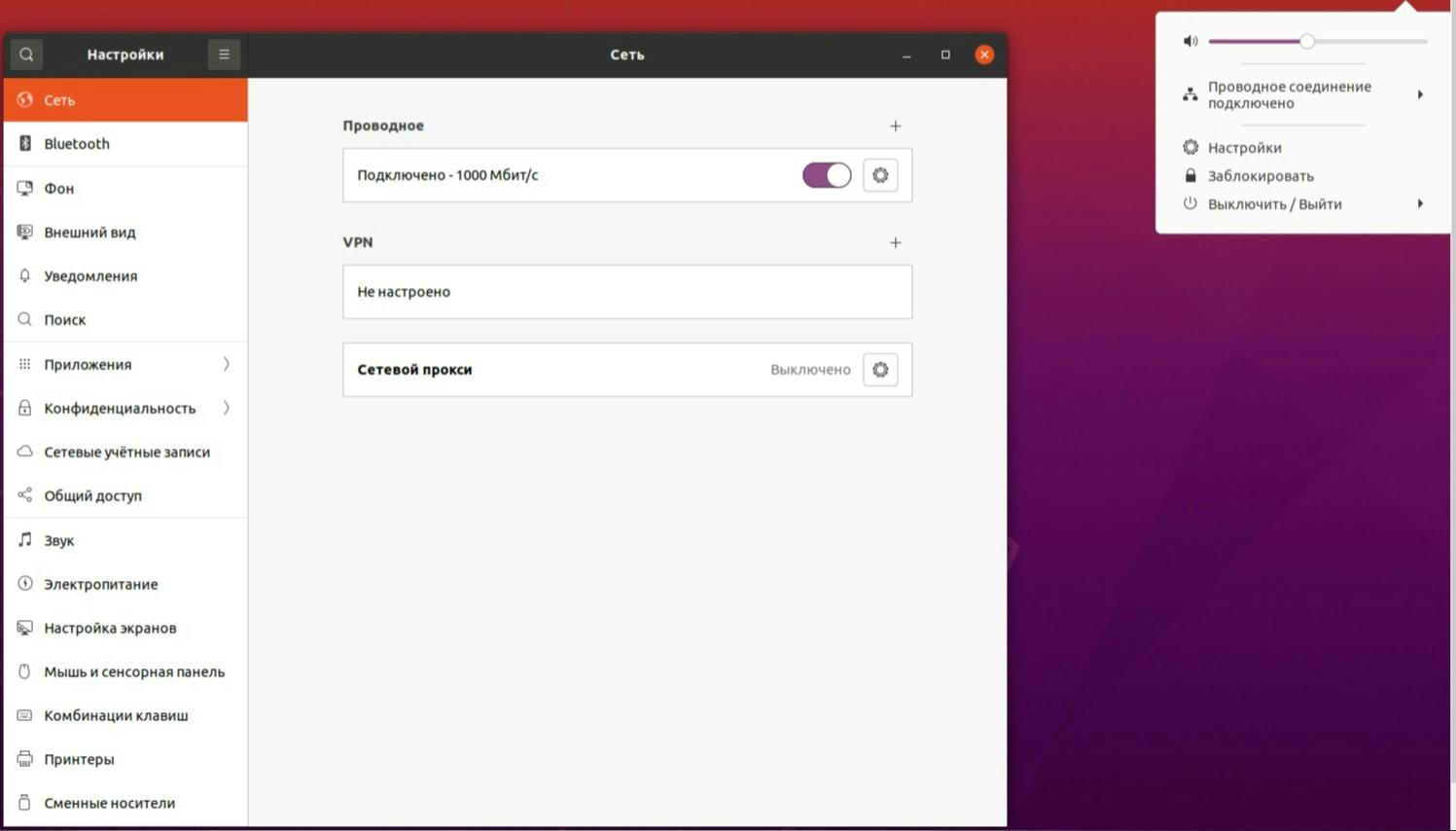
Для Linux
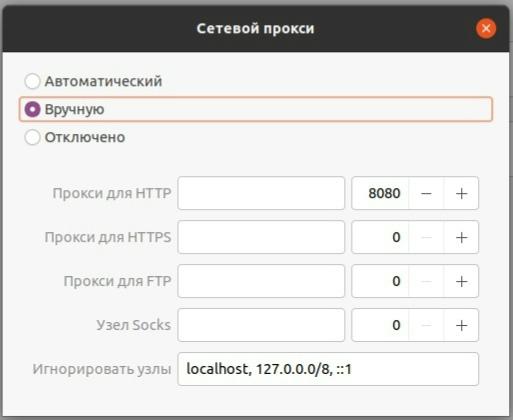
Чтобы настроить прокси-сервер в Linux, зайдите в раздел «Настройки» и выберите значок шестеренки рядом с пунктом «Сетевой прокси».
Важно отметить, что установка логина и пароля для подключения не является простым процессом. Для этого выполните следующие действия:
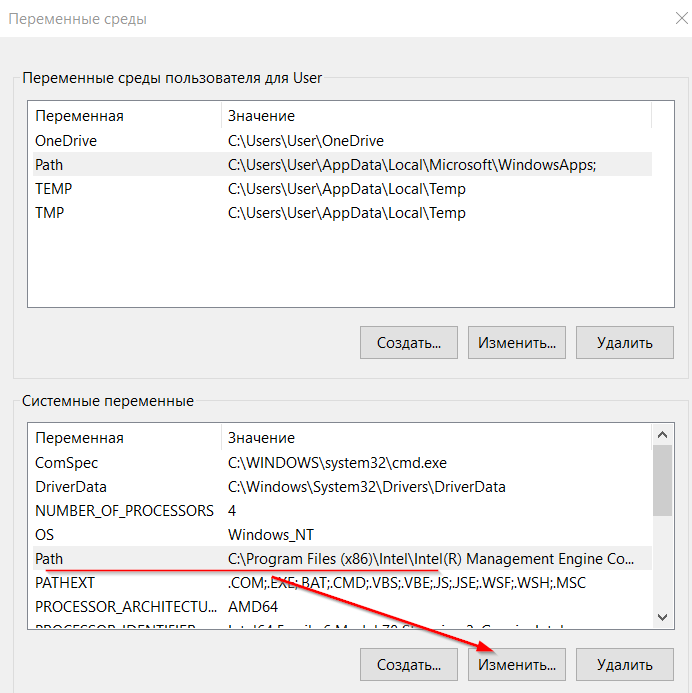
Откройте файл /etc/environment для редактирования, выполнив команду sudo nano /etc/environment.
Перейдите в конец файла и включите в него строки, аналогичные следующим:
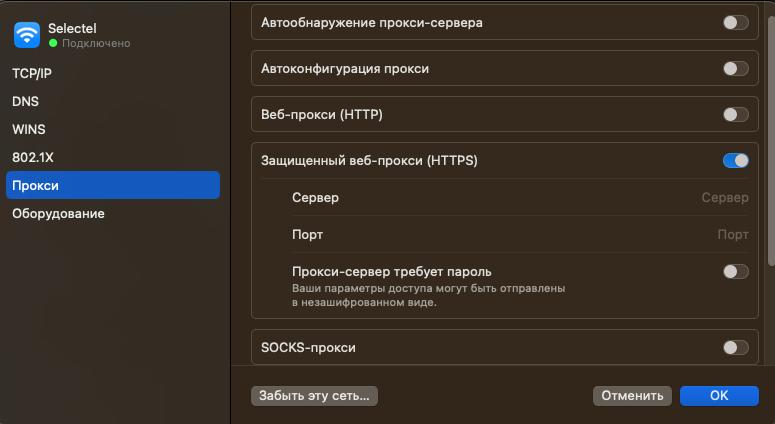
Чтобы настроить прокси-сервер на macOS, запустите Safari и перейдите в раздел «Параметры». После того, как вы открыли панель с выбором параметров конфигурации выберите Дополнения и начните изменение настроек.
Также можно получить доступ к настройкам прокси-сервера, нажав на значок Wi-Fi или Интернета, а затем выбрав пункт Настройки Wi-Fi.
Выберите текущую подключенную сеть и нажмите кнопку Подробности. Затем перейдите на вкладку Прокси-сервер. В этом разделе выберите нужный тип прокси-сервера и введите указанные IP-адрес и порт. При необходимости укажите учетные данные для входа в систему.
Настройка сервера прокси в браузере
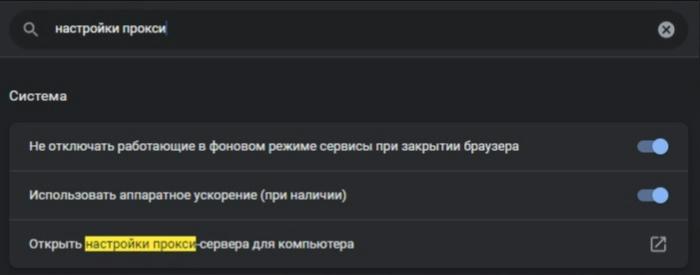
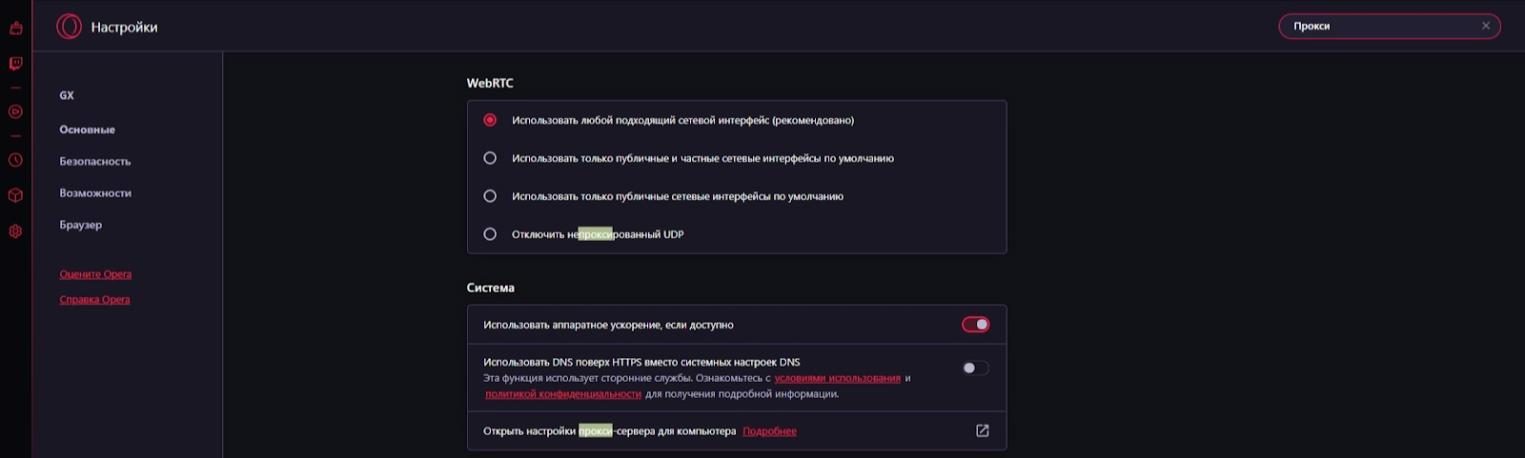
Чтобы настроить прокси-сервера в браузере не нужно использовать иные методы. В Google Chrome -> Настройки, ввести в строке поиска «Proxy». Далее выбрать «Открыть настройки прокси-сервера для компьютера», после чего браузер направит вас к настройкам прокси для вашей операционной системы.
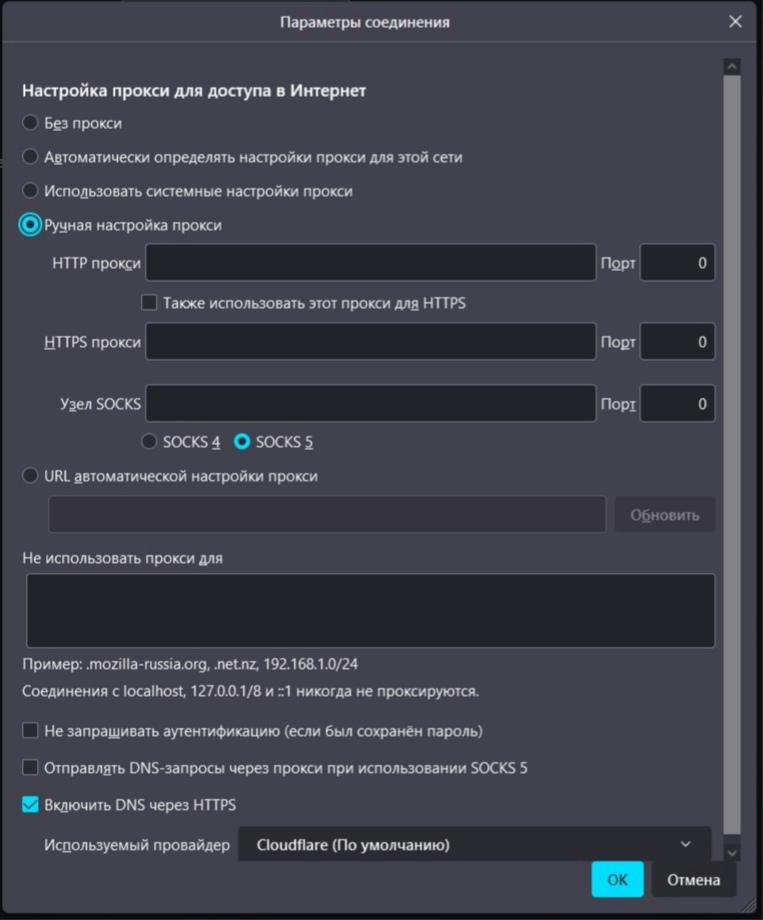
В Mozilla Firefox в строке поиска в меню настроек введите «Настройки сети». Этот пункт откроет доступ к настройкам соединения.
Пользователи браузера Opera могут настроить параметры прокси-сервера, набрав в строке поиска «Proxy» и выбрав пункт «Открыть настройки прокси-сервера для компьютера». Для Microsoft Edge процесс аналогичен:
Аналогичный процесс и для браузера Microsoft Edge:
Настройка прокси-сервера для телефонов или планшетов на Android и iOS
Для начала вам необходимо получить доступ в панель управления настройками. После этого выберите пункт «Подключения»; название раздела может отличаться на Android в зависимости от оболочки, в то время как на iOS он обозначен как Wi-Fi. В ручном режиме установите настройки конфигурации прокси.
Чтобы отключить прокси, просто выполните все действия в обратном порядке. Вернитесь либо к настройкам браузера, либо к системным настройкам. Если вы собираетесь настроить прокси на маршрутизаторе, то универсального решения не существует. Процесс будет зависеть от конкретной модели устройства, хотя общий алгоритм будет напоминать настройку на других системах.
Заключение
Прокси-сервер может быть полезен в тех случаях, когда пользователь стремится к частичной анонимности или хочет получить доступ к контенту, доступ к которому закрыт в определенном государстве. Компании могут использовать его для ограничения доступа сотрудников к социальным сетям, фильтрации нежелательного трафика и укрепления сетевого периметра.
Однако при выборе бесплатных или непроверенных решений очень важно соблюдать протоколы безопасности. Пользователи должны быть готовы к тому, что их запросы и сопутствующая информация могут стать достоянием общественности.
Cloud-init
Cloud-init представляет собой комплекс сценариев, направленных на применение пользовательских данных к экземплярам виртуальных машин. Этот инструмент находит применение в различных операционных системах, включая Linux и FreeBSD, и функционирует на различных приватных и облачных платформах.
У каждого облачного провайдера, будь то публичный или частный, имеется служба метаданных, содержащая информацию об окружении, в котором функционирует виртуальная машина. Образы операционных систем в облачных средах строятся на основе экземпляров, где каждый последующий является клоном предыдущего. Эти экземпляры индивидуализируются пользовательскими данными.
Функции:
Настройка сетевых интерфейсов;
Настройка разрешения имен сети;
Настройка временных точек монтирования;
Установка хостнейма;
Установка SSH-ключей для аутентификации отдельных пользователей;
Установка паролей пользователей;
Принцип работы
Cloud-init получает информацию о необходимых модификациях из источников данных. Метод извлечения метаданных во время загрузки определяется конкретными источниками данных, которые по умолчанию обнаруживаются автоматически.
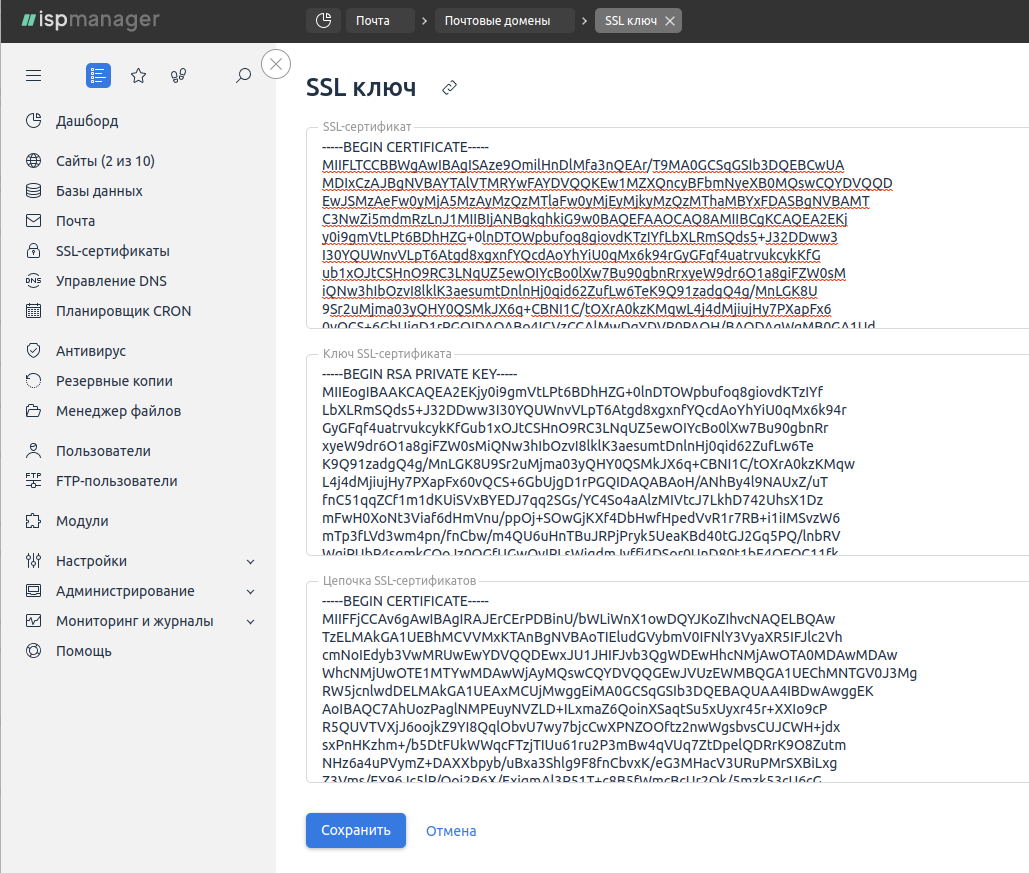
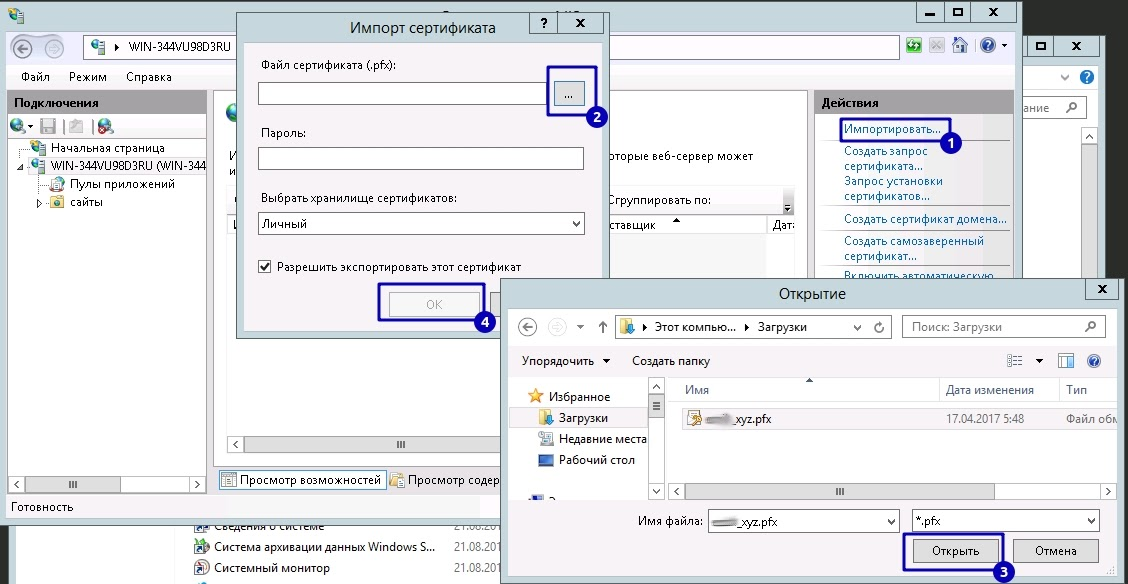
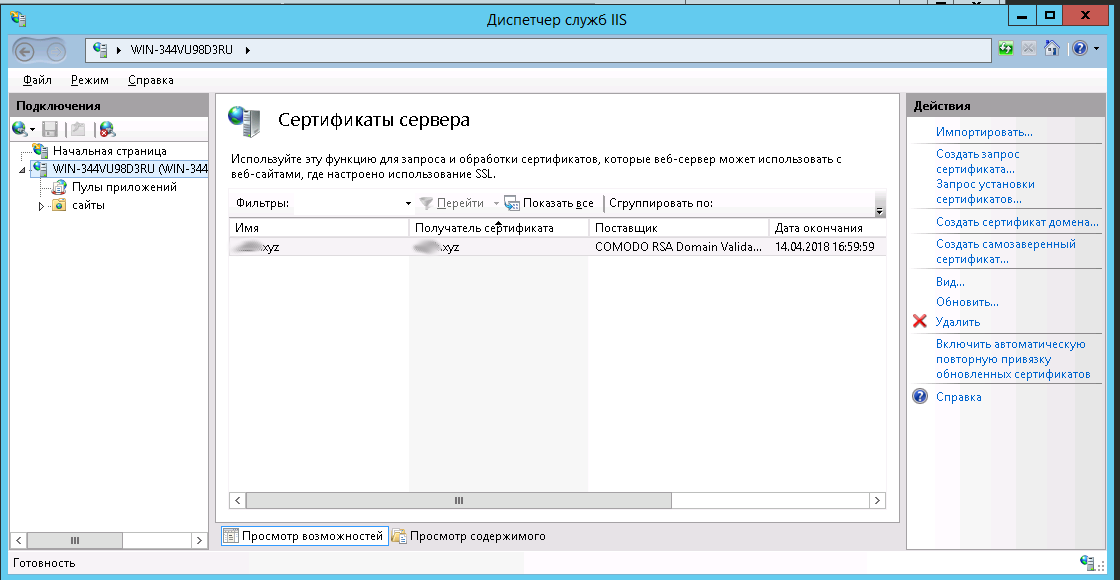
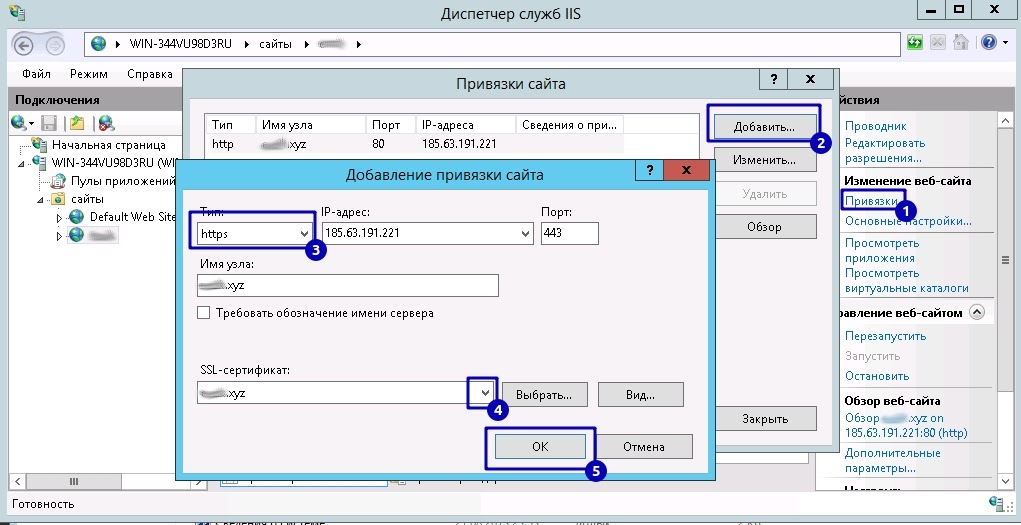
Как защитить корпоративную почту
RTP-запись для почтовых серверов
RTP/Pointer(англ. “указатель”) – ресурсная запись(или DNS-запись, с помощью которых можно внести служебную информацию о сервере), которая IP-адрес сервера связывает с доменом.
Оно защищает пользователей от спама. Почтовые службы проверяют, соответствует ли IP-адрес сервера настоящему домену компании. Все подозрительные письма отправляются в спам.
SPF-запись от фишинга
SPF(“Sender Policy Framework” с англ. “структура политики отправителя”) – ресурсная запись, которая находится внутри другой TXT-записи. Это код, точнее – список доверенных IP, с помощью которых можно отправлять письма от имени домена.
Злоумышленники могут создавать письма, которые кажутся отправленными от известных компаний и могут напоминать фирменные письма. Для создания видимости подлинности они могут использовать поддельные адреса электронной почты или логотипы компаний. Такие письма могут содержать ссылки, направляющие пользователей на поддельные сайты или автоматически заставляющие их загружать вредоносное ПО. Если пользователь переходит по этим ссылкам или загружает файлы, злоумышленник получает доступ к данным, которые затем может использовать в своих целях
Механизмы шифрования SMPT
SMPT(“Simple Mail Transfer Protocol” с англ. “простой протокол передачи почты”) – протокол, который отвечает за отправку писем.
Перед отправкой электронного письма SMTP-сервер выполняет несколько задач. Он проверяет настройки на компьютере отправителя и устанавливает соединение с почтовым сервером получателя. Если настройки верны, письмо отправляется, и протокол подтверждает его доставку. В случае ошибки сервер выдает уведомление. Основные задачи SMTP-сервера-проверка параметров передачи, проверка на спам.
Email-аутентификации DKIM
DKIM – цифровая подпись для писем. Благодаря ему можно снизить вероятность попадания письма вашей компании в спам и обезопасить себя от фишинга.
Перед отправкой электронного письма сервер выполняет несколько задач. Он проверяет настройки на компьютере отправителя и устанавливает соединение с сервером электронной почты получателя. Если настройки верны, письмо отправляется, и протокол подтверждает его доставку. При возникновении ошибки сервер выдает уведомление об ошибке. Основными задачами сервера являются проверка параметров передачи, проверка на спам, улучшение доставляемости письма с помощью фильтров, подтверждение доставки и отправка уведомлений о бошибках. При этом протокол посылает команды, чтобы понять причину недоставки письма.
Технология DKIM использует ключи шифрования для обеспечения безопасности и подлинности электронных писем. Публичный ключ добавляется в DNS записи и известен всем серверам. Закрытый ключ известен только серверу отправителя. При отправке каждое письмо получает зашифрованную надпись с информацией о времени отправки и получателе. Эту информацию сервер получателя расшифровывает с помощью публичного ключа. Если ключи и цифровая подпись верные, письмо будет доставлено. Если обнаружена ошибка в ключе или подписи, письмо будет отмечено как спам.
Черные и белые списки адресов
В большинстве почтовых сервисов есть возможность настроить списки доверенных и сомнительных отправителей и получателей. В белый список включаются адреса, которым вы полностью доверяете. Письма от этих отправителей всегда будут доставляться в основной почтовый ящик, а не попадут в папку со спамом. Адреса из черного списка, напротив, считаются сомнительными, поэтому письма от них автоматически помещаются в папку со спамом или могут быть вовсе отклонены.
Смена пароля раз в полгода
Каждый работник в компании должен иметь индивидуальный сложный пароль, который ему следует менять раз в полгода. Так риск получения злоумышленниками корпоративной почты станет меньше в несколько раз.
Отказ от бесплатных сервисов
Бесплатные почтовые сервисы предоставляют простоту использования, но важно понимать, что ваша почта на самом деле находится на сервере другой компании, и вы не имеете полного контроля над ней. Кроме того, у таких сервисов низкий уровень безопасности, и возможны сбои в их работе. В отличие от этого, использование собственной корпоративной почты имеет ряд преимуществ:
Повышается доверие клиентов: наличие собственной почты положительно влияет на лояльность клиентов, увеличивает доверие и вероятность открытия письма.
Лучшая запоминаемость бренда: использование собственного домена в адресе электронной почты помогает лучше запомнить ваш бренд.
Снижается вероятность попадания в спам: отправка писем с собственной почты уменьшает шансы на то, что они будут отфильтрованы как спам.
Упрощение коммуникации с клиентами: вы можете настроить приветственные рассылки и полезные письма для знакомства с вашей компанией, что упрощает взаимодействие с клиентами.
Создание рабочей почтовой среды для сотрудников: использование собственной корпоративной почты позволяет сотрудникам разделять личную и рабочую переписку, что удобно и эффективно.
Обучение сотрудников правилам безопасности
Использование собственной корпоративной почты имеет множество преимуществ. Она повышает доверие клиентов, улучшает запоминаемость бренда и упрощает коммуникацию с клиентами. Кроме того, она уменьшает вероятность попадания в спам и создает рабочую почтовую среду для сотрудников. Однако, безопасность корпоративной почты зависит от каждого сотрудника. Поэтому важно проводить обучение и рассказывать о правилах безопасности, таких как не отвечать на подозрительные письма, не переходить по ссылкам внутри писем и не скачивать файлы из рассылок неизвестных отправителей, следить за обновлением антивируса, не использовать корпоративную почту на личных устройствах и не подключаться к публичным Wi-Fi-сетям при использовании корпоративной почты.
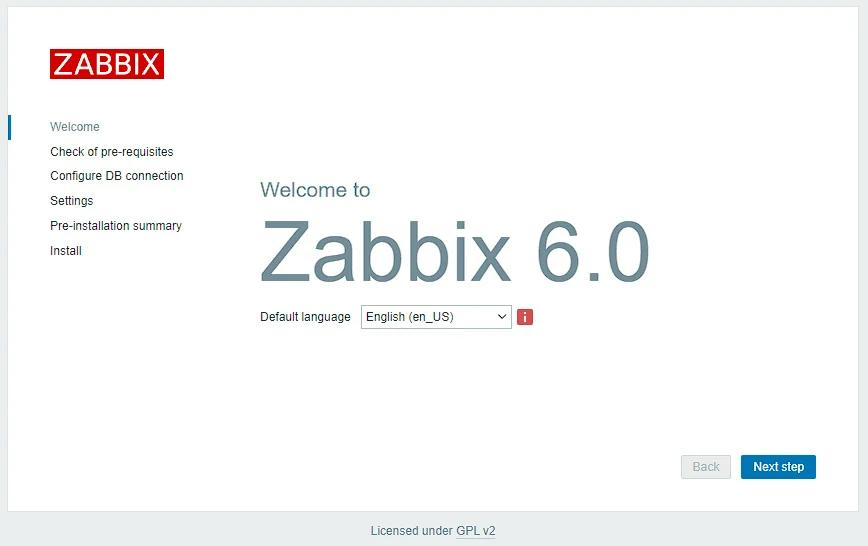
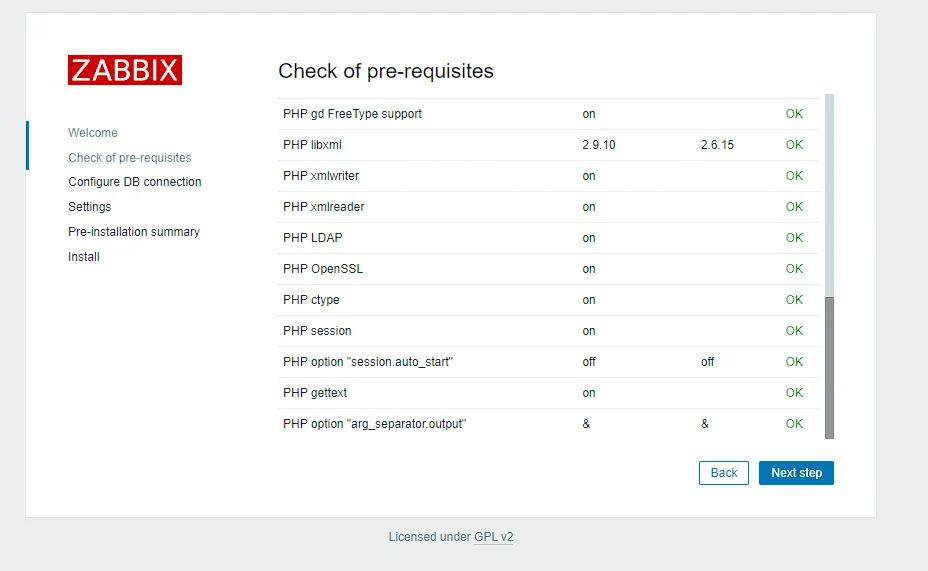
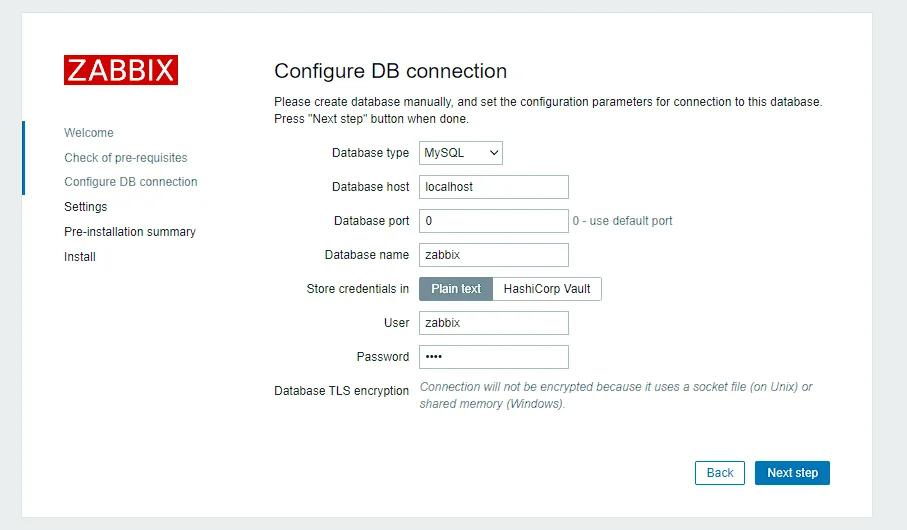
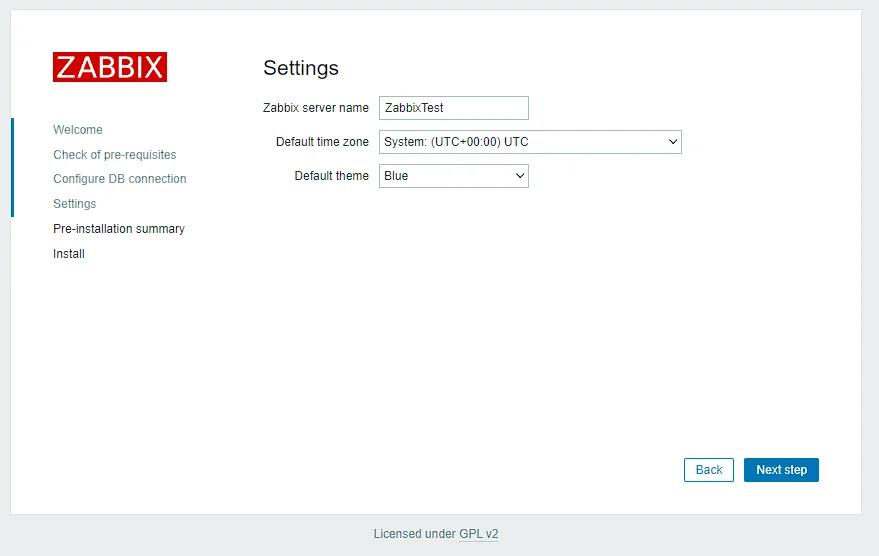
Установка NextCloud на Ubuntu 20.10
Nextcloud — это мощная платформа для синхронизации и обмена файлами. Ниже приводится пошаговое руководство по установке Nextcloud на Ubuntu 20.10.
Шаг 1: Обновление и модернизация системных пакетов
Перед началом работы убедитесь, что система обновлена:
sudo apt update
sudo apt upgrade
Шаг 2: Установка необходимых пакетов
Установите необходимые пакеты, включая Apache, MariaDB (или MySQL), PHP и другие необходимые инструменты:
Перейдите к настройкам Nextcloud, чтобы настроить уведомления по электронной почте, внешнее хранилище и другие параметры.
Как установить и настроить Active Directory
Установка и настройка Active Directory (AD) предполагает создание централизованной системы аутентификации и управления для сетей на базе Windows. Здесь представлено полное пошаговое руководство по установке и настройке Active Directory.
Шаг 1: Подготовка среды
Убедитесь, что ваш сервер соответствует требованиям к аппаратному и программному обеспечению Windows Server, необходимому для работы AD. Установите статический IP-адрес для сервера, поскольку AD требует согласованной конфигурации сети.
Шаг 2: Установка доменных служб Active Directory
Установите Windows Server на выбранную вами машину.
После установки откройте Server Manager на панели задач.
Нажмите на «Управление» в правом верхнем углу, затем выберите «Добавить роли и возможности».
Пройдите через мастер, выбирая значения по умолчанию, пока не перейдете на страницу «Выбор ролей сервера».
Отметьте «Active Directory Domain Services» и следуйте подсказкам для установки.
Шаг 3: Преобразование сервера в контроллер домена
В диспетчере серверов нажмите «Перевести этот сервер в контроллер домена».
Выберите «Добавить новый лес» и укажите имя корневого домена.
Установите пароль режима восстановления служб каталогов (DSRM).
Выберите функциональные уровни домена и леса.
Настройте параметры DNS и следуйте подсказкам для завершения установки.
Шаг 4: Настройка параметров Active Directory
Откройте «Active Directory Users and Computers» из Administrative Tools.
Создайте организационные единицы (OU) для организации пользователей и компьютеров.
Используйте «Active Directory Sites and Services» для настройки репликации и топологии сайтов.
Откройте «Управление групповыми политиками» для создания и управления групповыми политиками.
Шаг 5: Дополнительная конфигурация
Убедитесь, что DNS правильно настроен, поскольку AD в значительной степени полагается на DNS для разрешения имен.
Установите Trust Relationships, если у вас несколько доменов или лесов.
Создайте план резервного копирования и восстановления Active Directory, включая резервное копирование состояния системы.
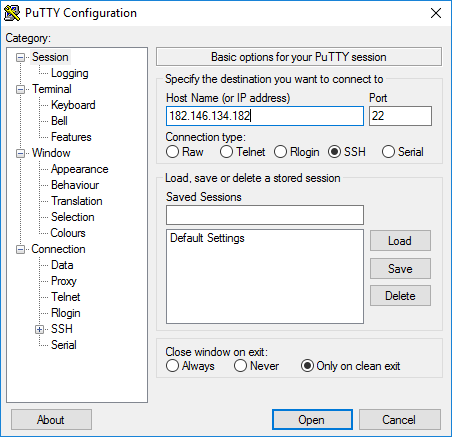
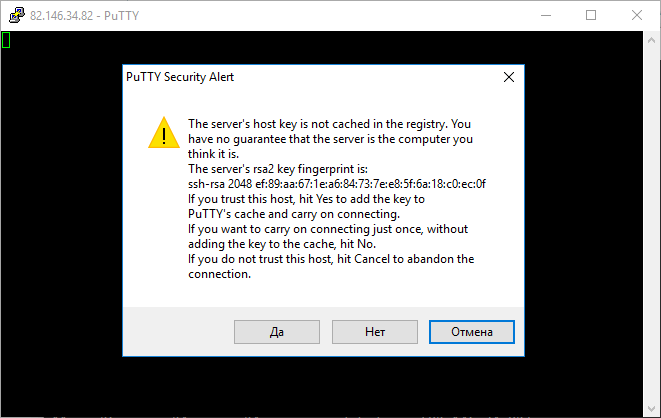
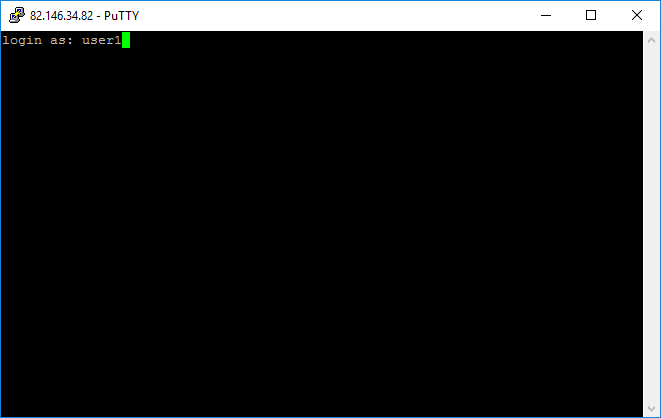
SSH туннель: как создать и использовать?
SSH-туннель — это безопасный способ установления соединения между локальной и удаленной машинами, позволяющий направлять сетевой трафик по зашифрованному каналу. Это может быть полезно для безопасного доступа к удаленным службам, обхода сетевых ограничений или повышения уровня конфиденциальности. Ниже приводится пошаговое руководство по созданию и использованию туннеля SSH.
Шаг 1: Понимание туннелей SSH
Существует три типа туннелей SSH, которые можно использовать:
Локальная переадресация портов. Перенаправляет трафик с локального порта на удаленный сервер через SSH-соединение. Применяется для доступа к службам удаленного сервера, которые в противном случае недоступны из-за ограничений брандмауэра или системы безопасности.
Переадресация удаленного порта: Перенаправляет трафик с удаленного сервера на локальную машину через SSH-соединение. Применяется в тех случаях, когда необходимо открыть локальную службу для доступа к сети удаленного сервера.
Динамическая переадресация портов (SSH SOCKS Proxy). Создает туннель динамической переадресации портов, позволяющий направлять весь сетевой трафик через удаленный сервер. Это может быть использовано для повышения уровня конфиденциальности или обхода сетевых ограничений.
Шаг 2: Создание туннеля SSH
Если у вас есть SSH-доступ к удаленному серверу, то вот как создать эти типы туннелей.
После создания туннеля вы можете использовать его для безопасного доступа к удаленным сервисам или для маршрутизации сетевого трафика.
Локальная переадресация портов — откройте веб-браузер и перейдите по адресу http://localhost:local_port. Трафик будет безопасно туннелироваться на удаленный сервер и далее на указанный remote_port.
Переадресация удаленного порта — на удаленном сервере можно получить доступ к локальной службе, подключившись к http://localhost:remote_port.
Динамическая переадресация портов — настройте свои приложения (например, веб-браузеры) на использование SOCKS-прокси по адресу localhost:local_port. Это позволит направлять весь сетевой трафик через удаленный сервер.
Шаг 4: Закрытие SSH-туннеля
Чтобы закрыть SSH-туннель, просто прервите SSH-соединение, нажав Ctrl+C в терминале, в котором был создан туннель.
Создание и настройка .htaccess
.htaccess — это конфигурационный файл, используемый веб-сервером Apache для управления различными настройками и поведением определенного каталога и его подкаталогов. Это мощный инструмент для настройки таких параметров, как переписывание URL, управление доступом и другими. Ниже приведено руководство по созданию и настройке файла .htaccess.
Шаг 1: Создание файла .htaccess
Откройте текстовый редактор, например Nano или Vim, или воспользуйтесь графическим редактором, например Gedit.
Создайте новый файл с именем .htaccess (обратите внимание на ведущую точку) в каталоге, где будут действовать его правила. Это может быть корневой каталог вашего сайта или любой подкаталог.
Шаг 2: Добавьте правила в .htaccess
Несколько распространенных вариантов использования файла .htaccess.
Включение переписывания URL:
Переписывание URL позволяет манипулировать URL-адресами и делать их более удобными для пользователей или SEO. Например, можно преобразовать example.com/page.php?id=123 в example.com/page/123.
Для включения функции перезаписи URL-адресов, необходимо включить модуль mod_rewrite в Apache и включить правила в файл .htaccess. Пример правила:
RewriteEngine On
RewriteRule ^page/([0-9]+)$ page.php?id=$1 [L]
Блокировка доступа к файлам или каталогам:
С помощью .htaccess можно ограничить доступ к определенным файлам или каталогам. Например, чтобы запретить доступ к определенному файлу:
<Files «sensitive-file.txt»>
Order allow,deny
Deny from all
</Files>
Настройка пользовательских страниц ошибок:
Вы можете создавать пользовательские страницы ошибок для различных кодов ошибок HTTP. Например, чтобы задать пользовательскую страницу ошибки 404 (Not Found):
ErrorDocument 404 /404.html
Защита каталогов паролем:
С помощью .htaccess можно защитить каталоги паролем. Сначала создайте файл .htpasswd, содержащий комбинации имени пользователя и пароля. Затем добавьте в файл .htaccess следующее:
AuthType Basic
AuthName «Restricted Area»
AuthUserFile /path/to/.htpasswd
Require valid-user
Примечание: Обязательно замените /path/to/.htpasswd на реальный путь к файлу .htpasswd.
Шаг 3: Сохранить и протестировать
После добавления необходимых правил сохраните файл .htaccess. Убедитесь, что в имени файла нет дополнительных расширений.
Чтобы протестировать правила, зайдите на свой сайт и посмотрите, выполняется ли ожидаемое поведение. Если возникли ошибки, просмотрите файл .htaccess на предмет опечаток или неправильной конфигурации.
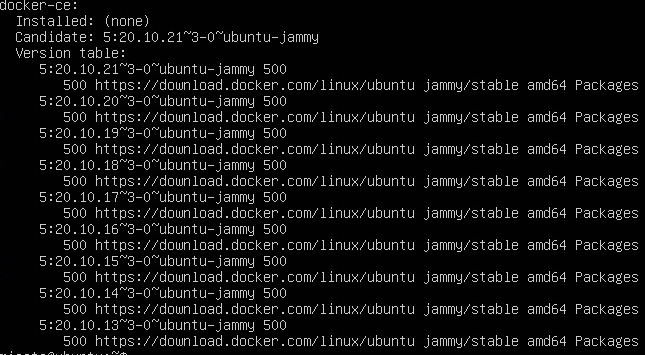
Установка Docker на Ubuntu 20.04
Docker — это мощная платформа, позволяющая контейнеризировать приложения и последовательно развертывать их в различных средах. Приводим пошаговое руководство по установке Docker на Ubuntu 20.04.
Шаг 1: Обновление репозитория пакетов
Перед установкой Docker рекомендуется обновить репозиторий пакетов, чтобы убедиться в наличии актуальной информации о доступных пакетах. Откройте терминал на машине Ubuntu и выполните команды:
sudo apt update
Шаг 2: Установка необходимых зависимостей
Для работы Docker требуются некоторые предварительные компоненты, которые можно установить с помощью следующей команды:
После добавления репозитория можно установить Docker:
sudo apt update
sudo apt install docker-ce
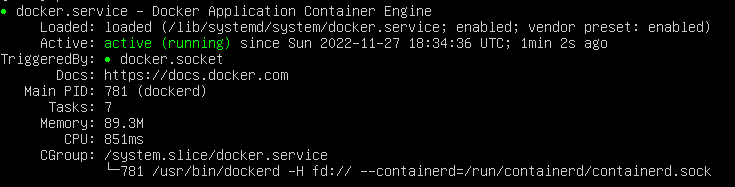
Шаг 5: Запуск и включение Docker
После установки Docker запустите службу Docker и включите ее запуск при загрузке:
sudo systemctl start docker
sudo systemctl enable docker
Шаг 6: Проверка установки Docker
Убедиться в успешной установке Docker можно, запустив простой контейнер hello-world:
sudo docker run hello-world
Если все настроено правильно, вы увидите вывод, свидетельствующий о корректной работе Docker.
Шаг 7: Управление Docker от имени не root-пользователя (необязательный пункт)
По умолчанию для работы Docker требуются привилегии root. Однако вы можете добавить своего пользователя в группу «docker», чтобы использовать Docker без sudo:
sudo usermod -aG docker $USER
Не забудьте выйти из системы и снова войти в нее или перезагрузить систему, чтобы изменения в группах вступили в силу.
Docker Swarm
Docker Swarm — это платформа для оркестровки контейнеров, предоставляемая компанией Docker и позволяющая управлять и развертывать контейнеры в масштабе. Она позволяет создавать и управлять кластером узлов Docker, превращая их в единую виртуальную инфраструктуру для запуска и масштабирования приложений.
Оркестровка контейнеров
Оркестровка контейнеров подразумевает управление развертыванием, масштабированием и работой контейнерных приложений. Docker Swarm упрощает этот процесс, предоставляя инструменты для автоматизации и управления этими задачами.
Режим Swarm
Это интегрированное решение для оркестровки контейнеров, которое поставляется вместе с Docker. Вам не нужно устанавливать дополнительное программное обеспечение; режим Swarm активируется по умолчанию при настройке Docker на хост-машинах.
Узлы и кластеры
В Docker Swarm есть два типа сущностей: узлы и кластеры. Узлы — это отдельные экземпляры Docker, кластеры — это группы узлов, которые работают как единое целое для запуска контейнеров и управления ресурсами.
Terraform
Terraform — это инструмент с открытым исходным кодом (IAC), разработанный компанией HashiCorp. Он позволяет декларативно и последовательно определять, управлять и предоставлять инфраструктурные ресурсы, упрощая управление сложной инфраструктурой в среде различных облачных провайдеров и в локальных средах.
Инфраструктура как код (IAC)
Terraform позволяет определять инфраструктуру на языке конфигурации, похожем на код. Этот код описывает желаемое состояние ресурсов инфраструктуры, таких как виртуальные машины, сети, базы данных и т.д., вместо того чтобы вручную настраивать их с помощью пользовательского интерфейса или инструментов командной строки.
Декларативное конфигурирование
Terraform использует декларативный подход, когда вы указываете, как должна выглядеть ваша инфраструктура, а Terraform сам определяет необходимые шаги для достижения этого состояния. Это отличается от императивного подхода, при котором задается точная последовательность команд для создания ресурсов.
Независимость от провайдера
Terraform поддерживает множество облачных провайдеров, а также локальные системы и другие сервисы. Каждый провайдер представлен в виде плагина, что позволяет управлять ресурсами разных провайдеров с помощью одной и той же конфигурации Terraform.
Как настроить CDN
CDN — это географически распределенная сеть серверов, хранящих и доставляющих содержимое сайта пользователям. Она помогает повысить производительность, доступность и масштабируемость сайта за счет кэширования и доставки контента с серверов, расположенных ближе к местоположению пользователя. В подробной инструкции рассказываем, как настроить CDN.
Зарегистрируйте учетную запись
Зарегистрируйте учетную запись у выбранного провайдера CDN. Укажите необходимую информацию и завершите процесс регистрации.
Настройте DNS
Для интеграции CDN с вашим сайтом необходимо настроить параметры DNS. Войдите в систему регистрации доменов или DNS-провайдера и создайте запись CNAME или псевдоним, указывающий на домен или конечную точку провайдера CDN.
Например, можно создать такую запись CNAME:
CNAME cdn.example.com YOUR_CDN_ENDPOINT
Замените cdn.example.com на желаемый поддомен CDN. Замените YOUR_CDN_ENDPOINT на домен или конечную точку CDN-провайдера.
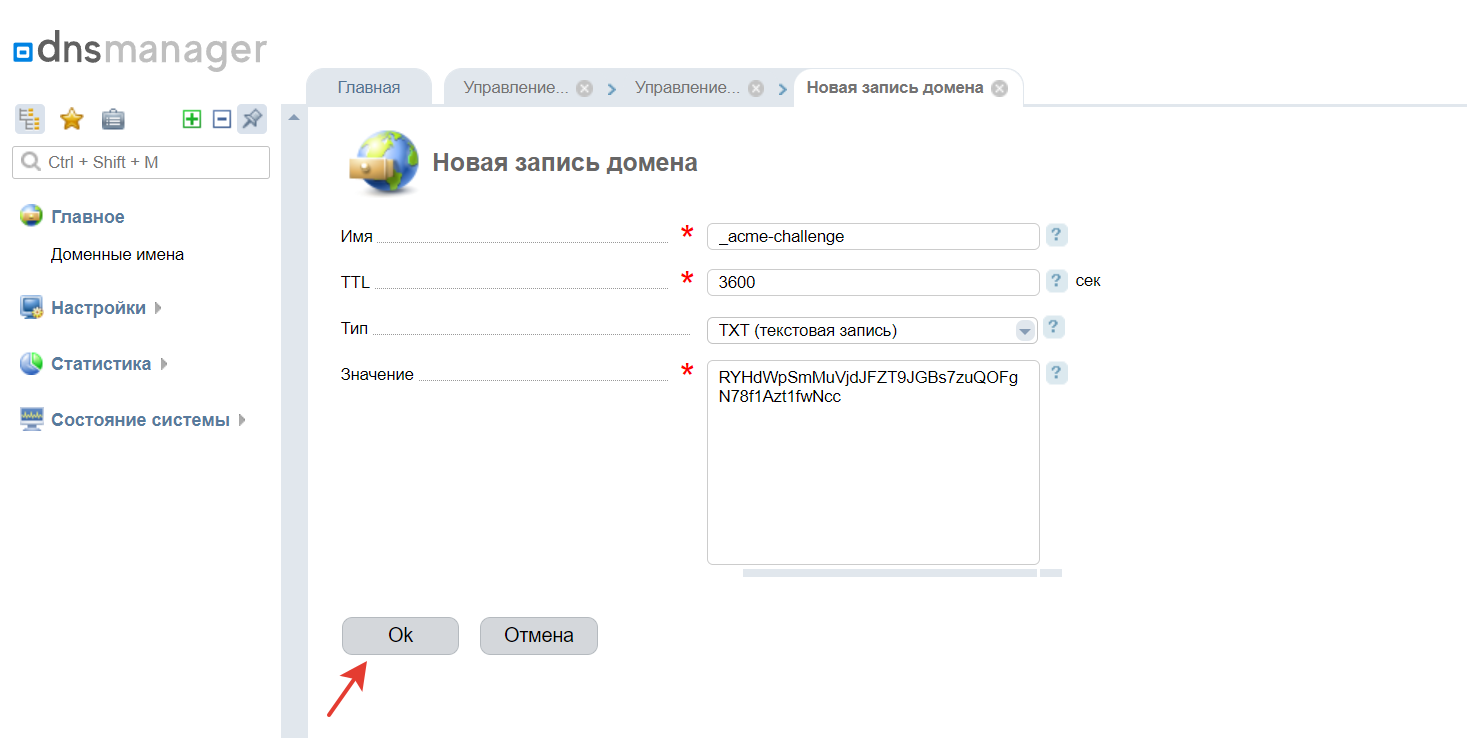
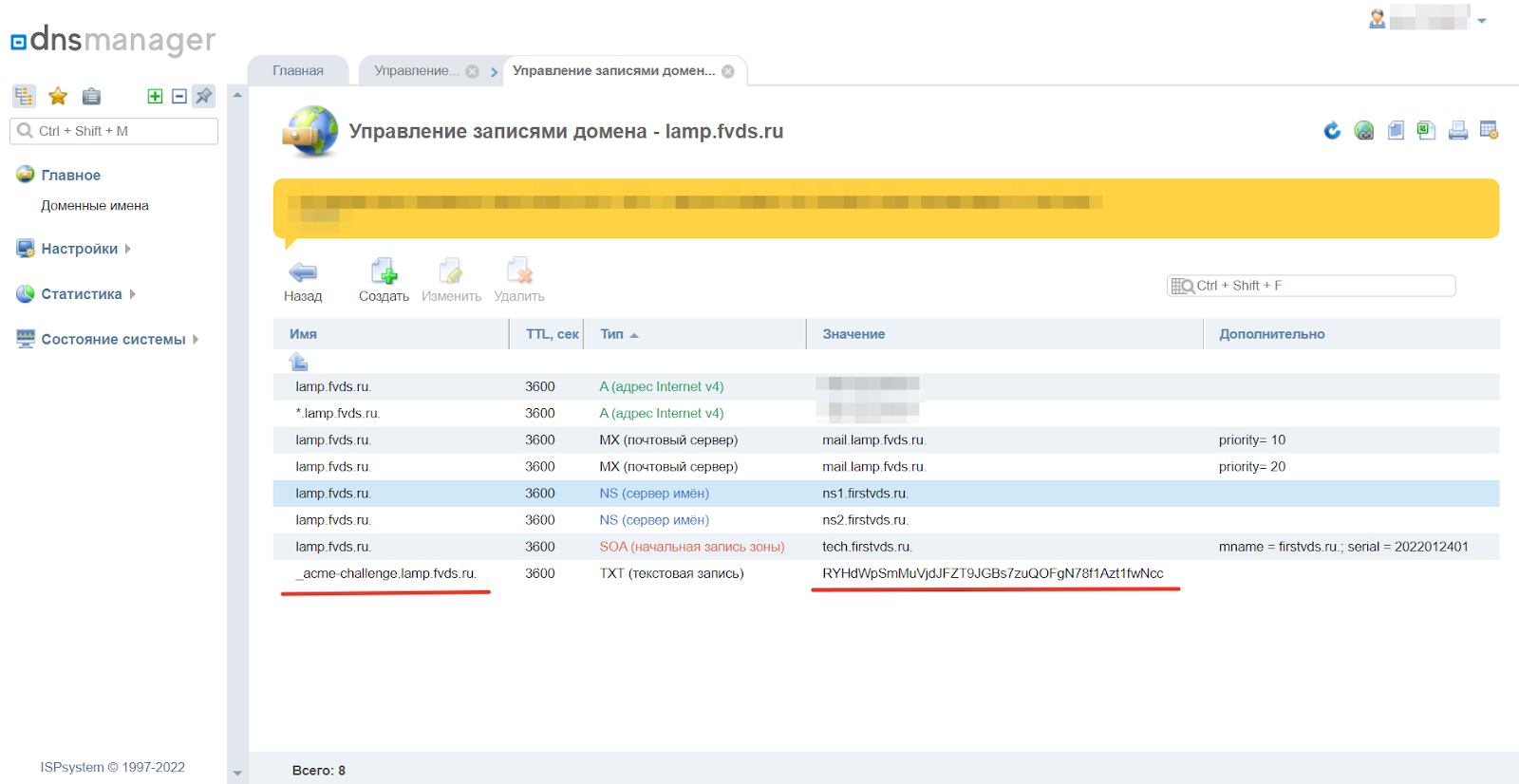
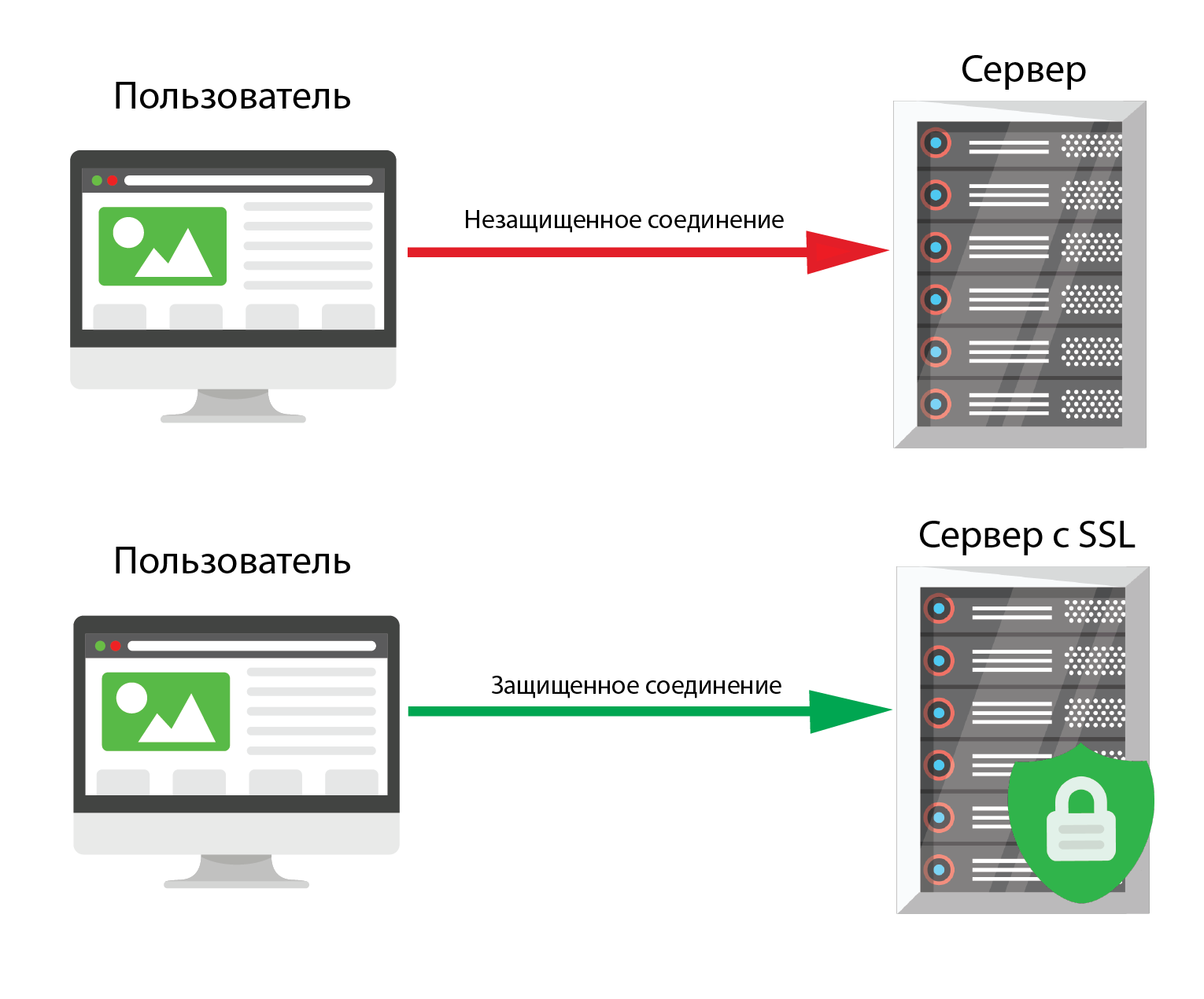
Настройка SSL-сертификата (необязательно)
Если ваш сайт использует протокол HTTPS, вам необходимо установить SSL-сертификат для домена CDN. Многие провайдеры CDN предлагают интегрированные опции SSL. Следуйте инструкциям, предоставленным провайдером CDN, чтобы включить SSL для домена.
Настройка параметров CDN
Войдите в панель управления провайдера CDN. Настройте параметры в соответствии с вашими требованиями. Общие параметры настройки включают в себя поведение кэширования, настройки сервера происхождения, параметры безопасности и другие.
Настройка сервера происхождения
Настройте сервер вашего сайта (исходный сервер) для работы с CDN. Обычно для этого необходимо разрешить доступ с IP-адресов провайдера CDN или настроить имя хоста сервера происхождения в настройках CDN. Инструкции по настройке CDN можно найти в документации или на ресурсах поддержки провайдера CDN.
Тестирование и мониторинг
После настройки CDN тщательно протестируйте свой сайт, чтобы убедиться, что CDN корректно доставляет контент. Следите за производительностью и показателями сайта, чтобы заметить улучшения, достигнутые благодаря CDN. По результатам мониторинга и тестирования внесите необходимые изменения в правила кэширования или настройки.
Мониторинг и оптимизация
Постоянно контролируйте работу CDN и при необходимости проводите оптимизацию. Просматривайте аналитику CDN и отчеты об использовании, предоставляемые провайдером CDN, чтобы выявить возможности для дальнейшего совершенствования.
Следуя шагам из инструкции вы настроите сеть доставки контента. Теперь CDN будет кэшировать и доставлять содержимое вашего сайта с серверов, расположенных ближе к пользователям, что повысит производительность и доступность вашего сайта.
Как защититься от DDoS-атак
DDoS-атака — это попытка перегрузить целевой сервер или сетевую инфраструктуру путем направления на него огромного объема трафика или запросов. Подобный трафик генерируют большое количество ботнетов под управлением злоумышленников. Цель DDoS-атаки — нарушить работу атакуемого объекта и сделать его недоступным для пользователей.
Типы DDoS-атак
Объемные атаки направлены на насыщение пропускной способности сети цели за счет перегрузки ее большим объемом трафика.
TCP/IP-атаки используют уязвимости в стеке протоколов TCP/IP для исчерпания ресурсов сервера, таких как количество доступных соединений или вычислительная мощность.
Атаки на прикладном уровне направлены на конкретные приложения или сервисы, перегружая их легитимными запросами и истощая ресурсы сервера, такие как процессор или память.
Атаки на уровне протоколов используют слабые места в сетевых протоколах, таких как DNS, HTTP или NTP, чтобы нарушить работу служб объекта атаки.
Отраженные/амплифицированные атаки предполагают отправку запросов на общедоступные серверы для переполнения его трафиком, который кажется исходящим от легитимных источников.
Методы защиты
Чтобы защитить себя от DDoS-атак, реализуйте следующие меры.
Установите средства мониторинга сети для обнаружения аномальных моделей трафика и выявления потенциальных атак.
Используйте межсетевые экраны для фильтрации вредоносного трафика и блокировки подозрительных IP-адресов или диапазонов.
Разверните системы предотвращения вторжений (IPS), которые позволяют обнаруживать и предотвращать DDoS-атаки в режиме реального времени, анализируя сетевой трафик и его структуру.
Используйте службу CDN, которая позволяет распределять трафик по нескольким серверам для поглощения и смягчения последствий атак.
Внедрите балансировщики нагрузки, они позволяют равномерно распределять трафик между несколькими серверами, что помогает справиться с внезапными всплесками трафика при DDoS-атаках.
Настройте механизмы ограничения скорости, чтобы ограничить количество запросов в секунду с отдельных IP-адресов или подсетей.
Используйте маршрутизацию anycast для распределения входящего трафика между несколькими ЦОД или локациями — это затрудняет атаку на одну цель.
Рассмотрите услуги по защите от кибератак. Сторонние службы защиты, специализирующиеся на смягчении и поглощении DDoS-атак помогут до того, как они достигнут вашей инфраструктуры.
Что делать, если на сайт направлена DDoS-атака
Если вы обнаружили направленную на ваш сайт DDoS-атаку, выполните следующие действия:
Сохраняйте спокойствие — атаки направлены на нарушение работы сервисов, но, как правило, они не приводят к компрометации данных или систем.
Немедленно свяжитесь с хостинг-провайдером или сетевым администратором и сообщите им об атаке. Возможно, они смогут оказать помощь.
Задействуйте все имеющиеся у вас механизмы защиты от DDoS-атак.
Включите подробное протоколирование и мониторинг для сбора доказательств атаки. Эта информация может быть полезна при проведении расследования.
Если атака носит серьезный характер или является частью более масштабной киберпреступной кампании, следует привлечь местные правоохранительные органы.
Информируйте своих пользователей о ситуации, принимаемых мерах и возможном влиянии на работу сервисов. Регулярно обновляйте информацию по всем каналам связи.
Помните, что наиболее эффективная защита от DDoS-атак — наличие надежной и хорошо подготовленной стратегии защиты до начала атаки. Регулярно пересматривайте и обновляйте свои меры безопасности, чтобы опережать развивающиеся угрозы.
Traceroute — трассировка сети в Linux
Traceroute — это инструмент диагностики сети, используемый в Linux и других ОС для отслеживания маршрута прохождения сетевых пакетов от источника к месту назначения. Traceroute предоставляет информацию о промежуточных маршрутизаторах, через которые проходят пакеты, а также время прохождения в оба конца (RTT) для каждого маршрутизатора.
Как работает Traceroute?
Traceroute работает путем отправки серии UDP- или ICMP-пакетов с постепенно увеличивающимся временем жизни (TTL). Каждому пакету намеренно присваивается низкое значение TTL, что приводит к истечению срока его действия в каждом маршрутизаторе на пути следования. Когда срок действия пакета истекает, маршрутизатор отправляет ответное сообщение ICMP Time Exceeded, что позволяет Traceroute определить IP-адрес маршрутизатора.
Повторяя этот процесс с увеличивающимися значениями TTL, Traceroute постепенно строит карту сетевого маршрута и измеряет время прохождения маршрута (RTT) до каждого хопа.
Настройка Traceroute
Чтобы использовать Traceroute, откройте терминал и выполните следующую команду:
traceroute <destination>
Замените <destination> на IP-адрес или доменное имя цели, которую вы хотите отследить.
Полезные опции Traceroute:
-I: использовать пакеты ICMP Echo Request вместо UDP. Некоторые маршрутизаторы могут блокировать UDP-пакеты, поэтому ICMP может быть более надежным.
-T: использовать пакеты TCP SYN вместо UDP. Это может быть полезно для отслеживания пути к определенному TCP-порту.
-p <port>: указание пользовательского номера порта назначения.
-q <queries>: устанавливает количество запросов, отправляемых за один переход.
-m <max_hops>: устанавливает максимальное количество переходов для трассировки.
-w <timeout>: установка таймаута для каждого зонда.
-n: не преобразовывать имена хостов в IP-адреса.
-r: обходить обычные таблицы маршрутизации и отправлять пакеты непосредственно на целевой хост в локальной сети.
-4 или -6: Принудительное использование протокола IPv4 или IPv6 соответственно.
Дополнительные опции и подробности можно найти на странице руководства Traceroute, выполнив команду:
man traceroute
Traceroute в ОС Windows.
В операционной системе Windows инструмент, эквивалентный Traceroute, называется tracert. Он функционирует аналогичным образом, но синтаксис команды и доступные опции несколько отличаются. Чтобы воспользоваться tracert, откройте командную строку и выполните команду:
tracert <destination>
Замените <destination> на IP-адрес или доменное имя, которое вы хотите отследить.
Чтобы просмотреть доступные опции и синтаксис для tracert в Windows, выполните команду:
tracert /?
Теперь вы знаете, как использовать Traceroute для трассировки сети в Linux, включая установку, базовое использование и некоторые полезные опции.
Установка и использование OpenVAS (GVM) на Ubuntu
OpenVAS (Open Vulnerability Assessment System) — это open-source инструмент сканирования, выявления и управления уязвимостями в компьютерных системах и сетях с открытым исходным кодом. OpenVAS помогает организациям оценить уровень защищенности своей ИТ-инфраструктуры и определить приоритетность мер по ее устранению.
Установка и настройка OpenVAS
Шаг 1: Обновление и модернизация.
Войдите на свой сервер Ubuntu, обновите списки пакетов и обновите существующие пакеты, выполнив следующие команды:
sudo apt update
sudo apt upgrade
Шаг 2: Установка необходимых зависимостей.
Установите необходимые зависимости для OpenVAS, выполнив следующую команду:
Для хранения данных OpenVAS требуется база данных PostgreSQL. Команда для установки:
sudo apt install postgresql
В процессе установки вам будет предложено задать пароль для пользователя PostgreSQL `postgres`. Выберите надежный пароль и запомните его на будущее.
Шаг 4: Создание пользователя и базы данных PostgreSQL.
Переключитесь на пользователя `postgres` и откройте приглашение PostgreSQL, выполнив команду:
sudo -u postgres psql
Создайте нового пользователя для OpenVAS:
CREATE USER openvas WITH PASSWORD ‘your_password’;
Создайте новую базу данных для OpenVAS и предоставьте привилегии пользователю:
CREATE DATABASE openvas;
GRANT ALL PRIVILEGES ON DATABASE openvas TO openvas;
Выйдите из окна PostgreSQL:
\q
Шаг 5: Установка OpenVAS.
Добавьте репозиторий OpenVAS и обновите списки пакетов, выполнив следующие команды:
sudo add-apt-repository ppa:mrazavi/openvas
sudo apt update
Установите OpenVAS, выполнив команду:
sudo apt install gvm
В процессе установки вам будет предложено настроить OpenVAS. Выберите «да» в ответ на запрос о настройке сканера OpenVAS.
Шаг 6: Запуск OpenVAS.
Запустите службы OpenVAS, выполнив следующую команду:
sudo gvm-start
Шаг 7: Обновление каналов OpenVAS.
Обновите фиды OpenVAS, включая NVTs (тесты сетевых уязвимостей), выполнив команду:
sudo gvm-feed-update
Этот процесс может занять некоторое время, так как он загружает необходимые данные для сканирования уязвимостей.
Шаг 8: Доступ к веб-интерфейсу OpenVAS.
Откройте веб-браузер и введите следующий URL:
https://localhost:9392
Появится предупреждение о безопасности, поскольку SSL-сертификат по умолчанию является самоподписанным. Примите предупреждение и перейдите в веб-интерфейс.
Войдите в систему, используя стандартные учетные данные:
Имя пользователя: `admin`
Пароль: `admin`
Шаг 9: Изменение пароля администратора OpenVAS.
После входа в систему рекомендуется изменить стандартный пароль администратора. Перейдите в раздел «Администрирование» и выберите «Пользователи». Щелкните на значке карандаша рядом с пользователем «admin» и задайте новый пароль.
Теперь вы можете создавать цели, настраивать конфигурации сканирования, планировать сканирование и просматривать результаты сканирования с помощью веб-интерфейса OpenVAS.
Установка Nextcloud на дистрибутиве Ubuntu 22.04
В этой инструкции приведено пошаговое руководство по установке и настройке Nextcloud на Ubuntu 22.04, включая настройку MariaDB, Apache и обеспечение безопасности сервера с помощью SSL-сертификата.
Для установки и настройки Nextcloud на Ubuntu 22.04 вам понадобится:
сервер Ubuntu 22.04 с корневым доступом;
доменное имя, указывающее на IP-адрес вашего сервера;
базовые знания командной строки Linux.
Что такое Nextcloud?
Nextcloud — это платформа для хостинга файлов и совместной работы с открытым исходным кодом. Nextcloud позволяет хранить, синхронизировать и обмениваться файлами и данными между различными устройствами и пользователями. Платформа представляет собой альтернативу коммерческим облачным сервисам хранения данных, позволяя контролировать данные и управлять собственным частным облачным сервером.
Установка и настройка Nextcloud
Шаг 1: Обновление и модернизация
Войдите на сервер Ubuntu, обновите списки пакетов и существующие пакеты, выполнив следующие команды:
Заголовок всегда устанавливается Strict-Transport-Security «max-age=15552000; includeSubDomains»
</IfModule>
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
Замените “admin@example.com” на ваш адрес электронной почты, “your_domain” — на ваше реальное доменное имя.
Включите виртуальный хост:
sudo a2ensite nextcloud.conf
Отключите виртуальный хост Apache по умолчанию:
sudo a2dissite 000-default.conf
Перезапустите Apache, чтобы изменения вступили в силу:
sudo systemctl restart apache2
Шаг 10: Доступ к Nextcloud и завершение установки.
Откройте веб-браузер и введите доменное имя вашего сервера (например, `http://your_domain/nextcloud`). Должна появиться страница установки Nextcloud.
Следуйте инструкциям на экране для завершения установки. При появлении запроса введите данные базы данных MariaDB:
Пользователь базы данных: `nextclouduser`.
Пароль базы данных, заданный на шаге 7.
Имя базы данных: `nextcloud`
Хост базы данных: `localhost`.
Продолжите оставшиеся шаги установки, включая создание учетной записи администратора и указание местоположения папки с данными. Теперь вы можете начать использовать Nextcloud для хранения и управления своими файлами.
PostgreSQL
PostgreSQL — это надежная система управления реляционными базами данных с открытым исходным кодом. СУБД известна своими многофункциональными возможностями и повышенным вниманием к целостности и надежности данных. PostgreSQL обладает широким набором дополнительных возможностей, включая поддержку сложных запросов, типов данных и пользовательских расширений, что делает ее универсальным выбором для различных приложений.
Сервер PostgreSQL
Сервер PostgreSQL управляет базой данных и обрабатывает клиентские соединения и запросы. Он обеспечивает безопасную и масштабируемую среду для хранения данных и доступа к ним. Сервер поддерживает различные ОС, включая Windows, macOS и Linux, а также обеспечивает совместимость с различными языками программирования и фреймворками.
PostgreSQL поддерживает одновременные соединения от нескольких клиентов, что обеспечивает эффективный многопользовательский доступ. Для обеспечения целостности данных и защиты от несанкционированного доступа используются надежные средства защиты, включая методы аутентификации, шифрование SSL/TLS и механизмы контроля доступа.
Кроме того, PostgreSQL предлагает интерфейс командной строки (CLI) и графические инструменты, такие как pgAdmin, для администрирования, мониторинга и настройки производительности базы данных.
Почему PostgreSQL популярен
PostgreSQL славится широким набором дополнительных возможностей. СУБД поддерживает сложные запросы, включая оконные функции, общие табличные выражения (CTE) и рекурсивные запросы. Предлагаются механизмы индексирования, включая B-деревья, хэши и обобщенные инвертированные индексы. Кроме того, в PostgreSQL реализована поддержка расширенных типов данных, таких как массивы, hstore и JSON, что позволяет гибко моделировать и хранить данные.
В PostgreSQL большое внимание уделяется целостности и надежности данных. СУБД поддерживает свойства ACID (Atomicity, Consistency, Isolation, Durability), обеспечивающие надежную и последовательную обработку транзакций. Для обработки одновременных модификаций данных в PostgreSQL используется многоверсионный контроль параллелизма (MVCC), обеспечивающий эффективный и согласованный доступ к данным в средах с высокой интенсивностью работы.
PostgreSQL обладает высокой степенью расширяемости за счет пользовательских расширений и функций, определяемых пользователем. Разработчики могут создавать собственные типы данных, операторы и функции для удовлетворения конкретных потребностей приложений. Такая гибкость позволяет разработчикам расширять функциональность PostgreSQL в соответствии с уникальными требованиями.
MySQL
MySQL — широко используемая система управления реляционными базами данных (СУБД) с открытым исходным кодом. Она представляет собой эффективное и масштабируемое решение для хранения, управления и поиска данных.
Разница между MySQL и SQL
SQL (Structured Query Language) — язык программирования, используемый для управления и манипулирования реляционными базами данных. MySQL — СУБД, основанная на SQL и работающая по модели клиент-сервер. MySQL — это ПО, позволяющее использовать SQL для взаимодействия с базой данных.
MySQL-сервер
MySQL использует клиент-серверную архитектуру, при которой сервер выполняет задачи управления базой данных, а клиенты взаимодействуют с сервером для выполнения операций с БД. Сервер MySQL обеспечивает надежную и безопасную среду для хранения и управления данными. Он обеспечивает целостность данных за счет соответствия стандарту ACID (Atomicity, Consistency, Isolation, Durability) и поддерживает различные механизмы хранения данных, включая InnoDB, MyISAM.
Сервер обладает широкими возможностями конфигурирования, что позволяет администраторам оптимизировать параметры производительности, безопасности и использования ресурсов. Он поддерживает одновременные соединения с несколькими клиентами и работает с различными протоколами, включая TCP/IP, именованные каналы и общую память.
Кроме того, MySQL предоставляет инструменты и утилиты, такие как MySQL Workbench и интерфейс командной строки, для облегчения задач администрирования и управления базами данных.
Причины популярности MySQL
MySQL завоевал широкую популярность по нескольким причинам:
Открытый исходный код. MySQL свободно доступна для использования, модификации и распространения.
Высокая масштабируемость. MySQL пригоден для использования в различных приложениях — от небольших до крупных корпоративных систем.
Высокая производительность. MySQL способен выдерживать высокую нагрузку и эффективно обрабатывать большие объемы данных, обеспечивая быстрое выполнение запросов и время отклика.
Широкая поддержка платформ. MySQL может работать под управлением различных ОС: Windows, macOS, Linux и других.
Широкий набор функций. MySQL различные типы данных, хранимые процедуры, триггеры и представления, обеспечивает надежную поддержку транзакций и предлагает развитые механизмы безопасности.
Сильное сообщество и экосистема. MySQL имеет активное сообщество разработчиков, которое вносит свой вклад в его постоянное развитие и совершенствование.
Как отключить SELinux на CentOS
Чтобы отключить SELinux в CentOS, вы можете выполнить следующие шаги:
Откройте терминал на вашей системе CentOS.
Отредактируйте файл конфигурации SELinux с помощью текстового редактора, например, nano или vi. Выполните следующую команду:
sudo nano /etc/selinux/config
В конфигурационном файле найдите строку, определяющую параметр `SELINUX`. Она должна выглядеть следующим образом:
SELINUX=enforcing
Измените значение параметра `SELINUX` на `disabled`:
SELINUX=disabled
Сохраните изменения и выйдите из текстового редактора.
Перезагрузите систему CentOS, чтобы изменения вступили в силу. Вы можете сделать это, выполнив следующую команду:
sudo reboot
После перезагрузки SELinux будет отключен в вашей системе CentOS. Важно отметить, что отключение SELinux снижает безопасность вашей системы, поэтому убедитесь, что вы понимаете последствия и при необходимости рассмотрите другие меры безопасности.
Установка и запуск Nginx в Docker-контейнере на Ubuntu
Чтобы установить и запустить Nginx в контейнере Docker на Ubuntu, вы можете выполнить следующие шаги:
Установите Docker на вашу систему Ubuntu. Откройте терминал и выполните следующие команды:
sudo apt update
sudo apt install docker.io
Извлеките официальный образ Nginx из Docker Hub, выполнив следующую команду:
sudo docker pull nginx
После загрузки образа вы можете запустить контейнер Docker с помощью следующей команды:
sudo docker run -d -p 80:80 nginx
Эта команда запускает контейнер в отсоединенном режиме (`-d`), сопоставляет порт 80 контейнера с портом 80 хоста (`-p 80:80`) и использует образ Nginx.
Получите доступ к Nginx: После запуска контейнера вы можете получить доступ к Nginx, открыв веб-браузер и введя `http://localhost` или IP-адрес вашей системы Ubuntu. Если вы хотите обслуживать файлы из определенного каталога на вашей системе Ubuntu, вы можете назначить том с хоста на контейнер. Например, если файлы вашего сайта расположены в директории `/path/to/website`, вы можете изменить команду `docker run` следующим образом:
sudo docker run -d -p 80:80 -v /path/to/website:/usr/share/nginx/html nginx
Эта команда монтирует каталог `/path/to/website` на хосте в каталог `/usr/share/nginx/html` внутри контейнера, позволяя Nginx обслуживать файлы из этого места.
Теперь у вас есть Nginx, запущенный в контейнере Docker на Ubuntu. Не забывайте корректировать команды и пути в зависимости от ваших конкретных настроек и требований.
Как запустить веб-приложение на Nginx в Docker
Чтобы запустить веб-приложение на Nginx в Docker, необходимо выполнить следующие общие шаги:
Убедитесь, что ваше веб-приложение готово и имеет все необходимые файлы и зависимости.
Создайте Dockerfile в корневом каталоге вашего веб-приложения. Dockerfile содержит инструкции по созданию образа Docker.
# Use a base image
FROM nginx:latest
# Copy the application files to the container
COPY . /usr/share/nginx/html
# Expose the container port
EXPOSE 80
Соберите образ Docker — откройте терминал, перейдите в каталог с Dockerfile и выполните команду для сборки образа Docker. Эта команда создаст образ с именем «my-webapp» на основе Dockerfile.
docker build -t my-webapp .
Запустите контейнер Docker: После того как образ собран, вы можете запустить контейнер из него с помощью следующей команды.
docker run -d -p 80:80 my-webapp
Эта команда запускает контейнер в отсоединенном режиме (`-d`), сопоставляя порт 80 контейнера с портом 80 хоста (`-p 80:80`) и используя образ «my-webapp».
Получите доступ к веб-приложению: После запуска контейнера вы можете получить доступ к вашему веб-приложению, открыв веб-браузер и введя `http://localhost` или соответствующий IP-адрес вашего хоста Docker.
Эти шаги предполагают, что ваше веб-приложение совместимо с Nginx и может обслуживаться как статические файлы. Не забудьте адаптировать шаги в соответствии с конкретными требованиями вашего веб-приложения.
Повышение безопасности контейнеров Docker
Контейнеры Docker — эффективное и масштабируемое решение для разработки и развертывания ПО. Обеспечение безопасности контейнерных приложений важно для защиты конфиденциальных данных и предотвращения несанкционированного доступа. Рассмотрим несколько основных методов повышения безопасности контейнеров Docker, которые позволят вам создавать надежные и безопасные контейнерные среды.
Используйте официальные образы и проверенные репозитории
Официальные образы регулярно обновляются, а их целостность поддерживается надежными организациями. Проверенные репозитории помогают убедиться, что используемые вами образы получены из надежных источников. Вы минимизируете риск использования потенциально взломанных или устаревших образов контейнеров.
Регулярно обновляйте образы контейнеров
Обновления часто включают исправления безопасности и ошибки, которые устраняют уязвимости, обнаруженные со временем. Регулярно обновляя образы контейнеров, вы сможете использовать эти улучшения безопасности и защитить свои контейнеры от потенциальных угроз.
Средства сканирования уязвимостей анализируют компоненты образа и сравнивают их с обширной базой данных уязвимостей. Обнаружив и устранив уязвимости до развертывания, вы сможете значительно снизить риск их эксплуатации.
Используйте безопасные базовые образы
Начинайте процесс контейнеризации с безопасного базового образа. Избегайте использования типовых или минималистичных образов, в которых отсутствуют необходимые меры безопасности. Вместо этого выбирайте базовые образы, созданные с учетом требований безопасности, например, предоставленные официальными репозиториями Docker или авторитетными сторонними источниками.
Реализуйте принцип наименьших привилегий
При настройке разрешений контейнеров следуйте принципу наименьших привилегий. Убедитесь, что контейнеры имеют только необходимые разрешения и права доступа, необходимые для нормального функционирования. Ограничьте выполнение контейнеров от имени root и предоставляйте определенные привилегии только в случае крайней необходимости. Минимизировав привилегии своих контейнеров, вы сможете уменьшить потенциальное воздействие компрометации.
Включите Docker Content Trust
Docker Content Trust служит для обеспечения целостности и подлинности образа. DCT использует криптографические подписи для проверки подлинности образов и предотвращения выполнения измененных или поддельных образов. Включив DCT, вы можете гарантировать, что в вашей среде будут развернуты только подписанные и проверенные образы, что снижает риск вредоносного внедрения образов.
Изолируйте контейнеры с помощью правильной конфигурации сети
Внедрите сегментацию и изоляцию сети, чтобы ограничить подверженность контейнеров внешним угрозам. Используйте сетевые функции Docker, такие как мостовые сети, чтобы разделить контейнеры и контролировать их взаимодействие. Используйте брандмауэры и группы безопасности для ограничения сетевого доступа между контейнерами, разрешая только необходимые соединения.
Используйте безопасный контейнерный хост
Поддержание безопасности узла контейнера и базовой среды имеет решающее значение для общей безопасности контейнера. Регулярно устанавливайте заплатки и обновляйте хост-систему для устранения любых уязвимостей безопасности. Для защиты хост-системы внедрите надежные средства контроля доступа, включая аутентификацию и авторизацию пользователей. Кроме того, рассмотрите возможность использования решений безопасности на уровне хоста, такие как системы обнаружения вторжений и контроля целостности файлов, для укрепления безопасности всей среды.
Повышение безопасности контейнеров Docker требует многоуровневого подхода, включающего в себя различные методы. Следуя нашим советам, вы можете значительно повысить безопасность ваших контейнеров Docker.
CDN
CDN расшифровывается как Content Delivery Network (сеть доставки контента). Это распределенная сеть серверов, расположенных в разных географических точках, которые совместно работают над доставкой веб-контента конечным пользователям. Контент может быть статическим или динамическим, таким как изображения, видео, файлы CSS, файлы JavaScript. Основной целью CDN является повышение производительности, доступности и надежности доставки контента при одновременном снижении нагрузки на исходный сервер.
Ключевые особенности и преимущества CDN
Кэширование контента — серверы CDN кэшируют копии статического и динамического контента ближе к конечным пользователям в нескольких точках по всему миру. Когда пользователь запрашивает контент, CDN доставляет его с ближайшего сервера, сокращая расстояние и сетевые задержки. Кэширование контента улучшает время отклика, повышает удобство работы пользователей и снижает нагрузку на исходный сервер.
Глобальный охват — серверы CDN стратегически расположены в различных точках мира. Это обеспечивает доставку контента с сервера, расположенного близко к пользователю, уменьшая задержку и перегрузку сети. Подобный подход позволяет быстро получить доступ к контенту независимо от географического положения пользователя.
Масштабируемость — CDN распределяет нагрузку между несколькими серверами. По мере роста спроса на контент CDN могут эффективно справляться с высокой нагрузкой на трафик, направляя запросы на наиболее оптимальный сервер с учетом таких факторов, как географическая близость, загрузка сервера и состояние сети.
Балансировка нагрузки — CDN используют методы балансировки нагрузки для равномерного распределения трафика между несколькими серверами. Это гарантирует, что ни один сервер не будет перегружен, и повышает общую производительность и доступность.
Смягчение последствий DDoS — CDN предлагают механизмы защиты от DDoS-атак. Распределяя трафик между несколькими серверами и используя сложные методы фильтрации и анализа трафика, CDN могут смягчать кибератаки и гарантировать, что легитимные запросы дойдут до исходного сервера.
Повышенная надежность — распределяя контент по нескольким серверам, CDN повышают отказоустойчивость. Если сервер или сетевое соединение выходят из строя, CDN может автоматически направлять запросы на альтернативные серверы, обеспечивая постоянную доступность контента.
Аналитика — CDN предоставляют инструменты аналитики и отчетности, которые позволяют получить ценную информацию о производительности доставки контента, поведении пользователей и структуре трафика. Эти данные могут помочь оптимизировать стратегии доставки контента и определить области для улучшения.
CDN широко используются веб-сайтами, мобильными приложениями, потоковыми платформами и другими онлайн-сервисами, которые полагаются на эффективную доставку контента.
Используя возможности CDN, организации могут быстрее доставлять контент, снижать задержки, улучшать пользовательский опыт, повышать масштабируемость и общую доступность и надежность своих онлайн-сервисов.
Облачные базы данных (DBaaS)
DBaaS означает «база данных как услуга». Это модель облачных вычислений, которая предоставляет пользователям управляемую среду баз данных, избавляя их от необходимости создавать и поддерживать собственную инфраструктуру БД.
Ключевые характеристики и преимущества DBaaS
Поставщики DBaaS решают задачи управления базой данных, включая установку, настройку, масштабирование, оптимизацию производительности, обеспечение безопасности, резервное копирование и обновление. Это освобождает пользователей от бремени управления сложной инфраструктурой БД и позволяет им сосредоточиться на основной деятельности.
DBaaS обеспечивает масштабируемость, позволяя пользователям легко масштабировать свои БД в соответствии с их потребностями. Пользователи могут увеличивать или уменьшать ресурсы, выделенные для своих баз данных, такие как процессор, память и хранилище, без значительного ручного вмешательства.
При использовании DBaaS пользователи платят только за те ресурсы, которые они потребляют. Это позволяет избежать предварительных затрат, связанных с приобретением и обслуживанием аппаратной и программной инфраструктуры. Кроме того, пользователи могут избежать расходов на наем специализированных администраторов или экспертов по БД.
Высокая доступность и отказоустойчивость: Поставщики DBaaS обычно предлагают высокодоступные и отказоустойчивые системы баз данных. Они реплицируют данные на несколько серверов или ЦОД, обеспечивая доступ к данным даже в случае аппаратных сбоев или катастроф.
DBaaS автоматизирует многие рутинные задачи по управлению базами данных, такие как резервное копирование, обновление ПО и мониторинг производительности. Это снижает сложность эксплуатации и позволяет пользователям более эффективно развертывать и управлять БД.
Поставщики DBaaS применяют надежные меры безопасности для защиты данных. Они могут предлагать такие функции, как шифрование, контроль доступа, аудит и сертификация соответствия, чтобы обеспечить безопасность и конфиденциальность данных, хранящихся в базах данных.
Популярные примеры предложений DBaaS включают Amazon RDS, Google Cloud SQL, Microsoft Azure SQL Database и Oracle Autonomous Database. Эти сервисы поддерживают различные технологии баз данных, такие как реляционные базы данных, например, MySQL, PostgreSQL, Oracle, SQL Server и базы данных NoSQL, такие как MongoDB и Cassandra.
DBaaS предоставляет организациям и разработчикам удобный и эффективный способ использования баз данных без сложности управления базовой инфраструктурой, позволяя им сосредоточиться на своих приложениях и задачах, связанных с данными.
Сброс пароля root в MySQL
Если вы забыли пароль корня базы данных MySQL или хотите повысить безопасность, изменив его, вы можете сбросить пароль. В данном руководстве мы объясним, как это сделать с помощью командной строки Windows.
Остановите сервер MySQL
Для начала убедитесь, что вы вошли в операционную систему Windows с правами администратора.
Одновременно нажмите клавишу Windows (Win) и клавишу R на клавиатуре, чтобы открыть окно «Выполнить».
В открывшемся поле введите «services.msc», а затем нажмите кнопку OK.
Перейдите по списку служб и найдите запись для MySQL. Щелкните на ней правой кнопкой мыши и выберите «Остановить» из появившихся вариантов.
Помните, что эти инструкции предназначены для операционных систем Windows. Если вы используете другую операционную систему, шаги могут отличаться.
Чтобы изменить пароль с помощью текстового редактора:
Чтобы открыть Блокнот, вы можете найти его в меню или воспользоваться следующим путем: Меню Пуск > Аксессуары Windows > Блокнот.
Открыв Блокнот, создайте новый текстовый документ.
В текстовом редакторе введите следующую строку: ALTER USER ‘root’@’localhost’ IDENTIFIED BY ‘NewPassword’;
Убедитесь, что вы точно указали кавычки и точку с запятой. Замените ‘NewPassword’ на желаемый новый пароль.
Чтобы сохранить файл, перейдите в меню ‘Файл’ и выберите ‘Сохранить как’. Выберите осмысленное имя для файла и сохраните его в корневом каталоге жесткого диска (C:).
Обратите внимание, что изменять учетные данные пользователя следует с осторожностью, и для защиты вашей системы необходимо следовать надлежащим правилам безопасности.
Примечание: Если вы собираетесь менять пароль по сети, замените ‘localhost’ на соответствующее имя хоста.
Выполнив эти шаги и выполнив команду SQL, вы сможете изменить пароль, связанный с пользователем ‘root’ в MySQL.
Чтобы открыть командную строку от имени администратора:
Чтобы запустить диспетчер задач, нажмите одновременно клавиши Ctrl+Shift+Esc.
После появления окна диспетчера задач нажмите на пункт «Файл», расположенный в меню.
Среди доступных вариантов выберите «Начать новую задачу».
В диалоговом окне «Создание новой задачи» введите «cmd.exe» в предоставленное текстовое поле.
Чтобы запустить командную строку с привилегиями администратора, убедитесь, что установлен флажок «Создать эту задачу с привилегиями администратора».
Наконец, нажмите на кнопку «OK», чтобы запустить командную строку с повышенными привилегиями.
Чтобы перезапустить сервер MySQL с обновленным файлом конфигурации, выполните следующие действия:
Используя командную строку, перейдите в каталог, где установлен MySQL. Это можно сделать, выполнив следующую команду:
cd «C:\Program Files\MySQL\MySQL Server 8.0\bin».
Затем введите следующую команду:
mysqld —init-file=C:\FILE_Name.txt
Эта команда инициализирует MySQL, используя указанный файл инициализации (замените «FILE_Name» на реальное имя вашего файла, расположенного по адресу C:).
Теперь вы можете войти на ваш сервер MySQL как пользователь root, используя новый пароль, который вы установили. Чтобы убедиться, что все работает правильно, войдите на сервер MySQL еще раз с обновленным паролем. Если у вас есть какие-либо специфические параметры конфигурации, например, запуск MySQL с флагом «-defaults-file», обязательно включите их, если это необходимо.
После того, как вы запустили MySQL и подтвердили смену пароля, вы можете смело удалить файл, расположенный по адресу C:\FILE_Name.txt.
Поздравляем! Вы успешно сбросили пароль root для базы данных MySQL.
Как создавать таблицы в MySQL
Существует два широко используемых типа баз данных: реляционные и нереляционные. Нереляционные базы данных имеют гибкую модель хранения, которая соответствует конкретным требованиям хранимых данных. Они могут хранить данные в различных форматах, таких как пары ключ-значение, файлы JSON или графы.
Реляционные базы данных, с другой стороны, структурированы вокруг таблиц с предопределенными отношениями между данными. Информация хранится в строках и столбцах, где каждая строка представляет определенный объект или сущность. Известными примерами реляционных баз данных являются Oracle DB, PostgreSQL, MySQL и другие.
USE database_name;
После того как вы указали базу данных, вы можете использовать оператор CREATE TABLE в MySQL для создания новой таблицы. Этот оператор позволяет определить различные атрибуты таблицы, такие как имена столбцов, типы данных, описания и ограничения. Синтаксис для создания таблицы следующий:
CREATE TABLE table_name (
column_name_one column_type_one,
column_name_two column_type_two,
…,
column_name_X column_type_X
);
В синтаксисе замените table_name на желаемое имя вашей таблицы. Затем перечислите имена столбцов и соответствующие им типы данных. Вы можете определить несколько столбцов, разделяя их запятыми.
Если вы хотите создать новую таблицу путем копирования структуры и данных из существующей таблицы, вы можете использовать оператор CREATE TABLE с предложением SELECT. Вот пример:
CREATE TABLE new_table_name [AS] SELECT * FROM original_table_name;
Этот оператор создает новую таблицу с именем new_table_name на основе структуры и данных original_table_name.
Чтобы переименовать существующую таблицу, можно воспользоваться командой RENAME TABLE. Вот пример:
RENAME TABLE old_table_name TO new_table_name;
Выполнив эту команду, вы переименуете таблицу с old_table_name на new_table_name.
Не забудьте при выполнении этих команд заменить имена базы данных database_name, table_name, column_name, column_type, new_table_name и old_table_name на ваши конкретные значения.
Надеюсь, это объяснение поможет вам понять процесс эффективного создания, копирования и переименования таблиц MySQL.
Дополнительная параметры таблиц
При описании таблицы базы данных иногда необходимо включать определенные параметры:
PRIMARY KEY
Этот параметр используется для определения столбца или набора столбцов в качестве первичного ключа. Первичный ключ служит для уникальной идентификации каждой записи в таблице.
AUTO_INCREMENT
При указании этого параметра для столбца значение этого столбца автоматически увеличивается с каждой новой записью, вставленной в таблицу. Только один столбец в таблице может быть обозначен как AUTO_INCREMENT.
UNIQUE
Этот параметр гарантирует, что все значения в столбце должны быть уникальными для всех записей. Он ограничивает наличие дубликатов значений в указанном столбце.
NOT NULL
Когда этот параметр установлен для столбца, он гарантирует, что столбец не может содержать нулевых значений. Каждая запись в указанном столбце должна иметь действительное ненулевое значение.
DEFAULT
Этот параметр позволяет установить значение по умолчанию для столбца. Если новая запись будет вставлена без явного указания значения для столбца, будет использовано значение по умолчанию. Важно отметить, что этот параметр нельзя применять к некоторым типам данных, таким как BLOB, TEXT, GEOMETRY и JSON.
Используя эти параметры, вы можете эффективно определить структуру и ограничения таблицы вашей базы данных.
Названия таблиц и столбцов
При создании базы данных присвоение таблицам и столбцам осмысленных имен является важнейшим аспектом. Использование значимых имен гарантирует, что вы и другие разработчики сможете понять назначение и содержание каждого элемента даже по прошествии значительного количества времени. Рекомендуется избегать использования транслитераций или общих имен, таких как «table1» или «table2». Вместо этого выбирайте описательные и логичные имена, такие как «Пользователи», «Продажи» или «Звонки», которые точно передают характер данных, хранящихся в таблице.
Принятие этого соглашения об именовании также применимо при переименовании столбцов. Выбирая информативные имена, вы повышаете четкость и удобство обслуживания структуры вашей базы данных. Помните, что максимальная длина имени обычно составляет 64 символа.
Типы данных в MySQL
Числа
MySQL предоставляет различные числовые типы данных для хранения различных видов чисел. Вот некоторые часто используемые числовые типы данных в MySQL:
INT:Этот тип представляет знаковые целые числа в диапазоне от -2147483648 до 2147483647. Он занимает 4 байта памяти.
DECIMAL: DECIMAL используется для хранения точных десятичных чисел, и количество занимаемых им байт зависит от выбранной точности. Он может принимать два параметра: DECIMAL(точность, масштаб). Этот тип рекомендуется для работы с валютными значениями и координатами.
TINYINT: TINYINT используется для хранения небольших целых чисел в диапазоне от -127 до 128. Он занимает 1 байт памяти. Атрибут UNSIGNED может быть добавлен, чтобы запретить отрицательные значения.
BOOL: BOOL используется для хранения одного двоичного значения 0 или 1, представляющего «ложь» или «истину» соответственно. Это также синоним BOOLEAN
FLOAT: FLOAT используется для хранения чисел с плавающей запятой и десятичной точкой. Он может содержать до 24 цифр после десятичной точки и занимает 4 байта памяти.
Понимая эти типы числовых данных, вы сможете выбрать подходящий тип в зависимости от ваших конкретных требований к хранению и манипулированию числовыми значениями в MySQL.
Время
В MySQL существуют различные временные типы данных:
DATE .
Тип данных DATE используется для хранения только дат в формате ‘YYYY-MM-DD’. Он позволяет хранить значения между 1000-01-01 и 9999-12-31. DATE обычно используется для хранения дат рождения, исторических дат и других дат, начиная с 11 века и далее. Он занимает 3 байта памяти.
TIME
Тип данных TIME используется для хранения только времени в формате ‘hh:mm:ss’. Он может хранить значения от ‘-838:59:59.00’ до ‘838:59:59.00’. TIME позволяет представлять время с точностью до секунды. Он также занимает 3 байта памяти.
DATETIME
Тип данных DATETIME объединяет дату и время. Он позволяет хранить значения от 1001 года до 9999 лет в формате ‘YYYY-ММ-DD чч:мм:сс’. DATETIME не зависит от часового пояса и может представлять время с точностью до секунды. Этот тип данных занимает 8 байт памяти.
TIMESTAMP
Тип данных TIMESTAMP служит для хранения информации о дате и времени в базе данных. Он представляет собой интервал времени между ‘1970-01-01 00:00:01’ и ‘2038-01-19 03:14:07’ и хранится как количество секунд (включая микросекунды). Фактическое значение TIMESTAMP зависит от настроек часового пояса сервера базы данных. Для хранения этого типа данных обычно требуется 4 байта памяти.
Бинарные типы данных
В MySQL существуют бинарные типы данных, которые позволяют хранить информацию в двоичном формате:
BLOB (Binary Large Object)
Тип данных BLOB используется для хранения больших объемов двоичных данных, таких как файлы, фотографии, документы, аудио- и видеоконтент. Он предназначен для хранения данных размером до 65 КБ.
LONGBLOB (длинный двоичный большой объект)
Тип данных LONGBLOB является эффективным выбором для хранения значительных объемов двоичных данных в базе данных. Он позволяет хранить данные размером до 4 ГБ. Обычно LONGBLOB используется для хранения больших файлов, фотографий, документов, а также аудио- и видеоматериалов.
Изменение структуры таблицы
Оператор ALTER TABLE предлагает удобный и эффективный подход к быстрому введению новых столбцов в таблицу. Он дает возможность добавлять несколько столбцов одновременно, каждый из которых имеет свои собственные типы данных.
ALTER TABLE Table_name
ADD COLUMN email VARCHAR(50),
ADD COLUMN age INT,
ADD COLUMN has_family BOOLEAN;
Эта команда ALTER TABLE эффективно модифицирует указанную таблицу, добавляя столбец email с максимальной длиной 50 символов, столбец age целочисленного типа и столбец has_family булевского типа для представления семейного положения сотрудников.
Удаление таблиц
Оператор DROP TABLE используется для удаления таблицы из базы данных. Это действие навсегда удаляет все данные, индексы, триггеры, ограничения и разрешения, связанные с указанной таблицей. Вот пример команды MySQL, которая может быть использована для удаления таблицы:
DROP TABLE Table_name;
Важно соблюдать осторожность при использовании команды удаления таблицы, поскольку восстановление данных без резервного копирования может быть практически невозможным.
Установка Hyper-V на Windows Server 2012
Введение
При развертывании облачных серверов под управлением Windows Server 2012 и попытке установить Hyper-V вы можете столкнуться с ошибкой, указывающей на то, что Hyper-V уже запущен. Эта ошибка возникает потому, что сам сервер развернут как виртуальная машина. Однако у этой проблемы есть решение: вы можете установить Hyper-V через консоль.
Зайдя в консоль виртуальной машины, вы можете перейти к ролям и функциям сервера и продолжить установку Hyper-V. Это позволит вам использовать возможности виртуализации внутри виртуальной машины, обеспечивая развертывание и управление дополнительными виртуальными машинами внутри нее.
Используя консоль, вы можете применить обходное решение для устранения ошибки и задействовать виртуализацию на облачном сервере Windows Server 2012 путем установки Hyper-V.
Установка Hyper-V с помощью консоли представляет собой эффективное решение для устранения ошибки и позволяет использовать возможности виртуализации на облачном сервере Windows Server 2012.
Установите Multipath I/O, чтобы включить несколько путей к хранилищу:
Install-WindowsFeature Multipath-IO
Теперь сервер можно перезапустить. Введите команду:
Restart-Computer
Как правильно делать бэкапы
Как часто делать бэкапы
Конечно, идеальным вариантом является создание резервных копий как можно чаще. Однако важно понимать, что различные типы данных имеют разную степень обновляемости. Например, архив, в котором раз в месяц хранятся устаревшие документы, может не требовать ежедневного резервного копирования. С другой стороны, база данных крупного розничного магазина постоянно обновляется несколько раз в час. Следовательно, потеря информации даже за один день может иметь критические последствия.
Поэтому частота резервного копирования должна определяться на основе разумной оценки необходимости. Ключевым аспектом является обеспечение регулярного создания копий. Для обеспечения эффективности и последовательности настоятельно рекомендуется автоматизировать этот процесс.
Как делать бэкапы
Автоматизировать процесс резервного копирования действительно рекомендуется. Существует множество программ, доступных для загрузки с надежных сайтов в Интернете. Эти программы позволяют настраивать параметры резервного копирования, в том числе параметры копирования, частоту резервного копирования и место хранения файлов резервных копий.
После настройки параметров в соответствии с вашими требованиями вы можете положиться на автоматизированную систему резервного копирования, которая будет регулярно выполнять резервное копирование, обеспечивая защиту ваших данных от возможного уничтожения или потери.
Автоматизация процесса избавит вас от необходимости постоянно обращаться к этому вопросу, и вы сможете быть спокойны, зная, что ваши данные регулярно резервируются.
Типичные ошибки
Системные администраторы, будучи людьми, склонны совершать ошибки. Вот пять распространенных ошибок резервного копирования, о которых следует знать:
В организациях, где резервное копирование выполняется вручную, полагаться на одного специалиста может быть рискованно. Если этот человек забудет выполнить своевременное копирование данных или покинет компанию без надлежащей документации, то найти и восстановить резервные копии в случае необходимости будет непросто.
Использование старых жестких дисков или устаревших систем резервного копирования может показаться экономически выгодным, особенно если резервные копии создаются нечасто. Однако при возникновении критических ситуаций, таких как аппаратные сбои, использование устаревших технологий может привести к потере данных или простою системы.
Некоторые владельцы бизнеса предпочитают держать свою инфраструктуру внутри компании, полагая, что она более безопасна. Однако облачные решения обеспечивают надежную защиту от внешних угроз, сбоев оборудования и других проблем. Облачные провайдеры обеспечивают своевременное резервное копирование и предлагают варианты восстановления системы в случае сбоев.
Хотя некоторые считают, что еженедельного резервного копирования достаточно, компаниям, регулярно генерирующим новые важные данные, может потребоваться более частое резервное копирование. В зависимости от потребностей бизнеса, для минимизации потери данных может потребоваться даже ежедневное резервное копирование.
Простого создания резервных копий недостаточно. Очень важно периодически тестировать процесс восстановления, чтобы убедиться в работоспособности резервных копий и возможности успешного восстановления данных в случае необходимости.
Правильно выполненное резервное копирование может уберечь компанию от значительных потерь. Если самостоятельное резервное копирование вызывает опасения, то делегирование этой задачи надежному облачному провайдеру может стать мудрым решением. Облачные сервисы, такие как Obit Cloud, предлагают безопасные резервные копии, хранящиеся в надежных центрах обработки данных TIER III, обеспечивая возможность полного восстановления данных в случае аварии.
GitLab
Git, GitHub и GitLab — это взаимосвязанные компоненты в сфере контроля версий и разработки программного обеспечения, хотя и с разными целями и функциями.
Git служит распределенной системой контроля версий, позволяющей разработчикам отслеживать изменения, вносимые в исходный код, и облегчающей совместную работу над программными проектами. Он позволяет нескольким разработчикам одновременно работать над одним проектом, эффективно управлять изменениями кода и вести полную историю проекта.
GitHub и GitLab, напротив, функционируют как платформы веб-хостинга, разработанные специально для репозиториев Git. Они обеспечивают онлайн-среду, которая упрощает управление кодом, отслеживание изменений и совместную работу разработчиков. Обе платформы предлагают ряд функций, таких как отслеживание ошибок, вики и обзоры кода, но они также имеют некоторые различия.
Одним из заметных различий является то, что GitLab включает в себя бесплатную возможность непрерывной интеграции (CI), в то время как GitHub предоставляет инструмент Actions, который обеспечивает бесплатную интеграцию исключительно для публичных репозиториев и требует оплаты для частных репозиториев. Кроме того, в GitLab встроена платформа развертывания Kubernetes, которая отсутствует в предложениях GitHub. Еще одним отличительным фактором является то, что GitLab предоставляет бесплатные репозитории для проектов с открытым исходным кодом, в то время как GitHub не придерживается подобной практики.
Git функционирует как децентрализованная система контроля версий, позволяющая разработчикам отслеживать изменения, вносимые в исходный код, и облегчает совместную работу над программными проектами. Он обеспечивает платформу для одновременной работы нескольких разработчиков над проектом, эффективного управления изменениями кода и ведения полной истории проекта.
Действуя как распределенная система контроля версий, Git создаёт локальный репозиторий на машине каждого разработчика. В этом хранилище хранится полная копия кодовой базы проекта, включая всю его историю. Разработчики могут вносить изменения в код и фиксировать их в своем локальном хранилище, создавая новую версию проекта.
Определение GitLab
GitLab — это сервис совместной разработки, который призван повысить производительность и оптимизировать жизненный цикл продукта для команд разработчиков. Одной из его отличительных особенностей является единая система авторизации, которая устраняет необходимость в отдельных авторизациях для каждого инструмента. Установив разрешения один раз, доступ ко всем компонентам предоставляется каждому сотруднику организации.
Изначально GitLab был полностью бесплатным программным обеспечением с открытым исходным кодом, распространяемым по разрешительной лицензии MIT. Однако затем он был разделен на две различные версии: GitLab CE (Community Edition) и GitLab EE (Enterprise Edition). GitLab CE остался неизменным и продолжает оставаться продуктом с открытым исходным кодом, исходный код которого находится в свободном доступе. GitLab EE, с другой стороны, перешел на модель ограниченного лицензирования, но по-прежнему предоставляет открытый доступ к исходному коду.
В целом, GitLab служит комплексным решением для совместной разработки программного обеспечения, предлагая широкий спектр функций и инструментов для поддержки команд на протяжении всего процесса разработки.
GitLab предлагает широкий спектр возможностей, которые делают его ценным инструментом для команд разработчиков, включая:
Написание, управление и изменение кода, а также синхронизация файлов.
Встроенные инструменты CI/CD, интеграция с GitHub, обеспечение качества кода и нагрузочное тестирование.
Двухфакторная аутентификация для доступа к проекту, поддержка токенов и единого входа (SSO), аналитика производительности для членов команды и отслеживание задач.
Отслеживание производительности приложений, управление инцидентами и обработка данных журналов.
Отслеживание задач и управление временем.
Управление контейнерами и репозиториями, а также интеграция с Docker.
Сканирование уязвимостей, поддержка статического тестирования безопасности приложений (SAST) и динамического тестирования безопасности приложений (DAST), а также сетевая безопасность проекта.
Запуск CI/CD в различных средах, проведение безопасного тестирования кода с помощью канареечных или частичных релизов, а также оркестровка релизов.
Поддержка Kubernetes и бессерверных вычислений.
Почему используют GitLab
GitLab обладает множеством уникальных преимуществ, одним из которых является его исключительная способность содействовать сотрудничеству между командами разработчиков на протяжении всего жизненного цикла проекта. Эта возможность играет ключевую роль в ускорении процесса разработки продукта и повышении эффективности работы команды. Используя полный набор инструментов для совместной работы GitLab, команды могут автоматизировать все аспекты цикла разработки проекта, начиная от первоначального планирования и заканчивая развертыванием приложения. Такая автоматизация позволяет командам добиваться превосходных результатов и поднимать общее качество своих продуктов на новую высоту.
IPMI
Интеллектуальная платформа управления IPMI разработана для упрощения работы системных администраторов и инженеров. С помощью порта управления IPMI можно подключать серверы независимо от используемой операционной системы, процессора или BIOS. Он поддерживает даже DOS. Эта технология позволяет администраторам быстро реагировать на критические проблемы и при необходимости удаленно перезагружать серверы.
IPMI имеет несколько полезных функций, таких как собственные сетевые интерфейсы и сетевые настройки, интегрированная технология IPKVM на Java, позволяющая получить удаленный доступ к серверу через консольное окно, панель управления питанием сервера, а также набор датчиков, отслеживающих текущее состояние оборудования. Если сломался процессор или обнаружен сбой в ОС или BIOS, IPMI позволяет администраторам не только перезагрузить сервер, но и восстановить важнейшие функции управления, обновить программное обеспечение журналирования, перезагрузить систему и многое другое.
Хотя первая версия IPMI была разработана в конце 1990-х годов, она имела ряд недостатков и уязвимостей, которые были устранены в более поздних версиях. Важно также отметить, что производители разрабатывают свои собственные версии этого решения, например, порт iDRAC от Dell, IMM от Lenovo и IBM, а также популярный порт IPMI от Supermicro под названием SIM. Хотя каждый порт может отличаться способом отображения информации и набором функций, их базовая функциональность остается одинаковой.
IPMI — это технология, которая может быть невероятно полезной для системных администраторов и инженеров в различных сценариях. Вот несколько примеров.
Проблемы с доступом к серверу
Если доступ к серверу закрыт из-за неправильных настроек брандмауэра, IPMI может помочь устранить проблему и подключиться к серверу, даже если другие способы доступа недоступны.
Конфигурация сетевой карты
При аренде сервера в центре обработки данных сетевые параметры должны быть правильно сконфигурированы, чтобы обеспечить надлежащее управление системой. Если эти настройки не выполнены, единственным способом управления сервером будет IPMI.
Неудачная установка программного обеспечения
Иногда установка нового программного обеспечения может привести к «зависанию» сервера, делая его недоступным. Однако порт управления IPMI может удаленно перезагрузить сервер, что позволит восстановить доступ.
Хотя IPMI разработан для восстановления после сбоев и ошибок, бывают ситуации, когда он может стать недоступным. Это может произойти из-за сетевых или программных проблем, проблем с электропитанием или аппаратных сбоев, таких как перегрев оборудования или дефекты архитектуры.
В целом, IPMI является невероятно полезной технологией для удаленного управления серверами, позволяя сисадминам и инженерам легко контролировать и управлять серверами независимо от их местоположения, операционной системы или других технических характеристик.
IPMI — инструмент для технических специалистов, позволяющий получить удаленный доступ к серверу, даже если он не работает. Эта технология обеспечивает решение многих распространенных проблем, таких как отказ в доступе, неудачная установка программного обеспечения и проблемы с конфигурацией сетевой карты. Она также предлагает ряд функций, включая собственный сетевой интерфейс, интегрированную технологию IPKVM на Java, управление питанием сервера и набор датчиков.
Случаи, когда нет доступа к IPMI
Однако бывают случаи, когда IPMI может стать недоступным по различным причинам, таким как сетевые сбои, ошибки в программном обеспечении, проблемы с электропитанием или аппаратные проблемы. В таких случаях доступно несколько решений, например, нажатие любой клавиши на клавиатуре, перезагрузка IPMI через команду SSH или использование консоли IPMI для сброса или перезапуска управления IPMI.
Выводы
В целом, IPMI — это критически важный компонент управления сервером, который снижает затраты на его обслуживание и уменьшает необходимость физического присутствия штатных ИТ-специалистов на сервере. Его функциональность и возможности делают его незаменимым инструментом для сисадминов и инженеров, позволяя им получать удаленный доступ и управлять серверами независимо от используемой ОС, процессора или BIOS.
Apache Spark
Apache Spark — это система распределенных вычислений с открытым исходным кодом, предназначенная для обработки больших объемов данных в пакетном и потоковом режимах. Spark широко используется такими крупными компаниями, как Amazon, eBay и Yahoo! благодаря своей скорости и эффективности по сравнению с другими инструментами, такими как Hadoop. Разработчики выигрывают от использования высокоуровневых операторов Spark, которые позволяют быстрее кодировать и обрабатывать данные. Spark особенно полезен для обработки плохо структурированных и неструктурированных данных.
История
Матей Захария, румынско-канадский ученый, широко известен своим значительным вкладом в разработку Apache Spark. Захария начал работу над проектом во время учебы в аспирантуре Калифорнийского университета в 2009 году. Годом позже он выпустил проект под лицензией BSD. Первоначальная реализация Spark была написана в основном на языке Scala, но позже был добавлен код на Java, что позволило разработчикам создавать распределенные приложения и на этом языке.
В 2013 году, через три года после того, как Захария инициировал проект, Apache Spark был передан в Apache Software Foundation. К следующему году он стал основным проектом Apache, работающим под лицензией Apache 2.0.
Apache Spark использует архитектуру Resilient Distributed Dataset (RDD), которая эффективно управляет разнообразными данными на узлах кластера. Кластер представлен в виде циклического направленного графа, в котором узлы представляют наборы данных, а ребра — операции. Для работы с RDD используются такие абстракции, как Dataframe API и Dataset API. Многие организации используют Spark в кластерах, состоящих из тысяч узлов, демонстрируя его масштабируемость и широкое распространение.
Хотя Spark по своей сути не является частью Apache Hadoop, он полностью совместим с экосистемой Hadoop. Запуск Hadoop вместе со Spark не требует дополнительных навыков, а кластер Spark может быть запущен вручную. Узлы кластера могут быть запущены с помощью YARN, а данные могут храниться в распределенной файловой системе Hadoop (HDFS). Для целей разработки и тестирования можно использовать псевдо распределенный режим, при котором каждый узел кластера имеет одно вычислительное ядро CPU.
Особенности Apache Spark
Apache Spark обеспечивает высокий уровень гибкости и совместимости с рядом систем управления кластерами, включая Hadoop и Mesos. Он легко интегрируется с популярными системами хранения данных, такими как Hadoop Distributed File System (HDFS), OpenStack Swift, Cassandra и Amazon S3. Кроме того, Spark поддерживает множество языков программирования, таких как Scala, Python, Java, R, а также языки .NET, такие как C# и F#.
Чтобы облегчить разработку на различных языках, Spark предоставляет несколько API, включая Scala, Java, Python, R и Spark SQL. Эти API позволяют разработчикам использовать возможности Spark для пакетной и потоковой обработки неструктурированных данных, а также для создания эффективных и масштабируемых распределенных приложений. Кроме того, Spark предлагает богатый набор встроенных функций, которые упрощают работу с большими наборами данных и выполнение сложных операций.
Благодаря широкой языковой поддержке, универсальным API и встроенным функциям Apache Spark позволяет разработчикам эффективно обрабатывать и анализировать данные, что дает им возможность решать проблемы больших данных и создавать сложные приложения.
Почему используют именно Apache Spark
Apache Spark заслужил репутацию одной из лучших библиотек с открытым исходным кодом для параллельной обработки данных на компьютерных кластерах, получив признание как разработчиков, так и исследователей больших данных. Она обладает замечательной масштабируемостью, способна работать на одном ноутбуке или масштабироваться до тысяч серверов, причем доступны и облачные решения. Исключительная производительность и эффективное использование ресурсов делают его универсальной платформой для обработки больших данных, что позволяет использовать его для решения широкого круга задач анализа данных.
Помимо пакетной обработки, Spark предоставляет инструменты для обработки потоковых данных, включая SQL, Streaming, MLLib и GraphX. Это делает его особенно выгодным для приложений, связанных с системами Интернета вещей (IoT) и бизнес-приложениями на основе машинного обучения. Например, Spark можно использовать для таких задач, как прогнозирование оттока клиентов или оценка финансовых рисков.
Благодаря унифицированному набору библиотек моделирования, поддерживающих такие популярные языки программирования, как Python и R, а также интеграции с широко используемыми веб-фреймворками, такими как Node.js и Django, Spark привлекает как исследователей, так и веб-разработчиков. Он также широко используется в публичных облачных средах, где организации имеют возможность приобретать отдельные услуги, такие как хранение данных. Универсальность Spark в решении различных задач обработки данных способствовала его широкому распространению во многих отраслях.
Преимущества Apache Spark
Apache Spark предлагает несколько ключевых преимуществ в области обработки больших данных:
Скорость. Spark славится своими возможностями высокоскоростной обработки данных. Он может выполнять приложения в памяти, что позволяет значительно ускорить обработку данных по сравнению с Hadoop. Способность Spark минимизировать циклы чтения-записи на диск и использовать промежуточные данные для хранения в памяти способствует замечательной скорости. Он может выполнять приложения в сто раз быстрее в памяти и в десять раз быстрее на диске, чем Hadoop.
Простота. Spark предоставляет полный набор библиотек, которые упрощают выполнение основных высокоуровневых операций над устойчивыми распределенными наборами данных (RDD). Простота использования отличает Spark от многих других инструментов для работы с большими данными, делая его более доступным для разработчиков и пользователей с разным уровнем знаний.
Обработка больших данных. Spark оптимизирован для эффективной и быстрой вычислительной обработки, что делает его отличным выбором для работы с крупномасштабными данными. Однако его производительность может снижаться по сравнению с Hadoop MapReduce, когда ресурсов памяти недостаточно для обработки очень больших массивов данных.
Функциональность. Spark предлагает широкий спектр функциональных возможностей, что отличает его от Hadoop MapReduce. Он может активировать операции в памяти, обеспечивая более быстрое время обработки. Spark также поддерживает обработку практически в реальном времени, что делает его хорошо подходящим для задач обработки графов. Кроме того, Spark включает специальный API под названием GraphX, который облегчает вычисления с графами.
Машинное обучение (ML). Spark включает встроенную библиотеку ML, которая предоставляет богатый набор алгоритмов для решения задач машинного обучения. Это устраняет необходимость в установке дополнительного программного обеспечения или драйверов, что делает удобной интеграцию возможностей машинного обучения в приложения для разработчиков.
Аппаратная виртуализация
Предположим, ваш компьютер работает под управлением Windows, но вы хотите попробовать Linux, чтобы понять, стоит ли на него переходить. Вы можете установить Linux на второй раздел жесткого диска или на другой компьютер, но это не всегда удобно, особенно если вам нужно работать в обеих системах одновременно. В этом случае может быть полезно использование технологии виртуализации.
Гипервизор — это решение, которое позволяет использовать часть реального оборудования для создания виртуальных машин. Он выделяет необходимые ресурсы и создает виртуальную машину, на которую можно установить Linux. Таким образом, вы можете использовать обе операционные системы одновременно без необходимости перезагрузки.
Виртуализация зародилась в 1960-70-х годах, когда IBM и MIT проводили исследования по разделению вычислительных ресурсов между группами пользователей. Сегодня виртуализация является важной частью ИТ-инфраструктуры, а наиболее известными компаниями, работающими с виртуализацией, являются VMware, Microsoft, Citrix и Oracle. Также популярна аппаратная виртуализация Bluestacks, используемая для эмуляции систем Android. В России одним из аналогов этой технологии является платформа виртуализации vStack.
Определение аппаратной виртуализация
Аппаратная виртуализация — это технология, которая позволяет создавать виртуальные компьютерные среды на одном физическом сервере. Для этого используется гипервизор или диспетчер виртуальных машин, который устанавливается между программными решениями и железом. Наиболее распространенными гипервизорами являются VMware vSphere и Microsoft Hyper-V.
После установки гипервизора система виртуализации может получать информацию о доступных ресурсах и предоставлять возможность управлять ими. Виртуальные ресурсы группируются в виртуальные машины (ВМ), на которые можно устанавливать любые операционные системы и приложения.
Аппаратная виртуализация позволяет создавать несколько ВМ на одном физическом сервере, которые работают в изолированных друг от друга средах. Это означает, что если одна ВМ будет скомпрометирована или выйдет из строя, другие ВМ будут продолжать работу в штатном режиме.
Отличие аппаратной виртуализации от программной заключается в том, что гипервизор становится хост-системой, на которой запускаются все виртуальные машины. Гипервизор выполняет задачу обеспечения возможности запуска любых операционных систем на этой системе и предоставляет им доступ к ресурсам железа.
Аппаратная виртуализация требует поддержки виртуализации на аппаратном уровне в процессоре и материнской плате. Это позволяет гипервизору эффективно распределять ресурсы процессора и памяти между различными виртуальными машинами.
Аппаратная виртуализация поддерживается технологиями, разработанными двумя основными производителями процессоров – Intel VT и AMD-V. Они позволяют использовать виртуализацию процессора для запуска нескольких систем на одном процессоре, работающих параллельно на разных уровнях вложенности.
Типы аппаратной виртуализации
Существует три основных метода виртуализации оборудования в ИТ-инфраструктуре.
Полная виртуализация предполагает моделирование всех аппаратных компонентов, создавая среду, которая может работать на различных серверах без необходимости обширной настройки.
Паравиртуализация создает пользовательскую версию операционной системы для виртуальной машины. Эта ОС изменяется или перестраивается на основе ресурсов, предоставляемых сервером.
Аппаратная виртуализация предполагает полную виртуализацию виртуальной машины, полагаясь на компьютерное оборудование для создания среды.
Выбор подхода к виртуализации зависит от конкретных требований.
Преимущества аппаратной виртуализации
Виртуализация обладает рядом преимуществ, но главное ее достоинство – исключительная гибкость виртуальной инфраструктуры. Гипервизор обеспечивает полный контроль над конфигурацией виртуальных машин (ВМ), позволяя пользователям выбирать необходимые устройства, заполнять шаблон или образ нужной системы, а затем запускать ВМ.
Аппаратная виртуализация способна создать ВМ 64-битной архитектуры даже на процессоре 32-битной архитектуры, что делает ее очень удобной. Кроме того, внешние приложения не могут отличить ВМ от физического устройства, а гостевые операционные системы работают на процессоре без виртуализации, не подозревая о существовании других операционных систем, которые расположены на 1 уровне.
Виртуализация также обеспечивает экономическую эффективность, поскольку снижает расходы на приобретение, установку, настройку и обслуживание локального оборудования. Имея одну высокопроизводительную машину, пользователи могут развернуть несколько виртуальных машин с различными объемами ресурсов и задачами вместо того, чтобы покупать несколько серверов.
Еще одно преимущество виртуализации — адаптивность. Пользователи могут сохранить конфигурацию ВМ в виде шаблона и быстро развернуть ее на различном оборудовании. Кроме того, легко достигается масштабируемость, позволяющая пользователям в любое время создавать необходимое количество ВМ и устанавливать необходимые параметры производительности.
Отказоустойчивость. Пользователи могут создавать снапшоты виртуальных машин и организовывать географически распределенные хранилища для резервных копий, гарантируя, что вся инфраструктура не разрушится даже в случае критического отказа оборудования. Виртуальная инфраструктура будет продолжать функционировать, и пользователи смогут выделять больше ресурсов для ее компонентов.
Наконец, виртуализация обеспечивает безопасность. ВМ изолированы друг от друга, и одна скомпрометированная машина никак не влияет на другие. Кроме того, виртуальные машины не потребляют ресурсы другой машины, что позволяет избежать ненужного разделения ресурсов.
Выделенный сервер
Когда люди приступают к созданию веб-сайта, они часто сталкиваются с необходимостью выбора подходящего варианта хостинга, такого как виртуальный выделенный сервер (VPS), выделенный сервер или общий хостинг. Хотя эти варианты различаются по возможностям конфигурации, объему памяти и стоимости, все они опираются на физические серверы в качестве базовой инфраструктуры. Поэтому, прежде чем вникать в тонкости выделенных серверов, необходимо понять концепцию физического сервера.
Физический сервер — это большой системный блок, включающий в себя процессор, операционную систему, значительный объем памяти и несколько дополнительных устройств. Эти серверы обычно размещаются в специализированных помещениях, называемых центрами обработки данных, которые требуют надежных систем охлаждения и бесперебойного электропитания для поддержания оптимальных условий. Техническое обслуживание и управление этими серверами обычно осуществляется отдельными компаниями, специализирующимися на серверной инфраструктуре.
Физические серверы обладают обширными ресурсами, которые могут превышать потребности одного пользователя. Поэтому такие серверы разделяются на несколько сервисов, например, хостинг или VPS, что позволяет более эффективно распределять ресурсы. Тем не менее, если пользователю необходим полный доступ ко всем функциям и ресурсам физического сервера, у него есть возможность арендовать выделенный сервер.
В целом, физические серверы играют важнейшую роль в создании и управлении веб-сайтами. Пользователи имеют возможность выбирать услуги хостинга, которые наилучшим образом соответствуют их конкретным потребностям и бюджету, будь то виртуальный хостинг, VPS или комплексные возможности, предлагаемые выделенным сервером.
Что такое выделенный сервер и в чем его преимущества?
Выделенный сервер — это сервер, предназначенный исключительно для одного клиента. Преимущества и выгоды выбора выделенного сервера вполне очевидны. При использовании выделенного сервера вся его вычислительная мощность используется исключительно для проекта клиента, что обеспечивает непревзойденную производительность. В отличие от виртуального хостинга или виртуальных частных серверов, здесь нет необходимости делить ресурсы с другими пользователями, что еще больше повышает производительность сервера.
Особенности выделенного сервера
При рассмотрении выбора между виртуальным хостингом, VPS или выделенным сервером важно оценить ваши конкретные цели и требования. Выделенный сервер особенно хорошо подходит для крупных интернет-проектов, интернет-магазинов и приложений, требующих высокопроизводительных ресурсов. Это также надежный вариант для корпоративных клиентов, которым требуется физический сервер для хранения обширных баз данных.
В компании Obit наши выделенные серверы размещаются в надежных центрах обработки данных, обеспечивающих бесперебойное электропитание, резервные каналы связи и первоклассные меры безопасности. Прежде чем предоставить их нашим клиентам, мы проводим тщательное тестирование и проверку, чтобы гарантировать оптимальную производительность и надежность.
Арендуя выделенный сервер в компании Obit, вы получаете полный контроль над своей серверной средой, что позволяет вам настраивать ее в соответствии с вашими предпочтениями. Кроме того, у вас есть возможность масштабировать ресурсы по мере необходимости. Независимо от того, собираетесь ли вы разместить игровой сервер или расширить приложения корпоративного уровня, наши выделенные серверы предлагают необходимые ресурсы и надежность, требуемые для вашего проекта.
Таким образом, выбор виртуального хостинга, VPS или выделенного сервера зависит от ваших конкретных целей. Если вам нужны высокопроизводительные ресурсы, надежность и возможность настраивать и масштабировать серверную среду, выделенный сервер от Obit сможет эффективно удовлетворить ваши потребности.
Выбор конфигурации выделенного сервера
Выбор подходящего выделенного сервера для ваших требований подразумевает вдумчивое рассмотрение различных параметров сервера, которые непосредственно влияют на его производительность. К таким параметрам относятся тип процессора, производительность процессора, характеристики оперативной памяти и производительность дисковой системы.
При выборе процессора для вашего сервера важно обратить внимание на такие ключевые показатели, как количество ядер, тактовая частота ядра и кэш-память. Эти факторы существенно влияют на вычислительные возможности сервера и его общую производительность.
Оперативная память играет важнейшую роль в обеспечении стабильной работы любого сервера, независимо от его уровня и конфигурации. В настоящее время широко распространены два основных стандарта памяти — DDR3 и DDR4. DDR4 предлагает более высокую скорость передачи данных — от 2133 до 2666 МГц по сравнению с диапазоном 1333-1867 МГц DDR3.
Выбор дисковой системы зависит от задач вашего сервера. Диски SAS подходят для задач, требующих быстрого и многопоточного доступа, таких как высоконагруженные веб-серверы, RDBMS (системы управления реляционными базами данных), ERP-системы или крупномасштабные пользовательские системы. Диски SATA хорошо подходят для задач с интенсивным использованием данных, таких как потоковая передача, хранение данных, системы резервного копирования и файловые серверы. Кроме того, SSD-накопители набирают популярность благодаря энергонезависимым чипам памяти и более высокой скорости чтения и записи. Они особенно полезны для сложных проектов, требующих высокой производительности.
Настройка NTP на сервере
Программа NTP (Network Time Protocol), как правило, уже присутствует в дистрибутивах Linux. Чтобы установить ее, вам понадобятся права root. Процесс установки NTP может немного отличаться в зависимости от используемого дистрибутива Linux:
sudo apt-get install ntp
sudo yum install ntp
sudo dnf install ntp
Для настройки NTP используется конфигурационный файл ntp.conf, который обычно находится в каталоге /etc/. Однако, при необходимости, файл можно расположить и в другом месте, указав путь к нему через параметр командной строки «ntpd -c». При запуске демон NTP читает этот файл для получения настроек. Демон может выполнять как роль сервера, так и роль клиента в сети. Чтобы внесенные изменения в файле конфигурации вступили в силу, необходимо перезапустить демона NTP. Конфигурационный файл ntp.conf соответствует стандартному формату и может быть изменен с помощью любого текстового редактора.
NTP использует эталонные серверы или одноранговые узлы для синхронизации локальных системных часов. В файл конфигурации можно добавить один или несколько одноранговых узлов с помощью параметра «server» и указать их адресы (доменные имена или IP-адреса).
При добавлении одноранговых узлов важно учитывать параметр «prefer», который указывает на предпочтительный узел. В случае, когда узлы равнозначны, предпочтительный узел будет выбран из списка. Обычно указывается только один предпочтительный узел.
Рекомендуется указывать нечетное количество одноранговых узлов, чтобы обнаружить возможные временные смещения, превышающие допустимые пределы, если такие изменения происходят в одном из узлов. Алгоритм выбора может в таком случае исключить этот узел из рассмотрения.
Добавление файла «дрифта»
Для хранения информации о смещении частоты локального тактового генератора NTP использует файл «дрифта». В этом файле записывается значение смещения в миллионных долях (PPM). Служба NTP обновляет файл «дрифта» каждый час. Рекомендуется указать путь к файлу «дрифта», так как это позволяет NTP быстрее синхронизировать локальные часы при запуске системы. Обычно файл «дрифта» определяется следующим образом:
driftfile /var/lib/ntp/ntp.drift.
Таким образом, указывая путь к файлу «дрифта» в конфигурационном файле ntp.conf, вы позволяете NTP эффективнее корректировать и синхронизировать локальные системные часы при каждом запуске.
Указание файла статистики
Для указания каталога, в котором будут храниться файлы статистики, вы можете использовать команду «statsdir» в файле конфигурации NTP. Эти файлы статистики полезны для отслеживания производительности локальной синхронизации часов.
Чтобы задать путь к каталогу, где будут сохраняться файлы статистики, просто добавьте следующую строку в файле конфигурации ntp.conf:
statsdir <путь_каталога>
Таким образом, NTP будет записывать файлы статистики в указанный каталог, и вы сможете использовать их для анализа и мониторинга производительности синхронизации часов на локальной системе.
Включение и запуск службы NTP
Для включения и запуска NTP в системе Linux можно использовать команду systemctl, предоставляемую с правами root:
Чтобы включить службу NTP, выполните команду:
sudo systemctl enable ntpd
Для запуска службы NTP, используйте команду:
sudo systemctl start ntpd
Чтобы применить изменения в конфигурации NTP, требуется перезапустить службу. Вы можете сделать это с помощью команды:
sudo systemctl restart ntpd
Если вам потребуется остановить или отключить службу NTP, можно воспользоваться следующими командами:
sudo systemctl disable ntpd
sudo systemctl stop ntpd
Эти команды позволяют управлять службой NTP в вашей системе, включая ее включение, запуск, остановку и отключение в соответствии с вашими потребностями. Обратите внимание, что для выполнения этих команд требуются права root или администратора.
Rclone — настройка и установка
Особенности системы
Прежде чем приступить к установке, позвольте мне познакомить вас с основными функциями и возможностями этого приложения. Программа абсолютно бесплатна, мультиплатформенная и имеет открытый исходный код. Одной из ее ключевых особенностей является возможность монтирования различных типов файловых систем, таких как внутренние, облачные или виртуальные. Кроме того, она позволяет обслуживать внутренние или удаленные файлы по таким протоколам, как SFTP, HTTP, FTP и другим. Является аналогом Rsync в области облачных технологий.
Rclone также обеспечивает безопасность и надежность ваших данных. Перед передачей файлов в облако они шифруются, а при восстановлении — расшифровываются. Программа выполняет синхронизацию данных локального облачного хранилища с удаленным или двумя разными облачными сервисами. Более того, она не копирует одинаковые файлы и не использует локальное дисковое пространство в процессе передачи данных между провайдерами. Он может перемещать файлы внутри облака и удалять локальные файлы после завершения проверки.
Если вы столкнулись с трудностями при загрузке больших файлов, программа предлагает возможность сжать их или разделить на более мелкие части. Кроме того, она проверяет целостность сохраненных данных, гарантируя, что ваши файлы останутся нетронутыми и не поврежденными. Наконец, программа поддерживает те же команды, что и Linux/Unix, что делает ее простой в использовании для тех, кто знаком с этими системами.
Установка Rclone в Linux
Если вы хотите установить Rclone на систему Linux или Unix, есть несколько вариантов. Вы можете использовать официальный сценарий установки, менеджер пакетов или установить из исходных текстов. Ниже приведены шаги для каждого метода:
Использование сценария установки
Сценарий установки можно использовать для установки как стандартной, так и бета-версии Rclone. Чтобы воспользоваться скриптом, откройте терминал и введите следующую команду:
$ curl https://rclone.org/install.sh | sudo bash
Сценарий проверит, установлен ли уже Rclone в системе. Если он установлен, скрипт завершит работу без его переустановки. Чтобы установить бета-версию, выполните следующую команду:
Большинство дистрибутивов Linux включают Rclone в свои репозитории по умолчанию. Чтобы установить Rclone с помощью менеджера пакетов, используйте соответствующую команду для вашей системы:
Arch Linux, EndeavourOS и Manjaro Linux: sudo pacman -S rclone
Alpine Linux: sudo apk add rclone
Debian, Ubuntu, Linux Mint, Pop OS: sudo apt install rclone
Для RHEL и подобных систем может потребоваться сначала включить репозиторий [EPEL] с помощью следующей команды:
$ sudo dnf install epel-release
Для OpenSUSE используйте следующую команду:
$ sudo zypper install rclone
Установка
Чтобы установить Rclone сначала убедитесь, что у вас установлен Go версии 1.4 или более поздней. Следуйте руководству по установке Go в Linux, затем введите следующую команду:
$ go get github.com/rclone/rclone
Чтобы установить бета-версию, используйте следующую команду:
$ go get github.com/rclone/rclone@master
Установка пакета моментальных снимков Rclone
Чтобы установить пакет моментальных снимков Rclone, выполните следующую команду:
$ sudo snap install rclone —classic
Проверка версии Rclone
После установки Rclone вы можете проверить установленную версию с помощью команды:
$ rclone version
В результате будет показан номер версии и некоторая информация о системе, такая как операционная система, версия ядра и версия Go.
Обращение за помощью
Чтобы получить помощь по работе с Rclone, используйте одну из следующих команд:
$ rclone help
$ rclone -h
Эти команды отобразят список доступных команд и краткое описание каждой из них. Чтобы получить справку по конкретной команде, добавьте название команды в конец команды, как показано ниже:
$ rclone mount help
Это выведет справку по команде «mount».
Создание и настройка шаблонов в Zabbix
Шаблоны в Zabbix позволяют вам синхронизировать мониторинг группы хостов.
Создание шаблонов
Найдите вкладку “Конфигурация” — “Шаблоны”. Кликните на “Создать шаблон”. Установите имя для шаблона. Установите группу хостов для работы с этим шаблоном.
Настройка содержимого шаблона
Перейдите во вкладку “Шаблоны”, чтобы провести более гибкую настройку группы.
Для добавления какого-либо элемента, найдите его и отметьте галочкой, после кликните “Copy”.
Определите место копирования.
Назначение шаблонов для узлов сети
После создания шаблона, вы можете установить его для единственного хоста или для группы. “Конфигурация” — “Хосты”, найдите устройство, которому вы хотите назначить шаблон. Кликните на имя.
Во вкладке “Шаблоны”, на панели управления хостом, кликните “Выбрать”. Далее, нажмите на “Добавить”, это нужно для закрепления шаблона к хосту. Аналогичные действия проделайте с другими хостами.
Настройка и создание триггеров в Zabbix
Триггер — абстрактная метка, с помощью которой происходит отслеживание определенных событий и метрик в системах. У триггера в программной системе Zabbix существуют несколько состояний:
ок — система (элемент системы) в норме
проблема (возникает, когда триггер следит за изменениями метрики, срабатывает при превышении или понижении установленного порогового значения)
неизвестная внештатная ситуация — что-то произошло, система мониторинга не может классифицировать возникшую проблему
Инициализация триггеров
Найдите пункт “Конфигурация”, перейдите во вкладку “Хосты”, определите наблюдаемый узел, создайте триггер через вкладку “Триггер”. Заполните поля наиболее детальным и понятным образом, чтобы понимать релевантность триггера.
Поле “Выражение проблемы” отвечает за установку конкретного значения, которое впоследствии будет являться порогом изменения состояния триггера. Чтобы составить условие, функцию обработки события, откройте конструктор выражений. Выберите наблюдаемый элемент.
Нормальное состояние (ОК) означает стабильную работу элемента (или системы), без обработки триггеров. Вы можете принудительно отменить автоматическое изменения триггера в состояние OK, для этого выберите значение “Нет”.
У вас также есть возможность настроить режим генерации событий. Вы можете настроить оповещение о проблеме 1 раз или при каждом изменении состояния.
Опция “Ручное закрытие” позволит вам в ручном режиме управлять состояниями триггера. После того, как вы добавили триггер, перейдите в меню “Конфигурации”, после найдите пункт “Узлы сети”, далее “Триггеры”.
Установка Zabbix (Ubuntu 20.04 Vers.)
Zabbix — это программная система, предназначенная для мониторинга различных ИТ-инфраструктур, включая облачные сервисы, обычные сети и виртуальные частные серверы (VPS). Это решение с открытым исходным кодом является бесплатным и может использоваться для мониторинга широкого спектра параметров, таких как загрузка процессора, доступное место на жестком диске, ping, доступность хоста и загрузка сети. Оно также способно генерировать графики и отправлять предупреждения по результатам мониторинга.
Мониторинг Zabbix может быть реализован различными методами, включая использование программы-агента или задействование существующих ресурсов системы или устройства, таких как ICMP ping или SNMP. Это универсальная система, которая может отслеживать широкий спектр параметров, включая загрузку процессора, пространство на жестком диске, загрузку сети и доступность хоста. Zabbix также может строить графики данных и отправлять предупреждения для уведомления администраторов о потенциальных проблемах.
В настоящее время Zabbix обычно развертывается с использованием MySQL в качестве базы данных и Nginx в качестве веб-сервера на Ubuntu версии 20.04. Однако существуют и альтернативные варианты базы данных и веб-сервера, в зависимости от конкретных потребностей и предпочтений пользователя.
Подготовка
Для установки и настройки мониторинга Zabbix вам понадобится сервер под управлением Ubuntu 20.04 с доступом root. Многие команды в процессе установки требуют root-доступа, поэтому убедитесь, что вы вошли в систему как root или используете sudo. Хотя Zabbix включен в стандартные репозитории Ubuntu, это не самая последняя версия. К счастью, у Zabbix есть собственный репозиторий, который можно подключить с помощью одной команды:
create database zabbix character set utf8mb4 collate utf8mb4_bin;
Создайте аккаунт для работы с базой данных:
create user zabbix@localhost identified by ‘password’;
Инициализируйте права доступа, чтобы соединить Zabbix и БД:
grant all privileges on zabbix.* to zabbix@localhost;
Разрешите подстановку шаблона базы данных:
set global log_bin_trust_function_creators = 1;
quit;
Далее, скачайте шаблон конфигурации, введите пароль, который установили ранее
zcat /usr/share/zabbix-sql-scripts/mysql/server.sql.gz | mysql —default-character-set=utf8mb4 -uzabbix -p zabbix
Отключите режим логирования:
mysql -uroot -p
set global log_bin_trust_function_creators = 0;
quit;
Необходимо отредактировать содержимое файла конфигурации:
nano /etc/zabbix/zabbix_server.conf
Раскомментируйте “DBPassword=”, установите свой пароль. Чтобы быстро найти нужную строку, воспользуйтесь комбинацией Ctrl + W. Сохраните изменения.
Web-сервер: настройка
Измените файл /etc/zabbix/nginx.conf. Раскомментируйте строки с listen и server_name. listen 8080 — управляющий порт с интерфейсом Zabbix, его изменять не стоит, строку с server_name модифицируйте, впишите IP-адрес сервера на место с example.com.
Команда, позволяющая использовать интерфейс локали:
locale -a
Откройте файл по пути /etc/locale.gen, раскомментируйте строку с ru_RU.UTF8
Осуществите вход, используя установленные данные учетной записи:
Username: Admin
Password: zabbix
Nextcloud
Nextcloud — это бесплатное программное обеспечение с открытым исходным кодом, которое позволяет пользователям создать собственную систему облачного хранения данных. Она предлагает функции, аналогичные популярным облачным сервисам хранения данных, таким как Dropbox, Yandex Disk или iCloud, но с дополнительной гибкостью и контролем над тем, где и как хранятся файлы.
Характеристика Nextcloud
Изначально Nextcloud был форком Owncloud, но с тех пор он превратился в широко используемую и независимую платформу для облачного хранения данных. Чтобы использовать Nextcloud, необходимо установить серверное и клиентское программное обеспечение. Серверное программное обеспечение устанавливается на персональный или удаленный сервер, который может управляться и обслуживаться третьей стороной. Оно организует инфраструктуру для облачного хранения файлов и может быть дополнено дополнительным программным обеспечением для поддержки работы отдела или компании в целом, например, управления проектами, постановки задач, видеоконференций и сотрудничества с другими командами или компаниями, которые также используют Nextcloud.
Клиентское программное обеспечение можно установить на любое устройство под управлением Windows, macOS, Linux, iOS или Android. Оно позволяет загружать файлы с сервера и легко получать к ним доступ. Открытая архитектура Nextcloud позволяет легко добавлять новые функции и расширять его возможности в соответствии с конкретными требованиями бизнеса. Такая гибкость сделала Nextcloud популярным выбором среди компаний и частных лиц, которые ценят конфиденциальность, безопасность и контроль над своими данными.
Возможности
Когда речь идет об облачном хранилище, одним из самых важных моментов является безопасность данных. Nextcloud предлагает пользователям полный контроль над своими данными, позволяя хранить их на собственных серверах и настраивать параметры доступа и защиты. Кроме того, Nextcloud обладает надежной экосистемой, включающей более сотни бесплатных приложений, которые можно интегрировать и использовать совместно с платформой.
Nextcloud предоставляет несколько востребованных функций, таких как контролируемый доступ к файлам, который позволяет пользователям обмениваться папками или файлами по URL-ссылке с различными настройками доступа. Пользователи Nextcloud также могут совместно работать над файлами и документами, а установив Collabora Online, они могут редактировать популярные форматы документов.
Nextcloud также предоставляет возможности потоковой передачи мультимедиа, а встроенный медиаплеер позволяет пользователям передавать и воспроизводить загруженные видео на веб-страницах и мобильных устройствах. Платформа также поддерживает календари, контакты, заметки и задачи, которые можно синхронизировать между устройствами с помощью WebCAL, DAVdroid и приложения Nextcloud Notes.
Для тех, кто использует свои смартфоны в качестве основной камеры, Nextcloud предоставляет возможность автоматической загрузки фотографий и видео в определенные папки с индивидуальными настройками загрузки.
Nextcloud является кроссплатформенным, поэтому доступ к нему возможен на любой популярной операционной системе, а все функции доступны через веб-интерфейс. Для обеспечения безопасного доступа к данным он также предлагает варианты двухфакторной аутентификации, включая резервные коды, одноразовые пароли OTP и Yubikey.
В целом, Nextcloud представляет собой многофункциональное и хорошо настраиваемое решение для облачного хранения данных, которое отвечает широкому спектру потребностей.
NAS
NAS (Network-Attached Storage) стали популярным выбором для предприятий, ищущих эффективные, гибкие и доступные решения для хранения данных, которые обеспечивают бесперебойный доступ к данным по сети. В отличие от других серверов, серверы NAS быстрее получают доступ к данным, легче конфигурируются и более управляемы, что делает их привлекательным вариантом для предприятий любого размера.
Серверы NAS легко интегрируются в различные бизнес-процессы, поддерживая ряд приложений, таких как корпоративная электронная почта, бухгалтерские базы данных, бизнес-аналитика, системы видеонаблюдения и т. д. Благодаря гибкой масштабируемости системы NAS могут подстраиваться под размер и конкретные потребности компании, предлагая решения малой емкости для небольших бюджетов и устройства класса Hi-End для крупных предприятий.
Облачные решения на базе Nextcloud также становятся жизнеспособной альтернативой NAS в некоторых случаях. Эти решения недороги, просты в настройке и управлении и могут обеспечить те же преимущества, что и традиционные системы NAS.
В целом, системы NAS и решения на базе Nextcloud предлагают предприятиям надежный и экономически эффективный способ хранения и доступа к данным, помогая оптимизировать работу и поддерживать рост.
Возможности NAS
Серверы NAS становятся все более популярными благодаря своей способности обеспечивать надежный и бесперебойный доступ к хранилищу данных. Одним из наиболее очевидных преимуществ NAS является его способность хранить и управлять данными, позволяя пользователям создавать сетевые папки со своими файлами и получать к ним доступ с помощью стандартных протоколов Windows, таких как SMB.
Еще одной привлекательной особенностью NAS является возможность создания групп пользователей и управления правами доступа, которые можно использовать для ограничения доступа к определенным людям и файлам. Кроме того, системы NAS включают в себя общую корзину, которая обеспечивает временное хранение удаленных файлов, которые можно легко восстановить.
Помимо внутренних пользователей, NAS также позволяет внешним пользователям получать доступ к файлам и папкам через общие ссылки, что делает его идеальным решением для удаленной совместной работы. Кроме того, системы NAS обладают надежными возможностями резервного копирования, которые позволяют пользователям планировать резервное копирование или моментальные снимки, создавать несколько копий файлов и при необходимости легко восстанавливать предыдущие версии данных.
Облачные NAS-решения, такие как Nextcloud, позволяют командам работать совместно в едином хранилище, что делает их идеальным вариантом для удаленных команд и домашних офисов. Кроме того, компании могут использовать NAS-серверы для размещения инфраструктуры виртуальных рабочих столов, потоковых сервисов, тестирования и разработки веб-приложений.
В целом, привлекательность NAS заключается в его способности обеспечить надежное и безопасное хранение данных, гибкий контроль доступа и надежные возможности резервного копирования. Используя возможности NAS, компании могут оптимизировать свои операции, поддерживать рост и обеспечивать безопасность данных.
Архитектура NAS
Типичный NAS-сервер состоит из нескольких ключевых компонентов, включая физические диски, центральный процессор, операционную систему и сетевой интерфейс:
Физические диски отвечают за обеспечение высокой емкости хранения, обычно поддерживая от трех до пяти жестких дисков или твердотельных накопителей. Часть логических дисков отводится под создание избыточного массива независимых дисков (RAID-массив) для обеспечения избыточности данных и защиты от сбоев дисков.
Центральный процессор NAS, или CPU, отвечает за обеспечение необходимой вычислительной мощности для управления файловой системой, обработки данных для обслуживания хранящихся файлов, а также управления пользователями и интеграции облачной инфраструктуры.
Операционная система устройства NAS необходима для взаимодействия между оборудованием и пользователем через интерфейс. В то время как устройства NAS высокого класса обычно поставляются с предустановленной операционной системой, более простые или самостоятельно изготовленные устройства NAS могут потребовать ее установки.
Для подключения к сети устройство NAS использует сетевой интерфейс через Ethernet-соединение или Wi-Fi. Кроме того, серверы NAS часто оснащаются портами USB для зарядки или подключения других устройств к хранилищу.
В целом, сочетание физических дисков, мощного процессора, операционной системы и сетевого интерфейса делает NAS-серверы эффективным и надежным решением для хранения и управления данными.
Типы NAS
Когда речь заходит об устройствах NAS, выделяют несколько типов.
Серверные NAS-устройства бывают разных размеров и типов, например настольные или стоечные, и ими можно управлять и настраивать по сети.
Вертикально масштабируемые NAS-устройства обычно состоят из пары устройств хранения, управляемых парой контроллеров. Чтобы увеличить емкость такого хранилища, необходимо приобрести больше дисков NAS. Это связано с тем, что контроллеры имеют ограничения по производительности и емкости, и они могут эффективно управлять только ограниченным количеством дисков. Если вы превысите этот лимит, вам придется приобрести новое устройство NAS, в результате чего у вас будет несколько автономных файловых хранилищ, которые необходимо каким-то образом синхронизировать для распределения файловых данных.
С другой стороны, устройства NAS с горизонтальным масштабированием состоят из групп серверов, имеющих общий логический номер или общие файловые ресурсы, доступные по сети. Эти NAS-устройства также имеют контроллеры и диски, причем контроллеры объединяют несколько физических устройств в отдельный логический блок. Такая система масштабируется линейно, и ее производительность растет по мере увеличения емкости.
CentOS
CentOS — операционная система, основанная на ядре Linux, завоевала популярность как надежное серверное решение. Совместима с продуктами Red Hat, включая Red Hat Enterprise Linux, поскольку была разработана этой компанией. CentOS распространяется бесплатно, не имеет официальной коммерческой поддержки и разрабатывалась в основном сообществом.
Хотя CentOS в основном используется как серверная операционная система, ее можно применять и для обычных рабочих компьютеров, поскольку она может работать длительное время без проблем и обеспечивать длительную поддержку встроенного программного обеспечения. Для тех, кто знаком с серверными операционными системами, настройка CentOS интуитивно понятна.
История развития
CentOS произошла от cAos Foundation, которая разрабатывала независимые дистрибутивы GNU/Linux на основе RPM. Впервые она была представлена как часть сборки CAOS Linux двадцать лет назад, и уже через год один из проектов cAos Foundation «cAos-EL» была переименована в CentOS, а также был запущен сайт centos.org.
В 2005 году, после реорганизации cAos Foundation, CentOS была выделена в отдельное подразделение. В 2006 году к CentOS присоединилась компания, разрабатывающая серверный дистрибутив Tao Linux, также основанный на RHEL. К 2010 году треть всех веб-серверов Linux работала на CentOS, что сделало ее самой популярной системой в течение двух лет. Debian обогнал CentOS в 2012 году, но к тому времени дистрибутив уже привлек внимание нескольких крупных игроков.
В 2014 году Red Hat приобрела CentOS, и представители компании пообещали помочь в дальнейшем развитии платформы с открытым исходным кодом, чтобы повысить ее совместимость с требованиями разработчиков и новыми технологиями. Смена владельца пошла на пользу проекту, и CentOS остается стабильным лидером на рынке серверного программного обеспечения на протяжении последних 12 лет. За всю свою историю дистрибутив выпустил 8 версий, а девятая, CentOS Stream, была концептуально другим проектом, возникшим после слияния Red Hat с IBM.
В 2020 году Red Hat заявила, что все слияния и поглощения не повлияют на пользователей, но срок поддержки восьмой версии операционной системы был сокращен до 2021 года. Тем не менее, CentOS продолжает оставаться надежным и популярным выбором для пользователей, которым нужна стабильная и бесплатная альтернатива другим серверным решениям.
CentOS Stream 9 стал заменой CentOS 8 и RHEL 8, а функционирует по модели непрерывного обновления (rolling-release).
Версии CentOS
CentOS, популярный дистрибутив Linux, за время своего существования пережил несколько итераций. Версия 7.0 была выпущена в 2014 году с гарантированной поддержкой до 2020 года, а ее последнее критическое обновление было запланировано к выпуску на 30 июня 2024 года. Этот выпуск принес такие обновления, как ядро Linux версии 3.10.0, поддержка контейнеров Linux, драйверы 3D-графики и инструменты VMware. Эти функции сделали CentOS 7.0 популярным выбором для поставщиков облачных решений благодаря ее надежности и обновлениям безопасности.
В 2019 году разработчики Red Hat представили CentOS 8.0, пообещав поддерживать ее в течение десяти лет. Этот релиз включал более стабильное ядро Linux версии 4.18 и замену пакетного менеджера yum на более продвинутый Dandified YUM. Кроме того, nftables заменил iptables, что привело к повышению скорости обслуживания соединений. В CentOS 8.0, среди прочих особенностей, также была произведена замена движка docker на podman и SCL на appstream.
CentOS Stream, выпущенная в 2019 году, предоставила пользователям модель непрерывного обновления. Она изменила традиционную иерархическую модель разработки Fedora → RHEL → CentOS. CentOS стала тестовым продуктом, а не финальным стабильным релизом. CentOS Stream 9 имеет ядро Linux версии 5.14, поддерживает Python версии 3.9, использует 40-ю версию GNOME для рабочего стола и внедрил библиотеку OpenSSL 3.0 для повышения безопасности системы.
Хотя восьмая версия CentOS является наиболее распространенной, CentOS Stream завоевывает все больше сторонников. Возможно, компания продолжит развивать свой продукт в этом направлении.
API (Application Programming Interface)
API — технология прикладного программирования, который является инструментом для облегчения взаимодействия между приложениями и сервисами.
API определяет возможности программы, например, модуля или библиотеки, и обеспечивает уровень абстракции для реализации этих возможностей. Как правило, между компонентами устанавливаются иерархические отношения, при этом компоненты более высокого уровня используют API-интерфейсы компонентов более низкого уровня.
Одним из ключевых преимуществ использования API является возможность включения готового кода или уже существующих функций в конечный продукт. Это позволяет разработчикам легко использовать работу сторонних программистов без необходимости реализовывать все с нуля. Однако важно обеспечить правильное и безопасное использование API, поскольку неправильная реализация может привести к уязвимостям и рискам безопасности.
API, или интерфейсы прикладного программирования, состоят из двух основных компонентов:
части программного обеспечения с определенной функцией
отдельной части приложения или полного приложения.
Фрагментация отдельных частей обычно определяется тем, насколько независимым является компонент приложения. Это особенно характерно для API отдельных библиотек, которые взаимодействуют с остальной частью приложения или частями сайта.
API не включает скрытую логику приложения, поэтому разработчики вольны оставлять определенные области открытыми только для собственного использования. В приложении может быть множество взаимодействующих объектов, каждый из которых имеет свой API, представляющий собой набор свойств и методов для взаимодействия с другими объектами приложения.
Использование API в настоящее время широко распространено, и большинство интернет-ресурсов используют несколько API одновременно. API известны своей надежностью и широкой практикой интеграции, что делает их отраслевым стандартом для создания современных веб-сайтов и приложений.
FTP
FTP — протокол, предназначенный для транспортировки файлов. Год создания: 1971 год. Протокол применяется в основном в клиент-серверной архитектуре. Стоит отметить, что данный протокол, на ряду с HTTP, SMTP, DNS применяется для реализации прикладных задач.
Принцип работы
URL — механизм, используемый для файловой адресации в протоколе. Например, вам необходимо скачать какой-либо файл с сервера. Вы нашли URL, который содержит 3 части (1 часть — идентификатор FTP, 2 часть — имя сервера через DNS, 3 часть — точный путь для файла в системе). FTP задействует несколько соединений. 21 порт эксплуатируется для управления, а 20 порт отвечает за активную передачу данных.
При активном соединении FTP, сервер является основным инициатором. Со стороны сервера используется порт 20, со стороны клиента — порты, начиная с 1024. Если сервер пассивный в данном соединении, то клиент выполняет роль инициатора. Тогда, для сервера доступны порты, начиная с 1024.
Подключение состоялось. Теперь клиент может совершать взаимодействия с файлами, осуществлять серфинг по рабочим директориям и тд.
Аутентификация
FTP для использования предусматривает механизм аутентификации. Аутентификация происходит на основе ввода учетных данных (логина-пароля). Но есть и другой вариант. На FTP серверах возможна опция “анонимный пользователь”. При анонимной аутентификации вы ограничены в правах доступа.
FTP в наше время
Протокол удобен и прост в использовании. Однако, в современных реалиях, использование FTP — рискованное решение, потому что протокол обладает низким уровнем безопасности. Учетные данные во время соединения не шифруются. Преимущественно, корпоративные структуры делают выбор в сторону более конфиденциального SSH (альтернативы — SFTP/SCP).
Хорошим решением будет использование FTP внутри доверенной локальной среды, где не содержатся критически важные данные. Например, для организации передачи данных с компьютера на телевизор (общий файловый сервер). Чтобы создать сервер FTP, вам необходимо настроить персональный компьютер. В Windows/MacOS есть возможность выбрать роль-конфигурацию для FTP-сервера.
Для Linux, используйте пакет vsFTPd.
Как защитить сервер: 6 практических методов
Для обеспечения безопасности сервера всегда требуется сочетание различных мер. Эти меры можно условно разделить на следующие категории:
Защита каналов связи, используемых для администрирования и использования системы.
Реализация нескольких уровней безопасности для системы.
Контроль доступа и разделение ресурсов для инфраструктуры.
Мониторинг и аудит систем.
Регулярное резервное копирование.
Своевременное обновление (или откат) программного обеспечения и антивирусной защиты для серверов.
Давайте теперь рассмотрим 6 практических методов, которые помогут достичь высокого уровня защиты от потенциального злоумышленника.
Управление доступом
Управление доступом — процесс, требующий ответственного отношения. Главный принцип заключается в распределении информации между группами пользователей таким образом, чтобы информация была доступна только в соответствии с необходимостью получить доступ к этой информации.
Всегда инициализируйте отдельную запись для администратора с привилегированными правами, чтобы контролировать другие записи. При работе с системами типа Active Directory контролируйте политики безопасности для корпоративных групп, чтобы не допустить утечек информации.
Для работы в unix-системах рекомендуется использование sudo. Ниже приведены две полезные отметки по умолчанию, которые помогут отслеживать, кто и что делает через sudo.
В базовом случае в журнал записывается в syslog. Следующая настройка (в файле /etc/sudoers) для удобства накапливает записи в отдельном файле:
По умолчанию log_host, log_year, logfile=»/var/log/sudo.log».
Этот параметр указывает sudo записывать текст сессии (журналы команд, сообщения stdin, stderr, stdout и tty/pty) в каталог /var/log/sudo-io:
По умолчанию log_host, log_year, logfile=»/var/log/sudo.log».
Более подробная информация о работе с файлом sudoers представлена в отдельной статье.
Доступ на основе мандатов
Следующий совет относится к системам Linux. Администраторы систем Linux полагаются исключительно на внешние механизмы контроля доступа, которые являются базовыми и всегда активными. Однако многие дистрибутивы (такие как AppArmor в Ubuntu и SELinux в системах на базе RHEL) имеют обязательные механизмы контроля доступа. У системного администратора возникают сложности управления внутренними опциями безопасности, потому что порой для этого требуются многочисленные службы ОС и инициализация сложных демон-процессов.
Удаленное управление операционной системой
При удаленном администрировании ОС приоритетная задача — интегрирования и использование безопасных протоколов. В ОС Windows используется RDP, в Linux — SSH, данные протоколы обеспечивают вполне безопасное соединение в сети. Для создания безопасности в условиях корпоративной инфраструктуры этого недостаточно.
Устанавливайте соединение по RDP с паролем. Это можно сделать через «Локальные политики безопасности» и «Учетные записи: Разрешить удаленные подключения к этому компьютеру». Транспортный протокол TLS поможет вам поддержать конфиденциальность соединения, если вы не работаете в частной сети (VPN).
Для SSH соединения по классике необходим пароль. Чтобы аутентифицировать соединение, вы вводите пароль, подтверждающий доверенность. Лучше использовать ассиметричное шифрование (пары ключей). Чтобы инициализировать соединения с помощью ключей:
Сгенерируйте пару ключей на локальной машине:
ssh-keygen -t rsa
Поместите ключи на удаленную машину:
ssh-copy-id username@address
Если вы предпочитаете не использовать ключи, подумайте об использовании Fail2ban, программы, которая ограничивает количество попыток ввода пароля и блокирует IP-адреса. Также рекомендуется изменить порты по умолчанию, например, 22/tcp для SSH и 3389/tcp для RDP.
Управление файрволом
Чтобы обеспечить надежную защиту, системы безопасности должны иметь несколько уровней защиты. Одним из эффективных методов защиты является контроль сетевых соединений до того, как они достигнут служб. Для этой цели используются брандмауэры.
Брандмауэр, также известный как система защиты периметра, контролирует доступ к компонентам инфраструктуры на основе заранее определенных правил. Он пропускает только тот трафик, который соответствует этим правилам, и блокирует весь остальной трафик. В Linux брандмауэр является частью ядра (netfilter), но для его работы в пространстве пользователя необходимо установить внешний модуль, такой как nftables, iptables, ufw или firewalld.
Основная задача при настройке брандмауэра — закрыть неиспользуемые порты и открыть только те, которые требуют внешнего доступа, например, порты 80 (http) и 443 (https) для веб-сервера. Хотя открытый порт сам по себе не представляет угрозы безопасности, он может стать уязвимым местом, если на нем работает уязвимое программное обеспечение. Поэтому лучше удалить ненужные порты.
Брандмауэры также помогают сегментировать инфраструктуру и контролировать трафик между сегментами. Если вы используете публичные сервисы, рекомендуется изолировать их от внутренних ресурсов в DMZ. Кроме того, следует обратить внимание на системы обнаружения и предотвращения вторжений (IDS/IPS), которые блокируют угрозы безопасности и пропускают весь остальной трафик.
TLS и инфраструктура открытых ключей
Протоколы передачи данных, такие как HTTP, FTP и SMTP, были разработаны во времена, когда сети использовались в основном для передачи информации между военными и научными учреждениями. Эти протоколы представляют данные в формате обычного текста, что не обеспечивает достаточной безопасности при передаче конфиденциальной информации.
Для обеспечения безопасности веб-сайтов, внутренних панелей управления и электронной почты рекомендуется использовать протокол Transport Layer Security (TLS). Этот протокол был разработан для защиты передачи данных по незащищенным сетям.
TLS обеспечивает конфиденциальность, целостность и аутентификацию передаваемых данных. Аутентификация достигается с помощью цифровых подписей и инфраструктуры открытых ключей (PKI).
Для аутентификации сервера TLS использует SSL-сертификат, подписанный центром сертификации (ЦС). Сертификаты ЦС, в свою очередь, подписываются ЦС более высокого уровня и так далее. Сертификаты корневого ЦС являются самоподписанными, что означает, что по умолчанию они считаются доверенными.
TLS можно использовать в сочетании с VPN для обеспечения дополнительного уровня безопасности при передаче данных. В этом случае необходимо самостоятельно организовать инфраструктуру PKI в локальной сети, включая сервер CA, ключи и сертификаты узлов.
VPN
В современную цифровую эпоху VPN становятся все более популярными среди пользователей Интернета. VPN создает защищенный логический сетевой уровень, который накладывается на другую сеть, например Интернет, обеспечивая безопасное соединение между филиальными сетями организаций с помощью криптографических методов. Таким образом, безопасность VPN-соединения не зависит от безопасности базовой сети.
Существует множество протоколов VPN, каждый из которых подходит для организаций разного размера, их сетей и требуемого уровня безопасности. Например, протокол PPTP подходит для небольшой компании или домашней локальной сети, хотя в нем используются устаревшие методы шифрования. Для обеспечения более высокого уровня безопасности наиболее подходящими являются протоколы IPsec, OpenVPN и WireGuard, в зависимости от типа соединений, которые требуется установить.
Важно помнить, что настройка специфических протоколов, таких как IPsec, OpenVPN и WireGuard, может потребовать дополнительных знаний и навыков. Поэтому при настройке этих протоколов рекомендуется обращаться за помощью к знающим специалистам.
Угрозы безопасности
Угрозы информационной безопасности можно разделить на несколько типов, каждый из которых имеет свои особенности и степень опасности.
Первый тип
Одной из основных угроз, связанных с осуществлением несанкционированной деятельности сетевой системы, особенно за пределами периметра безопасности, является возможность получения хакерами доступа к учетным записям авторизованных пользователей. Это дает им возможность просматривать конфиденциальную информацию или манипулировать конфигурацией системы. Это может произойти в результате взлома учетных записей с привилегированным доступом, включая учетные записи администраторов в операционной системе. Этот тип атаки считается наиболее опасным, поскольку может поставить под угрозу всю инфраструктуру.
Второй тип
Другой тип атак направлен на вывод системы из строя, и хотя он не связан с утечкой данных, все же может нанести значительный ущерб предприятию. Например, атаки Denial-of-Service (DoS) и Distributed Denial-of-Service (DDoS) подразумевают отправку огромного количества запросов на серверы, перегружая их и вызывая отказ в обслуживании. В таких случаях пользователи не могут получить доступ к ресурсам и услугам, что приводит к значительному финансовому и репутационному ущербу.
Итог
Результатом успешных атак могут быть утечки данных, финансовые потери и ущерб репутации компании. Поэтому при проектировании и настройке IT-инфраструктуры необходимо уделять должное внимание обеспечению безопасности и минимизации возможных угроз.
iSCSI-протокол: как работает, для чего используется и как подключить
Принцип работы
Для того чтобы понять принцип работы iSCSI, необходимо более подробно изучить его структуру. Основными компонентами здесь являются инициаторы и цели. Инициаторами называются хосты, которые устанавливают соединение по iSCSI, а цели (также используется термин «таргеты» от англ. «target») — это хосты, которые принимают это соединение. Целями являются хранилища данных, с которыми взаимодействуют хосты-инициаторы.
Связь между инициатором и целью устанавливается через TCP/IP, а iSCSI занимается обработкой команд SCSI и сбором данных, формируя пакеты. Затем эти пакеты передаются через двухточечное соединение между локальным и удаленным хостами. iSCSI разбирает полученные пакеты и разделяет команды SCSI. Такая работа протокола приводит к тому, что операционная система видит хранилище как локальное устройство и имеет возможность стандартного его форматирования.
Аутентификация и передача данных
iSCSI использует специальные имена, называемые IQN (iSCSI Qualified Names) и EUI (Extended Unique Identifiers, 64-битные идентификаторы, используемые в IPv6) для идентификации инициаторов и целей.
Примером IQN является «iqn.2003-02.com.site.iscsi:name23». Цифры «2003-02» после «iqn» означают год и месяц, когда было зарегистрировано доменное имя «site.com». Доменные имена в IQN записаны в обратном порядке. Наконец, «name23» — это имя, присвоенное узлу iSCSI.
Примером EUI является «eui.fe9947fff075cee0». Это шестнадцатеричное значение в формате IEEE. Верхние 24 бита EUI идентифицируют конкретную сеть или компанию (например, провайдера), а остальные 40 бит идентифицируют конкретный хост в этой сети и являются уникальными.
Каждый сеанс в iSCSI состоит из двух этапов. Первый этап — это аутентификация с TCP. Если аутентификация прошла успешно, начинается второй этап – обмен данными между хостом-инициатором и целевым хранилищем по одному соединению, что устраняет необходимость параллельного мониторинга запросов. После завершения передачи данных соединение закрывается с помощью инструкции iSCSI logout.
Обработка ошибок, безопасность
iSCSI обеспечивает восстановление утерянных сегментов данных, используя повторную передачу пакетов PDU, восстановление соединения и перезапуск сессии с отменой, попутно отменяя все незавершенные процессы. Для обеспечения безопасности передаваемых данных iSCSI использует CHAP-протокол, который основан на трансмиссии конфиденциальных данных, путем сопоставления хеш-значения. Все пакеты шифруются и проверяются на целостность с помощью протоколов IPsec. Это обеспечивает надежность и безопасность передачи данных между хостами-инициаторами и хранилищами-целями.
Преимущество использования
Протокол iSCSI — удобное решение для хранения данных в сети с улучшенной производительностью и рядом других преимуществ. В частности, он облегчает работу с сетевым хранилищем, используя уже существующую инфраструктуру сети, основанную на устройствах Gigabit Ethernet. Это значит, что отсутствует необходимость подготавливать устройства к использованию, следовательно вы экономите ресурсы.
iSCSI использует принципы,схожие с TCP/IP, что упрощает процесс настройки и использования систем хранения данных для технического персонала и снижает затраты на обучение.
Подключение
Для оптимальной работы протокола iSCSI рекомендуем использовать неблокирующий коммутатор Gigabit Ethernet корпоративного уровня, который обеспечит высокую скорость соединения. Подключение iSCSI не сложно, однако процедура может отличаться в Windows и Linux-подобных системах. Наша компания предоставляет готовые инструкции для обеих ОС:
В этом руководстве вы найдете подробные инструкции по подключению iSCSI-диска с описанием различий между ОС Ubuntu/Debian и CentOS.
Здесь мы подробно рассказываем, как подключить iSCSI-диск в Windows (на примере Windows Server 2016).
Мы также предлагаем услугу заказа сетевого iSCSI-диска объемом от 0,25 до 30 Тб. Подробности об услуге можно найти на нашей странице.
Для обеспечения мультисерверного соединения с хранилищем рекомендуем использовать MPIO-технологию (многопутевой ввод-вывод), которая помогает реализовать отказоустойчивость сети и ее избыточность.
Сравнение iSCSI/Fibre Channel
При сравнении двух протоколов передачи данных iSCSI и Fibre Channel (FC) часто ставится вопрос о конкуренции между ними. Однако, следует отметить, что нет абсолютно идеальных решений. Протоколы содержат некоторые преимущества и недостатки, которые могут варьироваться в зависимости от задачи.
iSCSI SAN — выгоднее с точки зрения экономики и холодного старта для использования. Это связано с тем, что для построения iSCSI SAN можно использовать существующее сетевое оборудование без необходимости дополнительных затрат на приобретение дорогостоящего оборудования.
При этом, iSCSI значительно улучшает передачу трафика, управление очень большими данными и оптимизацию хранения.
Для достижения максимальной производительности iSCSI все еще требуется использование специализированных сетевых адаптеров. В то же время, FC всегда требует наличия дополнительного оборудования, такого как коммутатор и адаптер шины. Это может привести к дополнительным затратам на приобретение и обслуживание оборудования.
Таким образом, при выборе между iSCSI и FC необходимо учитывать не только финансовые аспекты, но и требования к производительности и возможные затраты на оборудование.
Чтобы было проще сравнивать эти два протокола, мы составили таблицу их ключевых различий:
Feature
iSCSI SAN
Fibre Channel SAN
Can be used in existing network
Yes
No
Data transfer speed
1-100 Gbps
2-32 Gbps
Can be built on existing equipment
Yes
No
Data transfer flow control
No protection against packet retransmission
Reliable
Network isolation
No
Yes
Заключение
Сравнительная таблица подчеркивает уникальные особенности каждого протокола, подчеркивая важность выбора правильного протокола для ваших потребностей в хранении данных. Одним словом, выбор iSCSI в качестве основного метода организации хранилища полностью оправдан, если вам необходимо оптимизировать затраты и обеспечить простоту настройки и использования протокола. С другой стороны, FC может предложить низкую задержку, удобную масштабируемость и лучше подходит для организации разветвленной сети хранения.
Установка, настройка и примеры синхронизации Rsync
Rsync — инструмент, используемый для создания бэкапов и восстановления данных при возникновении внештатных аварийных ситуаций. Утилита может быть установлена на тех узлах, развертка которых происходила в ручном режиме. Например, если пользователь оплатил доступ к физическому серверу у такого провайдера, как Obit, и самостоятельно развернул виртуальную машину и другие сервисы.
Дистрибутив Rsync для Linux CentOS 8 доступен в официальном репозитории операционной системы и может быть установлен с помощью следующей команды:
dnf -y install rsync rsync-daemon
Это автоматически установит клиентский и серверный компоненты утилиты, включая демон-процесс Rsync, позволяющий в омниканально управлять потоком данных.
Чтобы открыть файл конфигурации для редактирования, например, с помощью редактора nano, выполните следующую команду:
nano /etc/rsyncd.conf
Файл содержит следующие переменные:
pid файл — файл, в котором система будет хранить идентификаторы процессов демона;7
lock file — файл, созданный для предотвращения дублирования запусков программы Rsync;
log файл — журнал, используемый для записи происходящих событий;
path — ссылка на каталог, который необходимо синхронизировать;
hosts allow — белый список удаленных машин, к которым разрешено подключение;
hosts deny — черный список хостов, которым запрещено передавать данные;
list — флаги для разрешения или запрета доступа к указанному каталогу;
uid — логин учетной записи, используемой для синхронизации;
gid — группа пользователей, имеющих разрешение на выполнение резервного копирования;
только чтение — флаг, защищающий данные от удаления или изменения;
комментарий — описание конфигурации.
Дополнительную информацию можно найти в документации.
В строках uid и gid рекомендуется использовать непривилегированные учетные записи (учетные записи пользователей для специализированных задач). Такой подход упрощает контроль доступа к функционалу для сотрудника и позволяет сохранить настройки при изменении обычными пользователями. После сохранения изменений в конфигурационном файле утилита готова к запуску, для чего необходимо создать указанный каталог:
mkdir /tmp/share
Запустить программу можно с помощью следующей команды:
systemctl enable —now rsyncd
Перед использованием рекомендуется настроить политики безопасности. В противном случае при обращении утилиты к хосту может возникнуть блокировка на межсетевого экрана или службы SELinux. Этого можно добиться с помощью следующей последовательности команд:
setsebool -P rsync_full_access on
firewall-cmd —add-service=rsyncd —permanent
firewall-cmd -reload
Текущее состояние Rsync можно проверить с помощью следующей команды:
systemctl status rsyncd
Синтаксис
Общий синтаксис для Rsync следующий:
rsync -options <source> <destination>.
Параметры — это показатели для запуска программы, источник –- это ресурс, который является источником для синхронизации, а место назначения — это каталог-получатель, куда будут реплицированы синхронизированные файлы и каталоги.
Список опций Rsync:
-v, -verbose — отображает процесс синхронизации на экране.
-q, -quiet — подавляет вывод сообщений об ошибках.
-c, -checksum — сравнивает контрольную сумму файлов вместо даты, времени и размера как индикаторов изменений файлов.
-a, -archive — активирует поддержку архивирования данных.
-r, -recursive — использует рекурсивный режим для копирования каталогов.
-b, -backup — обновление исходных файлов и создание резервной копии.
-backup-dir=<каталог> — указывает место хранения резервных копий.
-suffix=SUFFIX — добавляет дополнительный символ к файлам резервных копий.
-u, -update — пропускает файлы с более поздней датой модификации.
-l, -links — сохраняет символические ссылки.
-H, hard-links — сохраняет жесткие ссылки.
-p, -perms — сохраняет права доступа к файлам или каталогам.
-E, -исполнимость — сохраняет разрешения на выполнение для файлов.
-chmod=<разрешения> — изменяет разрешения на указанные после копирования объекта.
-o, owner — сохраняет информацию о владельце исходного файла или каталога.
-g, group — сохраняет информацию о владельце группы исходного файла или каталога.
-S, -sparse — дефрагментировать данные при копировании.
-n, -dry-run — тестирует только канал резервного копирования.
-W, -whole-file — всегда копирует файлы целиком, а не только их измененные части.
-delete — считает файлы, отсутствующие в источнике, старыми и удаляет их.
-delete-before — полностью очищает принимающий каталог перед синхронизацией.
-max-delete=<число файлов> — ограничивает максимальное число удаляемых файлов.
-max-size=<размер файла> — ограничивает максимальный размер копируемых файлов.
-min-size=<размер файла> — ограничивает минимальный размер копируемых файлов.
-z, -compress — сжимать файлы при передаче на удаленный сервер.
-compress-level=<число> — устанавливает уровень сжатия.
-exclude=<имена файлов> — передает указанные файлы без архивации.
-exclude-from=<имя файла> — исключает список файлов из синхронизации.
-version — отображает текущую версию утилиты Rsync.
Примеры использования
Наиболее популярные команды — копирование файлов, синхронизация целых каталогов из источников, в том числе по каналам SSH. Пользователи активно используют отображение хода операции, ограничивают скорость передачи, чтобы не забивать канал связи.
Копирование файлов
Рассмотрим в качестве примера локальное применение утилиты Rsync. В этом случае источник и приемник (речь идет о каталогах) будут принадлежать одному диску:
Во втором случае необходимо предварительно настроить доступ к ключу.
Синхронизация по SSH и демон Rsync
По умолчанию программа использует протокол безопасной передачи данных SSH (Rsync over SSH). Для его активации не требуется никаких дополнительных параметров. Благодаря этой функции можно получить прямой доступ к демону Rsync без использования сторонних утилит. Пример обращения:
Большие объемы данных лучше передавать с визуальным контролем прогресса. Это позволит убедиться, что все файлы и каталоги действительно были синхронизированы. Пример команды для включения Rsync Progress:
rsync -avzhHl —progress /path/of/source/folder
root@192.168.43.10:/path/to/destination/folder
Удаление файлов во время синхронизации
По умолчанию в каталоге назначения хранятся все файлы, ранее скопированные туда. Даже те, которые пользователь давно удалил с рабочего диска как ненужные. Поэтому рекомендуется периодически удалять ненужные данные, а не уменьшать объем резервной директории. Пример команды:
rsync -avzhHl —delete /path/of/source/folder
root@192.168.56.1:/path/to/destination/folder
Ограничение скорости передачи данных
Часто канал связи имеет ограниченную пропускную способность, так как используется для решения ряда других задач. Или планируется использовать в ближайшем будущем. Для этого процесс копирования снижается в приоритете путем ограничения максимальной скорости обмена данными. Команда:
Иногда выгоднее отказаться от резервного копирования больших файлов. Такой подход актуален, если они носят в основном временный характер, когда на удаленный хост передаются только результаты просчитанных проектов. Пример команды:
Процесс синхронизации проходит быстрее всего, когда пользователь создает список файлов, наиболее важных для бесперебойной работы. Остальные остаются только на исходном диске. Пример указания конкретных имен:
В этой инструкции мы рассмотрим семь простых шагов для установки и настройки NTP-сервера в Ubuntu. Мы будем работать в командной строке и использовать редактор nano, а также терминал, который открывается по нажатию Ctrl+Alt+T.
Шаг 1: Индекс репозитория
Обновление индекса репозитория Перед установкой NTP-сервера необходимо обновить индекс репозитория. Для этого выполните следующую команду:
sudo apt-get update
Шаг 2: Сервер
Установка сервера Установка сервера начинается с выполнения следующей команды:
sudo apt-get install ntp
Перед выполнением этой команды убедитесь, что у вас есть права суперпользователя. Чтобы разрешить установку всех необходимых компонентов, введите Y (Yes). После того, как вы установили сервер, приступим к его настройке.
Шаг 3: проверяем установку
Не обязательно, но желательно проверить, что установка прошла успешно. Выполните в терминале следующую команду:
sntp —version
Если установка прошла успешно, то вы увидите номер версии и точное время установки.
Шаг 4: поиск пула
По умолчанию серверная машина должна получать корректное время, но для большей надежности лучше переключиться к ближайшей группе серверов. Для этого нужно отредактировать конфигурационный файл ntp.conf, который находится по пути /etc/ntp.conf. Откройте его при помощи nano (у вас должны быть права sudo), для этого выполните команду:
sudo nano /etc/ntp.conf
В файле, который открылся, найдите строки, которые выделены оранжевым прямоугольником на изображении ниже:
Эти строки являются стандартными пулами, которые мы заменим на российские пулы, представленные на этой странице. Замените их, после сохраните изменения в ntp.conf, нажав Ctrl+O, а затем выйдите из файла, нажав Ctrl+X.
Шаг 5: перезагрузка
Перезапустите сервер.
sudo service ntp restart
Шаг 6: проверка и отладка
После перезапуска сервера необходимо убедиться, что он запустился успешно. Для этого выполните следующую команду:
sudo service ntp status
Шаг 7: настройка брандмауэра
Чтобы ваши клиенты могли выполнять вход на сервер, откройте им доступ с помощью изменения параметра UFW, прокинув UDP-порт 123 следующей инструкцией:
sudo ufw allow from any to any port 123 proto udp
Часть 2. Настраиваем синхронизацию NTP-клиентов
Для того, чтобы клиент мог синхронизироваться с вашим NTP-сервером, который будет служить эталонным источником времени, необходимо выполнить следующее.
Шаг 1: Проверка соединения
Чтобы проверить настройки сети NTP нужно ввести следующую команду в терминале:
sudo apt-get install ntpdate
Шаг 2: Указание IP и хоста
Чтобы указать IP и хост, необходимо отредактировать файл hosts, который находится по пути /etc/hosts, используя следующую команду:
sudo nano /etc/hosts
Затем, в третьей строке сверху, добавьте актуальные данные (адрес добавлен просто для примера, введите реальный IP своего NTP-сервера):
192.168.154.142 ntp-server
После этого следует нажать Ctrl+X и сохранить изменения, нажав Y. Обратите внимание, что эту процедуру можно выполнить и на DNS-сервере, если он у вас есть.
Шаг 3: Проверка синхронизации клиента с сервером
Чтобы проверить синхронизацию между системами сервера и клиента нужно ввести следующую команду:
sudo ntpdate ntp-server
Значение, которое будет выведено на экран — смещение времени. Погрешность в несколько миллисекунд считается нормальным, поэтому на такие цифры не стоит акцентировать внимание.
Шаг 4. Отключите службу timesyncd
Служба timesyncd синхронизирует локальное системное время, но в нашей установке она не нужна, поскольку клиенты будут синхронизироваться через NTP-сервер. Поэтому мы вводим:
sudo timedatectl set-ntp off
Шаг 5: Установите NTP на клиентской системе
Это делается с помощью инструкции:
sudo apt-get install ntp
Шаг 6: Сделайте наш NTP-сервер источником ссылок
Мы хотим, чтобы клиенты синхронизировались именно с нашим NTP-сервером, поэтому открываем знакомый нам конфигурационный файл ntp.conf и добавляем инструкцию следующего вида:
server NTP-server-host prefer iburst
Prefer добавляется для того, чтобы указать предпочтение (в данном случае, для сервера). В свою очередь, iburst позволяет отправлять несколько запросов на сервер, что повышает точность синхронизации. Теперь снова нажимаем Ctrl+X и сохраняем изменения, нажав y.
Шаг 7: Перезапустите сервер
Эта инструкция также проста и не требует объяснений:
sudo service ntp restart
Шаг 8: Проверьте очередь синхронизации
Почти завершили, осталось ввести инструкцию:
ntpq -ps
Она понадобится нам для проверки NTP-сервера, который указан в качестве источника в очереди синхронизации времени.
Часть 3. Продвинутые возможности синхронизации
В третьей части мы рассмотрим расширенные опции синхронизации в NTP. После установки и настройки NTP сервера и синхронизации клиентских машин с ним, мы можем более тонко настроить процесс синхронизации с помощью дополнительных параметров в файле ntp.conf, расположенном по адресу /etc/ntp.conf.
Предпочитаемый сервер
Отметка «prefer» используется для указания сервера или пула серверов, которые считаются наиболее надежными. Например:
server 1.ru.pool.ntp.org prefer
Отметка «server» используется для указания сервера, а директива «pool» – для указания пула серверов. Кроме того, строка «server 127.127.1.0» в конце списка пулов используется для получения системного времени при отсутствии соединения.
Настройки безопасности
Одна из команд «restrict default» устанавливает значения по умолчанию для всех команд «restrict», применяясь ко всем ограничениям. «kod» используется для отправки «поцелуя смерти» серверам, которые посылают слишком много запросов.
Другие команды, такие как «notrap», «nomodify», «nopeer» и «noquery», устанавливают ограничения на реализацию команд управления, изменения состояния, синхронизацию с определенными хостами.
Пример использования некоторых из описанных выше команд для синхронизации узлов в сети и ограничения доступа к изменению состояния и командам управления представлен в следующей строке: restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
Также в конфигурационном файле присутствуют ограничения, позволяющие серверу общаться с самим собой, используя адреса 127.0.0.1 и ::1.
Важно помнить, что после внесения изменений в конфигурационный файл необходимо перезапустить сервер для их применения
Проверяем корректность работы NTP
Чтобы проверить, правильно ли настроен NTP-сервер в системе Linux, можно воспользоваться командой «ntpq -p». Если настройки верны, результатом будет таблица со столбцами, выглядящая примерно так:
В первом столбце указан адрес сервера синхронизации, за ним следует восходящий сервер, level (столбец st) и nup (столбец t). Следующие три столбца показывают информацию о последней проверке серверов, периоде синхронизации и их надежности (значение 377 означает 8 успешных синхронизаций с сервером). Последние два столбца показывают разницу между синхронизированным временем и временем главного (эталонного) сервера, а также смещение времени.
Кроме того, обратите внимание на символы в первом столбце, которые появляются перед IP-адресом. Лучшим символом является «+», который указывает на надежность сервера для синхронизации. Соответственно, «-» указывает на обратное, а «*» — на текущий сервер, выбранный для синхронизации. Иногда встречается символ «x», который означает, что сервер недоступен.
Чтобы проверить, правильно ли сервер предоставляет время, необходимо использовать команду «ntpdate» на другой системе, указав IP-адрес проверяемого сервера. Вывод:
adjust time server (IP address) offset 0.012319 sec
Число здесь указывает на расхождение по времени. В данном случае все в норме, и разница составляет всего около 0,01 секунды, или, точнее, 12 миллисекунд, что вполне приемлемо.
Теперь давайте рассмотрим, как настроить протокол NTP в Windows.
Настройка NTP сервера Windows Server
Чтобы настроить NTP (Network Time Protocol) на компьютере, нужно выполнить несколько команд для изменения реестровой политики. Прежде чем приступить к изменению конфигурации, необходимо запустить службу. Это делается путем изменения следующей записи в реестре:
В этой ветке найдите «Enabled» и установите его в значение 1, чтобы запись в колонке Data выглядела так:
0x00000001 (1)
Откройте терминал и введите команду, необходимую для перезапуска протокола:
net stop w32time && net start w32time
Обратите внимание, что вводить команду нужно из папки C:\Users\Administrator. Вы можете проверить, включен ли NTP, с помощью следующей команды:
w32tm /query /configuration
Появится длинная запись, в которой следует обратить внимание на блок NtpServer <Local>: значение Enabled в строке должно быть равно 1. Теперь откройте брандмауэр для UDP-порта 123, чтобы правильно обслуживать клиентов, а затем переходите к конфигурации.
В этой ветке довольно много параметров, но основным является «Type», который принимает одно из 4 значений:
NoSync — без синхронизации;
NTP — синхронизация с внешними серверами, указанными в NtpServer в реестре (устанавливается по умолчанию для отдельной машины);
NT5DS — синхронизация в соответствии с иерархией домена (устанавливается по умолчанию для машины в домене);
AllSync — синхронизация со всеми доступными серверами.
Теперь снова обратитесь к реестру и установите значения в ветке NtpServer. Скорее всего, там указан только сервер Microsoft. Вы можете добавить другие, обращая внимание на флаг в конце:
0x2, UseAsFallbackOnly, для использования сервера в качестве резервного;
0x4, SymmetricActive, этот режим является основным для NTP-серверов;
0x8, Client, в случае проблем с синхронизацией.
И, наконец, что вам нужно сделать, это установить интервал синхронизации в ветке:
W32Time\TimeProviders\NtpClient
Это контролируется параметром «SpecialPollInterval», где необходимо установить требуемое значение (указывается в секундах). По умолчанию значение установлено на неделю. Если вы хотите синхронизироваться чаще, установите 86400 для 1 дня, 21600 для четверти дня (6 часов) и 3600 для часа. Последнее значение является оптимальным с точки зрения соотношения нагрузки на систему и приемлемой точности там, где требуется частая синхронизация времени.
Настройка NTP сервера Cisco
Корректное настройка времени на устройствах Cisco является важным аспектом обеспечения безопасности и эффективной работы сети. Неправильно настроенное время может привести к ошибкам в журналах событий и синхронизации сетевых служб, что может повлиять на работоспособность приложений, работающих в сети.
Шаги по настройке времени на устройствах Cisco довольно просты и легко выполнимы даже для непрофессионалов.
Для начала необходимо войти в режим конфигурирования, используя команду «conf t».
Следующий шаг заключается в установке часового пояса с помощью команды «clock timezone». Настройка часового пояса позволяет устройству корректно отображать локальное время. Если, например, время московское, установите «MSK 3».
Затем, необходимо указать источник NTP с помощью команды «ntp source». NTP (Network Time Protocol) является протоколом сетевого времени, который синхронизирует время на устройствах в сети. Если вы хотите сделать это устройство основным NTP-сервером для других машин в сети, установите значение в команде «ntp master» равным 2 или выше.
Для обновления времени используйте команду «ntp update-calendar». Эта команда применяется для сохранения текущего времени в часах устройства, которые могут быть использованы при перезагрузке устройства.
Затем, необходимо указать имена или IP-адреса серверов NTP. Для этого используйте команду «ntp server».
Для проверки проблем и устранения неполадок, можно использовать команду «show». С помощью команды «show clock» можно отобразить текущее время устройства, а команда «show ntp status» покажет состояние NTP. Команда «show ntp associations» отобразит ассоциации, т.е. устройства, с которыми устройство взаимодействует для синхронизации времени.
Таким образом, правильная настройка времени на устройствах Cisco является необходимой для корректной работы сети и обеспечения безопасности. Данный процесс довольно прост и может быть выполнен даже непрофессионалом, следуя вышеописанным шагам.
Настройка NTP-сервера на роутерах MikroTik
Давайте настроим SNTP: Для настройки времени на устройствах с операционной системой MikroTik RouterOS необходимо выполнить несколько шагов.
Сначала перейдите в раздел System — SNTP Client в программе Winbox. Затем найдите опцию SNTP Client и установите флажок Enabled, чтобы включить клиент SNTP.
Далее, введите IP-адреса эталонных серверов в поле Server DNS Names. Это позволит вашему устройству получать точное время от выбранных серверов.
Для проверки правильности настройки перейдите в раздел Система — Часы. В этом разделе можно установить часовой пояс, выбрав его из выпадающего списка, либо включив опцию Time Zone Autodetect, чтобы часовой пояс определялся автоматически.
Для определения интервала синхронизации с эталонными серверами можно посмотреть значение в поле Poll Interval в меню SNTP Client. Этот интервал позволяет определять частоту обновления времени на вашем устройстве.
Наконец, чтобы убедиться, что все работает правильно, можно проверить время последней синхронизации в поле Last Update в разделе SNTP Client. Если эта информация актуальна, значит ваше устройство получает время от выбранных серверов и корректно синхронизируется с ними.
Теперь вы знаете, как настроить NTP в распространенных операционных системах и на отдельных устройствах.
Как исправить ошибку аутентификации SSH
Проверка ключей и пароля — основополагающие элементы аутентификации с использованием SSH. Использование дополнительных проверок ключей доступа обеспечивает должный уровень безопасности, но иногда возникают неожиданные проблемы, например ошибка authentication failed. В данном материале рассмотрим способы устранения этой проблемы, проанализируем причины сбоев.
Ошибки: базовый случай
Если в терминале появилось сообщение «authentication failed», это означает, что процесс проверки подлинности пользователя не удался. Аутентификация — это процедура, которая требуется для подтверждения личности пользователя и предоставления доступа к системе. Например, для удаленного подключения к серверу по адресу может быть настроено SSH-соединение, которое требует прохождения аутентификации.
В файле конфигурации SSH определяется метод аутентификации. По умолчанию используется парольный метод, но можно также использовать аутентификацию с помощью ключевой пары SSH. В этом случае закрытая часть ключа хранится на компьютере пользователя, а открытая на сервере. Если при попытке установления соединения ключи совпадают, то доступ предоставляется. В противном случае появляется сообщение об ошибке, например, «authentication failed».
Однако причиной ошибки может быть не только несовпадение ключей, но и поврежденные файлы конфигурации или недостаточные права доступа.
Ошибки: использование пароля
«Authentication failed» сообщает о неудачной попытке проверки подлинности пользователя, необходимой для получения доступа к системе. Часто аутентификация требуется для удаленного подключения к серверу через SSH-соединение. Метод аутентификации, используемый по умолчанию, — парольный, но можно настроить аутентификацию с помощью ключевой пары SSH. При этом закрытая часть ключа хранится на компьютере пользователя, а открытая на сервере. Если ключи совпадают, то пользователь получает доступ, в противном случае появляется сообщение об ошибке, например, «authentication failed». Однако, несовпадение ключей не является единственной причиной ошибки — ее причинами также могут быть поврежденные файлы конфигурации или недостаточные права доступа.
Ошибки: ключи
При использовании SSH-подключений часто возникают проблемы, связанные с идентификационными ключами. Например, может возникнуть путаница при использовании нескольких ключей для подключения к разным хостам. Чтобы избежать таких проблем, следует использовать понятные имена файлов аутентификации.
Также возможна ошибка «Too many authentication failures for user», которая возникает, когда клиент SSH пытается подключиться к хосту со всеми доступными ключами, превышая максимальное количество разрешенных попыток. Чтобы исправить это, можно использовать опции IdentitiesOnly и IdentityFile.
Если при использовании ключей SSH возникает ошибка «Permission denied (publickey, password)», то это может быть связано с неправильно введенной парольной фразой. Если парольная фраза была потеряна, ее нельзя восстановить, и потребуется сгенерировать новую пару значений для Secure Shell.
Для более удобного использования опций IdentitiesOnly и IdentityFile можно установить их в конфигурационном файле SSH ~/.ssh/config. Это позволит SSH использовать только указанные идентификаторы при подключении к хостам.
Восстановление публичного ключа
Если вы потеряли открытую часть из пары ключей, не волнуйтесь, так как ее можно легко восстановить с помощью стандартных инструментов OpenSSH.
Для этого вы можете воспользоваться утилитой ssh-keygen. Просто откройте терминал и выполните следующую команду:
ssh-keygen -y -f ~/.ssh/id_rsa
В этой команде замените ~/.ssh/id_rsa на путь к файлу вашего закрытого ключа. В результате вы получите открытую часть вашего ключа, которую затем можно добавить на сервер.
Если вы используете среду Windows, вы можете достичь того же результата с помощью утилиты PuTTYgen, которая входит в пакет PuTTY. Просто загрузите свой закрытый ключ в утилиту с помощью кнопки Load, а затем скопируйте открытый ключ, отображаемый в поле Public key for… (Открытый ключ для…).
Важно отметить, что закрытый ключ не может быть восстановлен из открытого ключа. Это сделано специально для обеспечения безопасности системы.
Ошибки конфигурации клиента
Иногда, проблема кроется в неправильной подготовке к соединению. Возможно, вы просто некорректно настроили порты, протоколы и учетные данные на вход. Проверьте форматы ключей, сертификатов, валидность данных для входа и порты, которые вы указываете во время использования клиентов.
Конфликт конфигурационного файла
Убедитесь, что настройки в файле /etc/ssh/sshd_config не противоречат друг другу. Например, если аутентификация по паролю отключена или вход root запрещен, могут возникнуть конфликты.
Обычный пример конфликта — когда параметр PasswordAuthentication установлен в yes, а параметр PermitRootLogin установлен в no или without-password. Это может привести к тому, что сервер не сможет аутентифицировать пользователей, и установит запрет на доступ всем.
Права доступа
OpenSSH — это безопасный протокол для удаленного доступа к серверам, который применяет строгие правила владения и разрешения для файлов. Для обеспечения безопасного доступа важно проверить и установить соответствующие разрешения как на стороне сервера, так и на стороне клиента.
На стороне сервера должны быть установлены следующие разрешения:
Каталог ~/.ssh должен иметь разрешение 700.
Директория ~/.ssh должна принадлежать текущему пользователю.
Файл ~/.ssh/authorized_keys должен иметь разрешение 600.
Файл ~/.ssh/authorized_keys должен принадлежать текущему пользователю.
Аналогично, на стороне клиента необходимо проверить следующие разрешения:
Файл ~/.ssh/config должен иметь разрешение 600.
Файлы ~/.ssh/id_* должны иметь разрешение 600.
Право собственности на эти файлы очень важно, поскольку попытка подключения от другой учетной записи пользователя без разрешения на чтение содержимого защищенных каталогов может привести к отказу в доступе. Обеспечение правильного владения и разрешений позволяет аутентификации проходить гладко и безопасно.
Кроме того, OpenSSH больше не поддерживает использование старых типов ключей, основанных на алгоритме цифровой подписи (DSA), для безопасных серверных соединений. Ключи, использующие алгоритм ssh-dss, считаются слишком слабыми для обеспечения надежной защиты.
Для пользователей со старыми ключами оптимальным решением является генерация и добавление новых ключей на основе более безопасных алгоритмов. Однако в качестве альтернативы можно изменить файл /etc/ssh/sshd_config и установить параметр PubkeyAcceptedKeyTypes на «+ssh-dss», чтобы продолжать использовать ключи на основе DSA. Этот подход несет свои риски.
Дополнительные параметры могут потребоваться на SSH-клиенте при подключении к устаревшим серверам, которые давно не обновлялись. Например, для подключения к хостам CentOS 6, поддержка которых закончилась в конце 2020 года, пользователи должны добавить параметр «-oHostKeyAlgorithms=+ssh-dss», чтобы решить любые проблемы.
Сторонние сервисы
Проблемы аутентификации могут возникать и при использовании сторонних сервисов. Например, при подключении к API возникает сообщение user authorization failed invalid session. Устранение такого сбоя в частном порядке невозможно, стоит написать в техническую поддержку.
SMTP
SMTP, что расшифровывается как Simple Mail Transfer Protocol — протокол связи, используемым для передачи электронной почты (e-mail) через Интернет. Он включает в себя набор коммуникационных инструкций, которые позволяют программам отправлять сообщения электронной почты между пользователями на одном или разных компьютерах.
SMTP облегчает обмен сообщениями электронной почты, которые могут содержать текст, аудио, видео или графику. Основной задачей SMTP является установление правил связи между облачными серверами. Каждый сервер имеет возможность идентифицировать себя и объявить тип связи, которую он пытается установить. Они также имеют средства обработки ошибок, таких как неправильные адреса электронной почты. Если адрес электронной почты получателя недействителен, принимающий сервер ответит сообщением об ошибке.
В целом, SMTP играет важную роль в бесперебойном функционировании электронной почты, обеспечивая надежную передачу электронных сообщений между серверами и облегчая обработку ошибок.
Компоненты системы
SMTP (Simple Mail Transfer Protocol) можно разделить на два компонента: клиентский компонент и серверный компонент. Клиентский компонент отвечает за User Agent (UA), который подготавливает и создает сообщение, а затем помещает его в конверт. Серверный компонент отвечает за Mail Transfer Agent (MTA), который передает сообщение через Интернет.
Механизм работы
Отправка и получение электронной почты через протокол SMTP включает несколько этапов. На первом этапе пользователь создает сообщение электронной почты в программе для отправки и получения электронной почты (Mail User Agent, MUA). Сообщение состоит из заголовка и тела письма, где заголовок содержит информацию об адресах отправителя и получателя, а также тему сообщения, а тело — основной текст письма.
На следующем этапе подготовленное письмо отправляется по TCP-порту 25 на SMTP-сервер почтовым клиентом. Затем адрес электронной почты состоящий из имени получателя и имени домена отправляется на MTA (Mail Transfer Agent), который ищет целевой домен и пересылает письмо.
После получения входящего сообщения сервер Mail Exchange Server доставляет его на сервер входящей почты (Mail Delivery Agent), который сохраняет письмо до тех пор, пока пользователь не получит его. Чтобы получить доступ к сохраненной электронной почте, пользователь использует программу для отправки и получения электронной почты (MUA), для чего необходимо войти в MUA с помощью логина и пароля.
SMTP: основные команды
EHLO (formerly HELO) is used to establish a connection and is executed only if the client has specified their domain and email address.
MAIL is used to specify the sender’s address.
RCPT allows you to specify the recipient’s address. To send a message to multiple recipients, this command must be entered several times.
DATA notifies the receiving server that the envelope has ended, after which the actual message follows.
QUIT is used to disconnect from the server after the message has been received.
Сервер SMTP
Использование пользовательского SMTP-сервера необходимо при решении широкого круга задач, связанных с отправкой сообщений. Будь то транзакционные электронные письма или массовые рассылки, пользовательский SMTP-сервер может стать экономически эффективным решением с высокими показателями доставляемости. Кроме того, его легко интегрировать, и он пользуется обширной документацией, предоставляемой сообществом энтузиастов.
HTTP-запросы
HTTP, или Hypertext Transfer Protocol, — это коммуникационный протокол, специально разработанный для передачи данных и отображения веб-страниц в Интернете. Любое взаимодействие через HTTP напоминает разговор между пользователем и сервером. Пользователь инициирует запрос, известный как HTTP-запрос, к серверу с помощью клиента, а сервер отвечает, например, отображая веб-сайт в браузере.
HTTP-запросы – это, по сути, информационные сообщения, которые клиенты отправляют на сервер для выполнения определенного действия. Каждый HTTP-запрос должен содержать URL-адрес и метод, причем заголовок (HTTP-заголовок) является основой запроса.
HTTP-запросы могут иметь следующую структуру: GET https://www.example.com/ HTTP/1.1
В данном примере используется метод GET, запрос направлен на ресурс https://www.example.com, а используемая версия HTTP — HTTP/1.1.
Для большей наглядности рассмотрим структуру HTTP-запроса следующим образом:
Структура HTTP-запроса
Традиционно HTTP-запросы имеют следующую структуру:
Строка запроса: Необходима для описания запроса или статуса, включая версию протокола и другие детали. Это может быть запрашиваемый ресурс или код ответа (например, ошибка). Длина составляет ровно одну строку.
Заголовок HTTP: Появляется в виде нескольких строк текста, которые уточняют запрос или описывают содержимое тела сообщения.
Пустая строка: Необходима для индикации успешной передачи метаданных для конкретного запроса.
Тело запроса: Содержит информацию о запросе или документе, направляемом в ответ на запрос.
Пустая строка
На самом деле, эта строка не пустая, она содержит параметр CTRLF, который указывает на конец заголовка.
Тело запроса
Не для всех HTTP-запросов требуется тело запроса. Например, такие методы, как GET, HEAD, DELETE и OPTIONS, обычно не требуют тела запроса. Однако для таких методов, как POST, тело запроса необходимо для отправки информации на сервер для обновления.
Тела запросов можно разделить на два типа: с одним ресурсом и с несколькими ресурсами. Тела запросов с одним ресурсом состоят из одного изолированного файла с двумя заголовками: Content-Type и Content-Length.
Тела запросов с несколькими ресурсами, с другой стороны, состоят из нескольких частей, каждая из которых содержит свой бит информации. Эти части связаны с HTML-формами.
Помимо HTTP-запросов, существуют также ответы, но это уже совсем другая история.
PaaS
PaaS, или платформа как услуга, — это облачный сервис, который позволяет разработчикам получать доступ к инфраструктуре, инструментам и промежуточному программному обеспечению через Интернет. Услуга также может быть развернута локально или гибридным образом.
Поставщик облачных услуг управляет инфраструктурой для запуска приложений, но клиент может выбирать место размещения приложения, уровень его производительности и безопасности.
PaaS обычно состоит из следующих стандартных компонентов:
Инфраструктура: Облачные провайдеры предоставляют и управляют серверами, системами хранения данных, центрами обработки данных и сетевыми ресурсами, необходимыми для работы приложений.
Инструменты проектирования, тестирования и разработки: Интегрированные среды разработки (IDE), включающие редакторы кода, компиляторы и отладчики, а также в некоторых случаях инструменты для совместной работы.
Среднее программное обеспечение: Решения PaaS часто включают инструменты промежуточного ПО, необходимые для интеграции различных операционных систем и пользовательских приложений.
Операционные системы и базы данных: PaaS предоставляет операционные системы для запуска приложений, а также различные типы управляемых баз данных.
PaaS/IaaS
Когда речь заходит о выборе между PaaS и IaaS, многие разработчики склоняются к возможностям IaaS для создания индивидуальной виртуальной среды. Однако для тех, кто ищет быстрый и легкий старт, решения PaaS — это то, что нужно.
Одним из основных преимуществ PaaS является возможность быстрой разработки и развертывания приложений без необходимости настройки и обслуживания инфраструктуры. Это позволяет разработчикам сосредоточиться на бизнес-логике и развертывать приложения быстрее и чаще. Кроме того, решения PaaS предоставляют высокие гарантии доступности услуг и техническую поддержку, поэтому ИТ-командам не нужно беспокоиться об обновлениях и проблемах конфигурации, поскольку об этом позаботится поставщик услуг.
Кроме того, PaaS является отличной платформой для изучения новых методов разработки облачных решений и языков программирования без необходимости вкладывать средства в создание новых виртуальных сред. Однако передача данных приложения стороннему поставщику платформы сопряжена с определенными рисками, включая проблемы конфиденциальности и безопасности данных, увеличение затрат на аппаратные ресурсы и непредвиденные обстоятельства. Однако с надежным поставщиком такие риски можно свести к минимуму.
Компания Obit предлагает своим клиентам несколько решений PaaS. Решение Kubernetes in the Cloud предлагает управляемую кластерную инфраструктуру, масштабируемую и совместимую с Kubernetes, а Container Service Extension (CSE) позволяет клиентам быстро развертывать, управлять и настраивать облачные базы данных. Кроме того, решение Obit Cloud-native Apache Hadoop обеспечивает быстрый и удобный способ запуска кластеров Hadoop и обработки массивов данных из различных источников. С Obit клиенты могут выбрать решение, соответствующее их потребностям, а Obit берет на себя все заботы по настройке и обслуживанию.
Объектное хранилище S3
Файловая система
Файловая система — это форма организации и хранения данных, которая имеет схожие черты с организацией физического докуметооборота. В этой системе каждая единица информации хранится в электронной папке. Чтобы получить доступ к этой информации, компьютер должен знать путь к файлу. Файлы организуются и извлекаются с помощью метаданных, которые сообщают компьютеру, где файл находится.
Файловая система —- это самый старый и распространенный метод хранения данных в прямых и сетевых системах хранения. Вы, скорее всего, используете файловую систему, когда работаете с файлами на своем компьютере. Эта система позволяет хранить любые данные и удобна для хранения сложных файлов, так как обеспечивает быстрый доступ к ним.
Однако файловая система не лишена недостатков. Количество хранимых данных растет в геометрической прогрессии, поэтому нужно постоянно искать способы масштабирования.
Блочное хранилище
Блочное хранение данных предполагает разбиение информации на отдельные блоки и их хранение в различных местах. Каждый блок получает уникальный идентификатор, что позволяет системе хранения оптимизировать распределение данных по различным средам и использовать наилучшие для этого места. Например, данные могут храниться на разных операционных системах.
Блочное хранение данных обеспечивает возможность выделения информации от пользовательской среды и ее распределение по нескольким средам, что обеспечивает более эффективную работу. При запросе информации, базовое программное обеспечение собирает необходимые блоки из разных сред и предоставляет их пользователю.
Так как блочное хранение не зависит от единственного пути к данным, как в случае файлового хранения, информация может быть получена быстрее. Каждый блок существует независимо и может быть использован в другой операционной системе, что дает пользователям полную гибкость в настройке системы. Этот метод является надежным и простым в использовании и управлении, что делает его идеальным для крупных предприятий, занимающихся крупными транзакциями или обслуживающих массивные базы данных.
Недостатками блочного хранения являются высокая стоимость и ограниченные возможности для обработки метаданных. Разработчики и системные администраторы должны работать с метаданными на уровне приложения или базы данных.
Блочное хранение данных — мощный инструмент для хранения и управления информацией, обеспечивающий быстрый и гибкий доступ к данным в различных средах.
Объектное хранилище
Объектное хранилище данных – это структура, в которой файлы разбиваются на объекты и хранятся в едином хранилище, а не в файловой системе. Эти объекты содержат метаданные, такие как дата создания, конфиденциальность и другие свойства, которые облегчают поиск и извлечение данных.
Хранение объектов осуществляется на основе томов, которые представляют собой автономные хранилища, содержащие уникальные идентификаторы для поиска объектов в распределенной системе. Объектное хранилище имеет простой интерфейс HTTP API, который обеспечивает лучшую балансировку нагрузки и легкое применение политик для надежного поиска.
Одним из главных преимуществ объектного хранения — его масштабируемость, к тому же объектные хранилища являются экономически выгодным решением. Вы платите только за использованный объем, и система легко масштабируема. Объекты также содержат достаточно информации для быстрого нахождения данных, и могут эффективно сохранять неструктурированные данные.
Однако есть и недостатки. Объекты нельзя модифицировать, они должны быть полностью записаны за один раз. Также объектное хранение плохо сочетается с традиционными базами данных, и создание приложения, использующего API объектного хранения, может быть сложнее, чем создание приложения, использующего файловый подход.
Преимущества
S3-объектное хранилище считается оптимальным выбором для корпоративных нужд по нескольким причинам:
Экономическая выгода: Клиенты платят только за фактически использованный объем хранилища и время, что делает S3 экономически эффективным решением.
Высокая масштабируемость: Хранилище S3 легко масштабируется в зависимости от изменяющихся потребностей, также возможно автоматическое масштабирование. Надежность: Риск потери данных минимален, обеспечивая сохранность данных и постоянный доступ к ним. Высокая доступность: Доступ к данным возможен 24 часа в сутки 7 дней в неделю из любой точки мира, с любого устройства. Безопасность: Данные шифруются и доступны только уполномоченным лицам или группам.
Простота управления: Интуитивно понятный интерфейс упрощает управление информацией в S3, делая его удобным для пользователя.
Объектное хранилище предлагает комплексное решение для хранения резервных копий, документов, архивов и распространения контента с минимальной нагрузкой на основные ресурсы. Наше решение для объектного хранения данных гарантирует беспрецедентный уровень надежности и доступности данных, а время безотказной работы составляет 99,999999999%.
Домен (доменное имя)
В этом материале мы повествуем о доменных именах и их важности в информационных технологиях и в Интернете.
Доменное имя — это уникальное имя, которое соотносится с определенным сайтом в Интернете. Например, введя «google.com» в адресную строку браузера, мы попадаем на сайт Google. Часто путают понятия «домен» и «сайт», это два разных термина. Сайт — это совокупность веб-страниц с определенным контентом, которые отображаются в Интернете, а домен — это уникальное имя, которое идентифицирует сайт и позволяет пользователям легко найти его в Интернете.
Без доменного имени сайт не сможет быть найден в Интернете, так как пользователи не смогут ввести его название в адресную строку браузера. Доменное имя также может помочь установить уникальный имидж для сайта, сделав его более узнаваемым и легко запоминаемым. В целом, доменное имя является неотъемлемой частью веб-адреса сайта и играет достаточно важную роль, начиная от продвижения, заканчивая банальным поиском.
Структура доменного имени
Форма организации доменов — иерархическая структура, состоящая из нескольких уровней. Домены второго, третьего, четвертого уровней называются поддоменами и создаются на основе доменов вышестоящего уровня. Поддомены могут содержать любую комбинацию символов, которые мы выбираем для имени нашего сайта.
Домены первого уровня, также известные как доменные зоны, находятся справа от точки в доменном имени. Такие домены зона могут быть выбраны только ICANN и могут быть географическими или тематическими. Например, .RU указывает на Россию, .EU на страны Европейского союза, а .COM используется для коммерческих сайтов.
Домен нулевого уровня — это точка, которая следует за доменной зоной, но по умолчанию не отображается в адресной строке браузера.
DNS-домены
Иерархия доменов напоминает русскую матрешку, состоящую из вложенных друг в друга частей. Каждый уровень, начиная от домена третьего уровня (например, music.youtube.com) до доменов второго уровня (youtube.com) и доменной зоны (.com), вкладывается в более высокий уровень, пока не достигнет домена нулевого уровня (точки).
Эта структура дает возможность функционирования системы доменных имен (DNS). DNS переводит удобочитаемые доменные имена в IP-адреса, которые используются компьютерами для поиска ресурсов в Интернете. Благодаря системе доменных имен, мы можем легко найти веб-сайты, используя их доменные имена, а не запоминать длинные числовые IP-адреса.
Если вы хотите узнать больше о том, как работает система доменных имен и как она влияет на нашу жизнь в Интернете, мы предлагаем вам ознакомиться со статьей на эту тему.
Домены на практике
В процессе выбора доменного имени, веб-мастер обычно акцентирует внимание на лаконичность и простоту названия. Для DNS не важен внешний вид выбранного доменного имени. Но при этом не стоит забывать, хорошее название позволит вам пройти процесс индексации правильно, повысив шансы на целевую выдачу. Эти факторы напрямую влияют на SEO, что отражается на бизнесе. При выборе имен, вы можете обратиться к существующим сервисами и инструментам, чтобы точно понять, в каком домене вы нуждаетесь.
Однако не все домены равнозначны. Существуют премиум-домены, которые имеют более высокую цену из-за их престижности и редкости, а также кириллические домены, которые для использования в DNS могут быть закодированы в Punycode. После выбора имени необходимо зарегистрировать домен, но важно помнить, что регистрация означает аренду домена на определенный период времени у регистратора. Например, домены зоны .RU могут быть зарегистрированы на срок до одного года с возможностью продления регистрации.
Настройка SSL для почты
Для почтового сервера сертификат будет самоподписанным.
ISPmanager 6
В подменю выберите пункт «Почта», после «Почтовые домены». Найдите SSL-сертификаты.
В новом окне измените приватный ключ, сертификат на ваши, после пропишите цепочку.
CentOS
Подготовка файла конфигурации:
vi /etc/exim/exim.conf
# TLS/SSL
tls_advertise_hosts = *
tls_certificate = /etc/exim/ssl/domain.ru.crt
tls_privatekey = /etc/exim/ssl/domain.ru.key
daemon_smtp_ports = 25 : 465 : 587
tls_on_connect_ports = 465
Поместите сертификат с цепочкой в /etc/exim/ssl/domain.ru.crt. Ключи разместите по следующему пути: /etc/exim/ssl/domain.ru.key.
Установка SSL от Let’s Encrypt на сервер (без панели)
Сертификаты — важный инструмент безопасности. Сертификат обеспечивает шифрование конфиденциальных данных пользователей (например пароли, банковские данные). Проекты, которые только набирают обороты, тоже нуждаются в защите, но для создателя в таком случае нецелесообразно сразу приобретать лучшую криптографическую защиту. Let’s Encrypt — решение, подходящее на старте.
Let’s Encrypt — это центр сертификации, который предоставляет бесплатные криптографические сертификаты X.509.
Certbot
Подключитесь к серверу через SSH. Установите certbot.
Вместо значений с * необходимо поставить свои (доменные имена).
После запуска, появится сообщение:
Please deploy a DNS TXT record under the name _acme-challenge.lamp.fvds.ru with the following value:
RYHdWpSmMuVjdJFZT9JGBs7zuQOFgN78f1Azt1fwNcc Before continuing, verify the record is deployed.
Необходимо создать новую запись TXT для имени домена в DNS-реестре.
После того, как вы создали запись, возвращайтесь в терминал и нажмите «Enter» для того, чтобы продолжить инициализацию. Certbot запросит создание второй TXT записи. Чтобы её создать, повторите действия, приведенные ранее.
Установка SSL-сертификата на домен
После получения необходимых файлов и сертификата, необходимо встроить этот сертификат на сервер, чтобы потом им подписать ваше доменное имя. Данный материал описывает установку сертификата с помощью менеджера ISPmanager, а также установку напрямую, не используя утилиты.
Использование ISPmanager 6
Авторизируйтесь в качестве пользователя, который владеет необходимым доменом. Чтобы это сделать, войдите в систему с правами суперпользователя (root), после найдите в меню пункт «Пользователи«, выберите «Войти под пользователем».
Важно: вам необходимо подключить возможность использования SSL. В пункте «Пользователи», в настройках определенного пользователя найдите «Может использовать SSL», отметьте этот пункт.
В подменю «SSL-сертификаты« — «Добавить сертификат».
Тип сертификата — существующий.
Параметры:
Имя сертификата — имя формируется в зависимости от информации, которая содержится в сертификате + «_customX» Если у ваша версия панели < 6.19, то вам необходимо вручную установить имя сертификата. SSL-Сертификат — поле, для загрузки файла .crt. Ключ сертификата — содержимое приватного ключа (файл .key). Также вам необходимо представить в панель файл (.ca/.ctrca). Это цепочка сертификатов (сертификат, которым подписан ваш исходный). Содержимое сертификатов просто скопируйте из файлов и вставьте в подходящие поля.
Например: цепочка сертификатов от GlobalSign
Вы получаете архив с файлами (файл .p7b сертификат и цепочка сертификата, файл с именем домена + открытый ключ + сертификат, корневой ключ цепочки сертификата, промежуточный ключ .crt).
Чтобы создать цепочки сертификата поместите в один файл .txt корневой ключ сертификата, после за ним, начиная с новой строки, промежуточный ключ и установите для него название GlobalSign.ca. Откройте файлы с ключами цепочки через любой текстовый редактор. Скопируйте содержимое, обязательно проверьте целостность скопированного кода.
Когда вы добавили сертификат, переходите на страницу «Сайты», запустите сервер. Вы увидите установленный сертификат. Но если настройки сайта будут меняться, то файлы конфигурации будут перезаписаны автоматически.
Изменения в файлах, которые вы вносили руками, могут не сохраниться. В случае возникновения подобной ситуации вам нужно перейти в /var/www/httpd-cert/ИМЯ_ПОЛЬЗОВАТЕЛЯ/ИМЯ_СЕРТИФИКАТА и повторно внести нужные изменения.
domain.com — доменное имя 10.0.0.1 — IP, который принадлежит домену путь — /path/to/domain.crt (сертификат) /path/to/domain.key — ключ сервера (путь)
Цепочка сертификата добавляется в файл с самим сертификатом.
После того, как вы изменили файл конфигурации, проверьте наличие ошибок в синтаксисе, а также ваши вставленные данные.
nginx -t — проверка конфигурации
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
Если вы увидели подобный вывод, то SSL настроен корректно
systemctl restart nginx — перезапуск сервера
SSL-сертификаты (несколько) на едином IP
Браузер получит сертификат сервера, выставленный по умолчанию. Это не зависит от недостаточной настройки, так работает SSL. Чтобы разрешить работы нескольких сертификатов на одном IP, необходимо воспользоваться расширением SNI протокола TLS. Ссылка на документацию (https://tools.ietf.org/html/rfc6066). Данный модуль позволит установить SSL-handshake, во время которого сервер определит необходимый сертификат для использования. Большинство современных браузеров поддерживает это решение, но стоит обратить внимание также на версию библиотеки OpenSSL, она должна быть > 0.9.8f.
Процесс разделен на этапы, чтобы разобрать каждый этап отдельно.
Добавление сертификата на сервер
Чтобы вы смогли произвести установку сертификата на ваш сервер, перейдите в «Диспетчер серверов». Цепочка кнопок: Пуск — Администрирование — Диспетчер Серверов.
После как вы перешли в данное меню, найдите «Диспетчер служб IIS». В подменю выберите «Сертификаты сервера».
Ваши дальнейшие действия зависят от места, где был сгенерирован CSR.
Способ генерации CSR: самостоятельно с помощью личного кабинета
Если у вас уже есть ключ в вашем личном кабинете, то совершите экспорт этого ключа в формате .pfx файла. Для импорта ключа на сервер, найдите пункт «Действия» в меню, после выберите «Импортировать».
По прохождению данного этапа система оповестит вас о том, что сертификат стал доступным. Посмотреть подробную информацию можно в меню «Сертификаты сервера».
Подключение SSL-сертификата на домен
Перейдите в меню настройки конфигурации сайта. Найдите пункт «Подключения», выберите нужный сайт и нажмите на кнопку «Привязки».
В новом окне введите данные (кнопка «Добавить»). Образец следующий:
ТИП — https
ПОРТ — 443
Имя узла — имя домена
IP — IP сайта
После заполнения всех полей, нажмите «ОК». Перезагрузите сервер. Чтобы проверить успешность установки сертификата на веб-ресурс, достаточно взглянуть на URL. Если сайт стал доступен по https — установка прошла успешно.
Как пользоваться SSH
Допустим, вы арендовали облачный сервер, чтобы разместить на нем свой сайт. После покупки вам предоставляется чистая система, которую необходимо настроить: установить веб-сервер, загрузить файлы и т.д. Для этого можно воспользоваться протоколом SSH.
SSH (Secure Shell) — это протокол, позволяющий осуществлять удаленный доступ к устройствам с операционной системой Linux, таким как компьютеры, серверы, телефоны и др. Это набор правил, который позволяет установить безопасное соединение с устройством, расположенным в любой точке мира.
Название протокола содержит слово «secure», что означает, что обмен данными между устройствами происходит в зашифрованном виде. Это позволяет работать с чувствительной информацией, такой как пароли, коды доступа и другие конфиденциальные данные.
Для обеспечения безопасности обмена данными используется шифрование информации. Для этого при соединении между клиентом и сервером используется один из двух способов аутентификации:
Вход по паролю. При этом между клиентом и сервером создается общий секретный ключ, который используется для шифрования трафика.
Вход с помощью пары ключей. Пользователь генерирует два ключа — открытый и закрытый, которые хранятся на удаленном и локальном устройствах соответственно. Эти ключи используются для аутентификации при соединении.
Вход в систему с помощью ключей
Использование пароля для входа на сервер через SSH небезопасно и неудобно. Во-первых, пароль можно взломать методом грубой силы. Во-вторых, есть риск случайной утечки, так как может быть несколько устройств с разными паролями, которые сложно запомнить. И в-третьих, утомительно вводить пароль каждый раз перед началом сеанса.
Самый безопасный способ входа в систему — использование пары ключей RSA.
Сначала ключи необходимо создать на локальном компьютере с помощью команды:
ssh-keygen -t rsa
В процессе создания вам нужно будет выбрать расположение файлов ключей и ввести парольную фразу. Если вы хотите войти без пароля, оставьте поле парольной фразы пустым. Парольная фраза — это дополнительный пароль, который защищает ключ. Если ваш закрытый ключ будет скомпрометирован, хакеры не смогут использовать его без кодовой фразы.
Далее открытый ключ необходимо отправить на сервер. Открытый ключ обозначается суффиксом .pub и должен иметь права на чтение для всех пользователей:
Эта команда создаст сеанс SSH. После ввода пароля открытый ключ будет скопирован в файл авторизованных ключей, и повторно вводить пароль не потребуется.
Вы можете еще больше повысить безопасность, полностью отключив парольный доступ. Для этого отредактируйте файл /etc/ssh/sshd_config и установите следующие директивы:
PasswordAuthentication no — отключает вход по паролю.
PubkeyAuthentication yes — разрешает аутентификацию по ключу SSH.
ChallengeResponseAuthentication no — отключает аутентификацию PAM.
После обновления файла перезагрузите демон SSH:
sudo systemctl перезагрузить ssh
Настройка SSH
Для установления соединения на удаленном устройстве должен быть запущен сервер sshd, который запускается в Ubuntu с помощью диспетчера systemd:
sudo systemctl запустить ssh
Конфигурацию сервера sshd можно найти в файле /etc/ssh/sshd_config.
Порт. По умолчанию sshd прослушивает изменения на порту 22. Хакеры часто пытаются получить доступ к вашему устройству путем подбора паролей суперпользователя, таких как root, admin и т. д. Вы можете сделать это более сложным, изменив порт по умолчанию на любой другой с помощью директивы Port. Однако это не гарантирует полной безопасности, так как существуют скрипты, сканирующие порты устройства. Они обнаружат порт, который прослушивает демон sshd, и попытаются получить доступ. Для большей безопасности рекомендуется закрыть доступ по SSH для пользователя root.
Доступ суперпользователя. Поскольку SSH в основном используется для администрирования удаленных серверов Linux, удаленный доступ для суперпользователя root разрешен по умолчанию во всех современных системах. Однако это очень небезопасно, так как хакеры могут попытаться подобрать пароль и, если им удастся проникнуть в систему, получить полный контроль над устройством. Чтобы избежать таких сценариев, используйте директиву PermitRootLogin со значением «нет».
Протокол. SSH может работать с использованием двух версий протокола — 1 и 2. Вторая поддерживает больше методов шифрования и методов аутентификации. Если вы хотите использовать только одну из версий, используйте директиву Protocol: Protocol 2.
Доступ для конкретных пользователей. Для дальнейшего повышения безопасности вы можете разрешить удаленный доступ только для определенных пользователей и групп, используя директивы AllowUsers и AllowGroups соответственно. Например, вы можете запретить доступ к серверу всем, кроме администраторов:
Вы также можете запретить доступ определенным пользователям, используя DenyUsers и DenyGroups.
Протоколирование ошибок. Вы можете установить уровень ведения журнала с помощью директивы LogLevel, которая отвечает за уровень содержимого в системном журнале, т. е. насколько подробно sshd будет сохранять сообщения, которые он регистрирует. По умолчанию используется INFO, но в целях отладки вы можете установить для него значение VERBOSE или полностью отключить ведение журнала с помощью QUIET.
Доступ по паролю. Директива PasswordAuthentication отвечает за возможность доступа к удаленному устройству с помощью пароля со значением по умолчанию «да».
После внесения изменений и сохранения файла необходимо перезапустить сервер sshd, чтобы новая конфигурация вступила в силу. Перед этим убедитесь, что вы сохранили файл ключа на сервере или оставили доступ по паролю, иначе есть риск быть заблокированным на сервере.
sudo systemctl перезагрузить ssh
SSH клиенты
Удобно использовать клиенты-приложения, потому что есть возможность более гибким образом администрировать SSH-подключения. Популярные вариации:
PuTTY
WinSCP
Termius
FileZilla — для передачи данных по SFTP
MobaXterm
Синтаксис
Для удаленного подключения к серверу необходимо использовать команду SSH, указав IP-адрес или доменное имя сервера:
ssh example.com
Однако, если имена пользователей на локальной и удаленной системах отличаются, нужно явно указать имя пользователя при подключении:
ssh remote@example.com
Сеанс можно завершить с помощью команды exit.
Если во время настройки удаленного сервера был задан порт, отличный от 22, то для подключения к серверу с локального устройства необходимо указать этот порт с помощью флага -p:
Если на удаленном сервере настроен демон sshd, то можно использовать другие утилиты, работающие на основе протокола SSH. Одна из таких утилит — scp, которая использует протокол RCP для передачи файлов.
Для передачи файла filename.txt на удаленное устройство с адресом example.com и размещения его в каталоге ~/trash/txt, нужно использовать следующую команду:
scp filename.txt remote@example.com:~/trash/txt
Если поменять местами локальный путь и сервер, то можно скачать файлы с удаленного сервера на локальное устройство.
Для передачи всего каталога следует добавить флаг -r. При указании пути к каталогу, в который нужно скопировать данные, он должен заканчиваться косой чертой.
Допустим, нужно скопировать каталог images с сервера на локальный компьютер в папку documents:
scp -r remote@example.com:~/images ~/documents/
Также можно передавать файлы между двумя удаленными машинами, указав путь подключения к серверу вместо локальных файлов.
SSH-туннелирование
SSH туннели позволяют установить безопасный удалённый доступ и передачу файлов по защищенной сети. Они обычно применяются в случаях, когда необходимо получить доступ к приватной сети или создать зашифрованный канал.
Для установки порт-туннеля через удаленный сервер используйте флаг -L. Рассмотрим пример использования, когда необходимо получить доступ к удаленной базе данных MySQL, которая доступна только на локальном порту 3306.
Для создания туннеля выполните следующую команду:
ssh -N -L 53306:127.0.0.1:3306 remote@example.com
В данной команде флаг -N указывает, что на удаленном сервере не нужно выполнять команды. 53306 — это локальный порт, который вы выбираете, и который будет использоваться для доступа к удаленному порту 3306. Адрес 127.0.0.1:3306 указывает на то, что MySQL работает на удаленном сервере на локальном адресе 127.0.0.1 (localhost) и на порту 3306.
Теперь, когда туннель установлен, можно установить безопасное соединение с базой данных MySQL на удаленном сервере, используя локальный порт 53306.
SFTP
SFTP (Secure File Transfer Protocol) — это протокол передачи файлов, который работает по защищенному каналу и является частью OpenSSH, поэтому, если ваш демон SSH работает правильно, вы можете использовать SFTP без какой-либо дополнительной настройки. Основное различие между SFTP и стандартным FTP заключается в том, что SFTP шифрует всю информацию.
Для создания сеанса SFTP используйте те же учетные данные — логин и пароль или ключ — что и для SSH. Кроме того, вы можете указать порт, если вы изменили его с 22 по умолчанию на какой-либо другой порт. Для этого используйте следующую команду:
sftp -oPort=222 remote@example.com
После успешной аутентификации вы окажетесь на удаленном сервере и сможете работать с файлами.
Удаление образов, контейнеров, томов и сети Docker
Docker — инструмент для создания приложений с использованием контейнеров. При инициализации Docker появляются расходные файлы и объекты, которые необходимо очищать.
Вы можете удалять появившиеся структуры руками, но лучше оптимизировать эту задачу через командную строку.
Удаление контейнеров
Перейдите во вкладку «Containers/Apps» (веб Docker Desktop). Укажите, что нужно сделать с элементами и примените:
Также, способ, использую консоль. Команда для удаления — docker container rm. Синтаксис:
Параметры — (—force/-f — удаление контейнера в принудительном порядке), (—link/-l — удалить связь между элементами), (—volume/-v — удалить неопределенные тома, которые связаны с контейнером). ID получите с помощью команды — docker ps.
Параметры:
—-all или -a: выводим все работающие контейнеры
—filter или -f: фильтрация флагов
—format: формат вывода
—last или -n: вывод информации о последних n контейнерах
—latest или -l: вывод информации о последнем контейнере
—no-trunc: полный вывод
—quiet или -q: отдельный вывод идентификационного номера
—size или -s: вывод размера
С этими параметрами можно гибко взаимодействовать с группой контейнеров или отдельными единицами. Например, чтобы создать списки контейнеров на удаление — docker ps -a -f status=created -f status=exited, чтобы удалить — docker container rm $(docker ps -a -f status=created -f status=exited -q). Перед удалением лучше остановить предполагаемые контейнеры. Чтобы удалить все контейнеры:
docker stop $(docker ps -a -q)
docker container rm $(docker ps -a -q)
Удаление образов
Перейдите во вкладку «Images».
Чтобы удалить, найдите «Clean up…», выберите образы для удаления. Если образ в работе, просто удалить его не получится.
—force или -f: удалить образ в принудительном порядке
—no-prune: не удалять непомеченные
Узнать ID образа:
docker images [параметры] [REPOSITORY:[TAG]]
Параметры:
—all или -a: выводим все образы. По умолчанию промежуточные будут скрыты;
—digests: выводим дайджесты;
—filter или -f: фильтр по флагам;
—format: формат вывода;
—no-trunc: не обрезать вывод;
—quiet или -q: выводим только идентификаторы;
Запросите нужный список образов и используйте его как параметр для команды docker rmi. В качестве примера избавимся от образов, не привязанных к контейнерам. Для этого воспользуемся флагом dangling=true — docker images –filter dangling=true. Чтобы удалить список — docker rmi $(docker images –filter dangling=true -q). Чтобы удалить неработающие образы — команда docker image prune.
Удаление томов
Том — это файловая система, которая находится вне контейнеров, размещенная на хост-машине. Если вы хотите освободить пространство на диске от них, перейдите в раздел «Volumes», в правом верхнем углу выберите:
Чтобы удалить тома: docker volume rm [параметры] [имена томов]
Параметров у этой команды довольно мало, возможно принудительное удаление тома. Удалить можно только те тома, что не связаны с работающими контейнерами.
docker volume ls [параметры] — команда для определения имени тома. Параметры:
—filter или -f: фильтр по флагам
—format: формат вывода
—quiet или -q: выводим только имена
Чтобы стереть тома, несвязанные с контейнерами — docker volume ls -f dangling=true. Команда для запуска удаления — docker volume rm $(docker volume ls -f dangling=true -q). Но можно обойтись и другой командой для удаления таких томов: docker volume prune.
Удалить сети
Чтобы удалить сети в Docker, используйте команду «docker network rm» со следующим синтаксисом:
docker network rm [Сетевые имена/идентификаторы]
Эта команда не имеет параметров. Вы можете передавать как имена, так и идентификаторы. Чтобы узнать имена и идентификаторы сетей, используйте «docker network ls»:
docker network ls [параметры]
Есть 4 параметра:
—filter или -f: фильтровать по флагам
—format: выходной формат
—no-trunc: не обрезать вывод
—quiet или -q: показать только идентификаторы
Перед удалением сети необходимо удалить объекты, которые ее используют. Чтобы узнать, какие контейнеры используют конкретную сеть, используйте следующую команду:
docker ps -f network=[ID сети]
После этого можно приступать к удалению сети. Например, чтобы удалить сети со значением driver=bridge:
docker network ls -f driver=bridge
docker network rm $(docker network ls -f driver=bridge -q)
Очистка Docker от всех объектов
Сначала остановить и удалить все контейнеры:
docker stop $(docker ps -a -q)
docker rm $(docker ps -a -q)
Удалить все образы:
docker rmi $(docker images -a -q)
Удалить все тома:
docker volume rm $(docker volume ls -a -q)
Удалить все сети:
docker network rm $(docker network ls -a -q)
Как установить Docker на Ubuntu 22.04
Docker — программное обеспечение с открытым исходным кодом. Docker используют для создания контейнеров (виртуализация). Контейнеры меньше расходуют вычислительные ресурсы, в отличии виртуальных машин.
Системные требования
Docker может быть запущен совместно с большим количеством системных архитектур. Требования к аппаратной оболочке зависят от задач, которые будут выполнятся. Поэтому, настоятельно рекомендуем перед использованием Docker провести анализ, чтобы выявить необходимость развертки контейнеров.
Установка Docker на Ubuntu 22.04
Обновите пакеты
sudo apt update
Установите специальные пакеты
curl
software-properties-common
ca-certificates
apt-transport-https
Команда для установки — sudo apt install curl software-properties-common ca-certificates apt-transport-https -y
Команда автоматически примет все необходимые соглашения
Проконтролируйте, установка зависимостей должна происходить в подготовленной среде (репозитории).
Установите Docker
sudo apt install docker-ce -y
Проверьте успешность установки:
sudo systemctl status docker
Если успешно — статус Active(Running)
Docker Compose — Ubuntu 22.04
Docker Compose — инструмент Docker. С помощью него возможно управлять множеством контейнеров. Оркестрация позволяет образовать большое количество контейнеров в единую инфраструктуру. Диспетчеризация (управление) производится через YAML-файл, содержащий параметры для контейнеров и программных оболочек.
Установка через Git
sudo apt-get install git
Узнать версию Git
git —version
Чтобы перенести репозиторий, перейдите на веб-страницу Docker Compose на GitHub и скопируйте выделенную на картинке ссылку:
Как только файлы загрузятся, установите права на использование:
sudo chmod +x /usr/local/bin/docker-compose
Apt-get установка
Используя встроенный пакетный менеджер, установить Docker Compose можете через команду:
sudo apt-get install docker-compose
Установка Terraform: пошаговая инструкция
Terraform — программное обеспечение, предназначенное для гибкого управления системами Hashicorp. Является системой управления для облачных решений. Главные плюсы использования — наличие автоматизации.
Принципы работы
Инструмент использует файлы конфигураций HCL, чтобы предоставить вам конструктор будущей инфраструктуры. Использовать можно по-разному, например, для того, что инициализировать новые связи между компонентами. Помимо общей структуры, пользователь также может задать параметры для ресурсов. Terraform учитывает зависимости между компонентами, поэтому запуск осуществляется после полной проверки и изучения темплейтов. При редактировании конфигурации, изменения вносятся автоматически.
Terraform и Windows
Два способа:
менеджер пакетов
установка вручную
Chocolatey
Пакетный менеджер Windows.
choco install <package_name>
Имя пакета —- <package_name>
Запустите командную строку с правами администратора, установите terraform:
choco install terraform
Чтобы удостовериться в установке, введите команду:
переместите файл в /usr/local/bin — sudo mv terraform /usr/local/bin/
проверка версии —- terraform -v
Terraform: мощный инструмент для администрирования
Программное обеспечение позволяет значительно упростить процесс администрирования комплексных систем. Оптимизация и автоматизация — главные плюсы.
SSH-туннели: примеры и функции
SSH-туннелирование необходимо для обеспечения безопасности канала передачи данных посредством шифрования. Обычно, каналы устанавливаются между локальным хостом и удаленным сервером.
Структура туннелей
SSH — (secure shell) протокол, предназначенный для обеспечение удаленного управления системами. Главная особенность — наличие шифрования. Туннелирование Secure Shell (SSH) — это метод, используемый для установления безопасного соединения с удаленным компьютером. Он включает переадресацию портов SSH для передачи TCP-пакетов и преобразование заголовков IP для безопасной связи. В отличие от VPN, который позволяет передавать информацию в любом направлении, туннелирование SSH имеет определенную точку входа и выхода для связи. Поэтому важно понимать разницу между SSH и VPN при сравнении двух технологий.
Создание туннеля
Используются два ключа (приватный и открытый). На сервере хранится публичный ключ, на локальном хосте — приватный.
Ubuntu и другие дистрибутивы Linux/macOS
Терминал:
ssh-keygen -t rsa
Вывод:
Enter file in which to save the key (/home/user/.ssh/id_rsa):
По умолчанию закрытый ключ истории хранится в папке .ssh в файле id_rsa. Однако у вас есть возможность указать другое местоположение и имя файла.
Затем система предложит вам установить пароль для дополнительной защиты ключа. Это важно для предотвращения несанкционированного доступа лиц, имеющих доступ к машине. Это особенно полезно, когда несколько человек используют один и тот же компьютер. Если вам не требуется пароль, просто оставьте поле пустым и нажмите Enter.
Enter passphrase (empty for no passphrase):
После успешного создания пары ключей в терминале появится такая запись:
Your identification has been saved in /home/user/.ssh/id_rsa.
Your public key has been saved in /home/user/.ssh/id_rsa.pub.
Теперь нужно скопировать публичный ключ и добавить его на удалённую машину. Можно открыть файл /home/user/.ssh/id_rsa.pub через любой текстовый редактор или вывести его содержимое в терминале:
cat ~/.ssh/id_rsa.pub
Скопируйте ключ и добавьте его на сервер. Убедитесь, что в нём нет пробелов и переносов.
Можно скопировать открытый ключ автоматически, используя команду:
ssh-copy-id user@remoteserver
Вместо использования параметра HOST соединение с сервером будет установлено с использованием его общедоступного IP-адреса. Если вы не установили пароль для дополнительной защиты закрытого ключа, вводить дополнительную информацию не требуется. Безопасность системы поддерживается за счет использования как открытых, так и закрытых ключей, которые сопоставляются для установления безопасного соединения при обнаружении.
При первом подключении вы получите предупреждение о неизвестном хосте. Система спросит, доверяете ли вы ей. Чтобы продолжить, введите «да» и нажмите клавишу ввода.
Для максимальной безопасности рекомендуется не использовать учетную запись суперпользователя для этого подключения. Кроме того, связь между терминалом локального компьютера и удаленным сервером можно сделать более безопасным, указав в команде параметр -N. Пример команды показан ниже:
Существуют 2 способа установить туннелирование в Windows (консоль и PuTTygen).
Команда для PowerShell:
ssh-keygen -t rsa
У вас есть возможность либо защитить закрытый ключ паролем, либо оставить поле пустым и нажать Enter.
Открытый ключ по умолчанию хранится в файле ~/.ssh/id_rsa.pub, а закрытый ключ с именем id_rsa находится в том же каталоге. Вы можете получить доступ к файлу открытого ключа через текстовый редактор или с помощью команды Cat в PowerShell.
cat ~/.ssh/id_rsa.pub
Скопируйте открытый ключ, перенесите его на сервер. Выполните соединение:
ssh root@HOST
Вместо использования параметра HOST соединение с удаленным сервером будет установлено с использованием его общедоступного IP-адреса. Если вы не установили пароль для дополнительной защиты закрытого ключа, вводить дополнительную информацию не требуется. Система проверит открытый и закрытый ключи, и если они совпадут, в Windows будет установлен SSH-туннель.
При первом подключении может появиться предупреждение о неизвестном хосте. Система предложит вам подтвердить, доверяете ли вы ей. Чтобы продолжить, введите «да» и нажмите Enter.
Чтобы сгенерировать пароль с помощью PuTTygen:
Нажмите кнопку Generate.
Подвигайте курсором в любом направлении до тех пор, пока строка прогресса не заполнится.
Сохраните публичный и приватный ключи.
Откройте файл с публичным ключом.
Скопируйте публичный ключ и добавьте его на удаленный сервер.
Для подключения также можете использовать PuTTy. Запустите программу, введите исходные данные для подключения.
SSH Proxy
SSH-tunnel Proxy — инструмент для обеспечения безопасного доступа к системе. Приложения должны использовать SOCKS-proxy. Например, сотрудник, находясь в удаленной точки мира от офиса, осуществляет подключение в корпоративную сеть, используя зашифрованный туннель, чтобы никто не смог получить поток конфиденциальных данных. Туннелирование:
ssh -D 8888 user@remoteserver
Команда запускает прокси, порт 8888 (служба работает на localhost).
В этом случае, вы прослушиваете входящий трафик Wi-Fi/Ethernet.
Динамический туннель
Сокет TCP на локальном хосте позволяет открыть динамический туннель SSH. Этот тип туннелирования используется в случае, если необходимо создать приватное соединение, но такой возможности нет.
Прокси SOCKS функционирует на порте 1080. Через динамический туннель невозможно открыть порты во внешний периметр. Чтобы настроить туннелирование в PuTTy (Connection — SSH — Tunnels).
Форвардинг портов
Открывается порт на хосте, после также открывается порт на сервере.
Rsync перед изготовлением копии просматривает историю бэкапов, чтобы избежать повторения.
Запуск приложений
ssh -X remoteserver vmware
Пример команды, запускается vmware.
Прыжки по хостам
При наличии сегментированности в сети, нужно проложить туннель через все пункты, чтобы обезопасить канал передачи данных. Параметр -J поможет установить цепочку переадресаций:
ssh -J host1,host2,host3 user@host4.internal
Локальная папка на удаленной машине
sshfs user@proglibserver:/media/data ~/data/ sshfs свяжет каталог с сервером
SSH — протокол, предназначенный для обеспечения дистанционного управления ОС. Удаленное подключение возможно осуществить к любой серверной машине, на которая управляется ОС из группы Linux. В Windows существует аналогичная возможность, используется другой протокол — RDP.
Доступ к серверу
Чтобы подключиться по SSH, необходимо знать IP и данные учетной записи администратора. Эти данные вы можете найти на электронной почте, которую использовали для активации VDS.
Порт должен быть 22, Тип Соединения — SSH. Host Name установите IP-адрес сервера. Нажмите Open.
Приложение предупредит вас о подключении к новому серверу. Выберите Да.
Осуществите подключение к серверу в режиме администратора (root — логин).
Далее вам необходимо ввести пароль. Пароль вводится в слепом (безопасном режиме), поэтому не обращайте внимание на отсутствие символов. В случае, если вы ошиблись, увидите сообщение Access denied. После успешного входа, вы увидите символику терминала в консоли:
Как подключиться к серверу по SSH с компьютера на Linux/MacOS
Найдите в Spotlight Терминал.
Подключение по SSH:
ssh username@ip_adress
username замените на логин пользователя в вашем случае, ip-address — IP сервера, к которому необходимо подключиться. Команда для нестандартного порта:
ssh username@ip_adress -p 22
Далее, введите пароль, подтвердите подключение. Нажмите Enter, если все в порядке, перед вами появится символика терминала виртуального сервера.
DNS
Система доменных имен (DNS) — это фундаментальная технология современной всемирной паутины. Он основан на иерархической системе именования устройств, служб и ресурсов.
Спецификация DNS была впервые описана в 1983 году Джоном Постелом и Полом Мокапетрисом. Они разработали уникальную структуру идентификации хоста, которая включает в себя как имя, так и категорию.
Через год была введена общая классификация доменов верхнего уровня (gTLD), которая включала описания основных доменов, таких как .com, .org, .edu и других.
Использование DNS
Любой сайт, доступный в глобальной сети. Для развития такого устройства в сети, ему предстоит заболеть IP-адрес — идентификатор вида XXX.XXX.XXX.XXX.
Для открытия определенного сайта необходимо узнать IP-адрес устройства, на котором он расположен.
Пользователи каждый день работают с загрузкой сайтов, и очень сложно запоминают IP-адреса стольких устройств. Поэтому для упрощения работы использовалась система доменных имен.
Порядок работы DNS
Доменное имя обеспечивает простое и запоминающееся имя для любого IP-адреса. Когда пользователь вводит доменное имя в свой браузер, запрос перенаправляется на сервер DNS (система доменных имен). Затем сервер преобразует доменное имя в IP-адрес и ищет во всемирной паутине соответствующее устройство. Если устройство обнаружено, сервер отправляет ему запрос и получает ответ, который затем отображается пользователю. С другой стороны, если IP-адрес устройства не может быть определен, пользователь получит сообщение об ошибке.
Ресурсные записи:
A — главный IP. Формат:
yandex.ru
A
000.000.000.000
cloud.yandex.ru
A
000.000.000.000
CNAME — определяет привязку доменов нижнего уровня к основному:
Когда пользователь вводит адрес веб-сайта в свой браузер, браузер сначала проверяет наличие локального файла под названием «hosts» на компьютере пользователя. Этот файл сопоставляет домен с IP-адресом и полезен только в том случае, если веб-сервер развернут на компьютере пользователя. Если адрес найден в файле hosts, сайт загрузится сразу. Если нет, браузер отправляет DNS-запрос на серверы интернет-провайдера, чтобы найти IP-адрес домена.
Интернет-провайдер имеет локальные кэширующие DNS-серверы на своем сетевом оборудовании. DNS-сервер проверяет кэш на наличие записей, соответствующих домену и IP-адресу. Если запись найдена, браузер принимает IP-адрес, и страница открывается пользователю. Если запись не найдена, сервер провайдера передает запрос на корневые DNS-серверы.
Корневые DNS-серверы знают о DNS-серверах определенной доменной зоны, в данном случае .ru. Они проверяют доменное имя и отправляют его на соответствующие DNS-серверы для разрешения. DNS-серверы зоны .ru хранят информацию обо всех доменах в своей зоне. При вводе доменного имени, такого как yandex.ru, DNS-сервер получателя получает соответствующий ему IP-адрес. Затем сервер провайдера кэширует этот IP-адрес и отправляет ответ обратно.
Типы DNS-серверов
TLD-сервера — содержат в себе домены высшего уровня хоста.
Корневые — серверы, находящиеся на верхнем уровне системы доменных имен. Количество корневых серверов — 13. Необходимы для анализа запросов. Авторитативные — самый низкий уровень в иерархии, содержат в себе записи об IP-адресах.
Типы DNS-запросов
Итеративные запросы — эти запросы отправляются в случае, если преобразователь не возвращает ответ по причине отсутствия кеширования. Рекурсивные — первоначальные DNS-запросы используют преобразователь — механизм, предназначенный для преобразования имен хостов в соответствующие им IP-адреса. Как правило, поставщику услуг Интернета (ISP) отправляются только рекурсивные запросы.Нерекурсивные — запросы, отправленные распознавателю, могут дать немедленные результаты либо путем немедленного направления на авторитарный сервер, либо путем доступа к зашифрованному IP-адресу на соответствующем DNS-сервере.
Управление с Cloud DNS
Инициализируйте зоны DNS. У вас есть возможность создать публичную зону DNS, а также внутреннюю.
Добавьте записи — https://cloud.yandex.ru/docs/dns/operations/resource-record-create
Установите роли — https://cloud.yandex.ru/docs/iam/operations/roles/grant
СХД (Система хранения данных)
Системы хранения данных (СХД) представляют собой совокупность аппаратных и программных компонентов, предназначенных для хранения и обработки больших объемов информации. В качестве носителей информации используются жесткие диски, в первую очередь SSD и гибридные решения, объединяющие SSD и HDD накопители в одной СХД.
СХД отличаются от пользовательских жестких дисков своей сложной архитектурой, возможностью сетевого хранения, отдельным программным обеспечением для управления системой хранения, развитыми технологиями резервного копирования, сжатия и виртуализации.
DSS различаются в зависимости от нескольких параметров, выбор которых определяет использование DSS.
Уровни хранения
Блочное хранилище
Блочные запоминающие устройства (BSD) используются как традиционные диски, которые можно форматировать, устанавливать на них ОС и создавать логические диски. Данные хранятся в блоках, что ускоряет операции ввода-вывода. В основном они используются в сетях типа Storage Attached Network (SAN). BSD подходят для высокопроизводительных вычислений, баз данных, хранения больших данных и сред разработки/тестирования. К недостаткам можно отнести сложность настройки и обслуживания, требующих соответствующих знаний, и высокую стоимость.
Файловое хранилище
Данные хранятся в виде файлов, размещенных в каталогах. Этот тип хранилища используется для хранения «холодной» информации, которая не требуется для оперативных вычислений. Системы хранения файлов обычно строят сетевое хранилище (NAS). К недостаткам можно отнести усложнение иерархии папок по мере роста объема данных и постепенное снижение производительности хранилища. Они не подходят для нагрузок, требующих высокой скорости отклика.
Хранилище объектов
Устройства хранения объектов (OSD) предназначены для работы с большими объемами неструктурированных данных размером до петабайт. Информация хранится в виде объектов, каждый из которых имеет метаданные и собственный уникальный идентификатор. OSD обладают высокой масштабируемостью и могут обрабатывать огромные объемы данных, но время извлечения данных может быть меньше, чем в BSD или системах хранения файлов. OSD обычно используются в облачных вычислениях, управлении цифровыми активами и архивировании.
Сетевой доступ
Сетевое хранилище (NAS)
Это файловый сервер, интегрированный в локальную сеть. Доступ к хранилищу осуществляется по таким протоколам, как NFS (в системах UNIX/Linux) или CIFS (в Windows). NAS используется для управления данными файлового типа, требующими одновременного коллективного доступа, например, совместно используемыми документами Word и Excel. NAS работает поверх существующей локальной сети через общие коммутаторы/маршрутизаторы.
Сеть хранения данных (SAN)
Это сеть, предназначенная для использования различных типов хранилищ, таких как дисководы, оптические приводы и ленточные массивы, которые воспринимаются операционной системой как единое логическое хранилище или как сетевой логический диск. Используемые протоколы: iSCSI (IP-SAN) и FibreChannel (FC). Компьютеры подключаются с помощью адаптеров главной шины (HBA). SAN в основном использует хранилище блочного типа.
Различия
Различие между SAN и NAS стало менее жестким по сравнению с началом 2000-х годов, так как с появлением протокола iSCSI производители начали выпускать гибридные решения.
Отказоустойчивость
Для оценки способности системы хранения восстанавливаться после сбоев используются две метрики: RPO и RTO.
RPO (Цель точки восстановления)
Относится к количеству времени между сбоем и созданием последней резервной копии. Это определяет объем данных, которые могут быть потеряны в случае сбоя. Если для RPO установлено значение 12 часов, данные, накопленные за последние 12 часов, могут быть потеряны в случае сбоя хранилища. RPO влияет на выбор технологии аварийного восстановления и зависит от стоимости потери определенного объема данных.
RTO (целевое время восстановления)
Относится к количеству времени, которое требуется для восстановления доступа к системе хранения после сбоя. Значение RTO важно для определения стоимости простоя системы.
Резервное копирование и восстановление
Частота создания резервных копий определяется исходя из конкретных требований и желаемого уровня защиты. То же самое относится и к хранению, при этом рабочие данные и их резервная копия хранятся в территориально распределенных системах хранения, таких как дата-центры, расположенные в разных странах или континентах.
В дополнение к резервным копиям также делаются моментальные снимки, которые представляют собой мгновенные «изображения», используемые для возврата системы к ее последней рабочей версии.
Для минимизации места для хранения резервных копий применяется дедупликация, при которой в резервной копии перезаписываются только измененные данные. Разница между резервными копиями обычно не превышает 2%, поэтому дедупликация помогает экономить место на диске.
Как выбрать сеть хранения данных (SAN)
Первый шаг — понять задачи, которые будет выполнять SAN. Прежде чем обращаться к поставщику или интегратору, вы должны определить несколько основных параметров.
Тип данных
Разные типы данных требуют разной скорости доступа, технологий обработки, сжатия и так далее. Например, SAN для работы с большими медиафайлами отличается от той, которая подходит для работы с транзакционными базами данных или системы, которая будет работать с неструктурированными данными для нейронной сети.
Объем данных
От этого будет зависеть выбор дисков. Иногда может хватить SSD потребительского класса, если известно, что емкость SAN не превысит 300 ГБ в худшем случае и скорость доступа не критична.
Устойчивость
Необходимо учитывать стоимость потери данных за определенный период времени. Это поможет рассчитать RPO и RTO и избежать ненужных затрат на резервное копирование.
Производительность
Если SAN приобретается для нового проекта (сервиса), о загруженности которого трудно судить, лучше всего поговорить с коллегами, которые уже решили эту проблему. Или обратитесь за советом к опытному поставщику или интегратору.
SSH
Протокол Secure Shell (SSH) — это протокол для безопасного удаленного доступа к системам. Он является членом семейства прикладных протоколов, наряду с другими, такими как HTTP, SMTP, SNMP, FTP и Telnet. SSH работает на порту 22, хотя этот порт можно изменить во время настройки конфигурации.
По сравнению с протоколом Telnet SSH передает зашифрованный трафик, защищенный ключом шифрования, что делает его более безопасным вариантом для удаленного доступа.
Как работает SSH
SSH — протокол, предназначенный для обеспечения передачи данных в зашифрованном виде, используя ключи шифрования. Шифрование отнимает много времени у злоумышленника, который перехватывает зашифрованный поток данных, чтобы расшифровать его, что делает данные устаревшими.
Асимметричное шифрование использует два ключа для шифрования и расшифровки данных. Ключ SSH — это последовательность случайных символов, которая используется для шифрования данных. После шифрования данные отправляются на конечный узел. Открытый ключ используется для шифрования данных и может быть передан другой стороне, которой необходимо отправлять зашифрованные сообщения/данные. Закрытый ключ расшифровывает данные и должен храниться в безопасности. При создании ключа можно зашифровать закрытый ключ с помощью пароля.
Использование ключа при работе с SSH
Успешное соединение между сервером и клиентом может быть установлено, когда файл конфигурации протокола SSH правильно настроен на сервере и открыты необходимые порты. Клиент должен отправить свой открытый ключ на сервер, чтобы сервер мог зашифровать данные обратно клиенту по защищенному каналу.
Когда клиент отправляет запрос на подключение к серверу, данные шифруются с использованием закрытого ключа клиента, который доступен только клиенту. Затем зашифрованный трафик проходит по сети к серверу, и сервер отправляет обратно зашифрованный ответ, подтверждающий получение данных. Затем сервер продолжает отправлять зашифрованный трафик, используя открытый ключ шифрования.
Клиентом может быть любое устройство с доступом в Интернет и клиентское приложение SSH. Клиентом могут выступать: компьютеры (ноутбуки), устройства с операционной системой Android, устройства IOS.
SSL-сертификат
SSL (Secure Sockets Layer) — это протокол шифрования, который позволяет шифровать данные для более безопасной связи.
Сертификат защищает соединение между человеком и веб-сайтом, который он использует. Это гарантирует, что информация, которой обмениваются браузер и сервер, например, при просмотре видео на YouTube, остается защищенной.
SSL-сертификат защищает информацию, передаваемую между человеком и веб-сайтом от перехвата внешними субъектами, такими как администраторы сетей Wi-Fi, провайдеры, операторы и другие. Это также подтверждает надежность сайта и идентифицирует настоящего владельца ресурса. Веб-сайты, которые обрабатывают любые формы персональных данных, такие как банки, платежные системы, интернет-магазины и коммерческие платформы, должны иметь SSL-сертификат. Чтобы проверить наличие SSL — найдите значок закрытого замка в адресной строке браузера слева от адреса веб-сайта.
А если на сайт установлен OV или EV сертификат, то при клике на замочек, появятся данные об организации, которой принадлежит сайт.
В таких типах сертификатов во вкладке «Подробнее» вы найдете следующую информацию:
доменное имя, на которое оформлен SSL-сертификат;
юридическое лицо, которое владеет сертификатом;
физическое местонахождение его владельца (город, страна);
срок действия сертификата;
реквизиты компании-поставщика SSL-сертификата
HTTP/HTTPS
HTTP или протокол передачи гипертекста — это технология, обеспечивающая связь между пользователем и сервером. Однако он не защищает передаваемые данные, что делает его уязвимым для перехвата и кражи конфиденциальной информации. Чтобы решить эту проблему, был введен протокол HTTPS — безопасный протокол передачи гипертекста.
HTTPS работает с использованием того же протокола, что и HTTP, но с дополнительным шифрованием за счет использования криптографических методов. Дополнительная буква «S» в HTTPS указывает на то, что соединение защищено. Безопасность обеспечивается сертификатом SSL/TLS, цифровой подписью, которая подтверждает подлинность веб-сайта.
Перед установкой безопасного соединения браузер связывается с центром сертификации, чтобы подтвердить действительность сертификата SSL/TLS. Если сертификат признан законным, браузер и сервер устанавливают доверительные отношения и согласовывают одноразовый шифр. Этот процесс происходит каждый раз, когда инициируется сеанс, то есть каждый раз, когда происходит обмен запросами и ответами.
Таким образом, HTTPS — это более безопасная версия HTTP, обеспечивающая шифрование и проверку подлинности веб-сайта с помощью сертификатов SSL/TLS.
Для чего нужен сертификат SSL
Сертификат SSL имеет решающее значение для веб-сайтов, которые обрабатывают финансовую или личную информацию от пользователей. Сюда входят интернет-магазины, банки, платежные системы, социальные сети, почтовые службы и любые другие сопутствующие проекты.
Рекомендуется с самого начала установить SSL-сертификат, чтобы достичь лучшего рейтинга в поисковых системах. Однако если SSL-сертификат будет добавлен позже, поисковые системы могут распознать изменение только по прошествии нескольких месяцев. К счастью, SSL-сертификаты теперь можно получить бесплатно, что упрощает защиту конфиденциальной информации и повышает общую безопасность веб-сайта.
Аутсорсинг
Аутсорсинг — это привлечение любых сторонних фирм для решения конкретной задачи.
Примеры аутсорса:
заказа еды в офис;
клининга;
охраны объектов;
транспортировки чего-либо;
проведения ремонта и т. д.
Малый бизнес часто не выполняет свои второстепенные задачи самостоятельно (например, юридические и бухгалтерские услуги, обслуживание ИТ-инфраструктуры, сторонним компаниям). Главный принцип аутсорсинга — делегирование служебных (операционных) задач внешним исполнителям.
Необходимость в аутсорсинге
Для малого предприятия создание отдельного подразделения по обслуживанию той или иной системы финансово нецелесообразно для ее управления. В случае более крупной компании с многочисленными специализированными подразделениями, которые не приносят прибыли, руководство может решить передать некоторые процессы на аутсорсинг для улучшения своей статистики. Это связано с тем, что компания не может направить ресурсы на менее важные задачи.
Виды аутсорсинга
Когда возникают более сложные проекты, они часто обращаются к помощи внешних специалистов.. Такой подход может позволить им эффективно решать более сложные бизнес-задачи.
В случае малого бизнеса, сложно организовать штатную команду бухгалтеров. Найм сотрудников и создание бухгалтерского отдела может быть дорогостоящим, так как это связано с покупкой и настройкой специализированного программного обеспечения, дополнительно продумывая систему безопасности. Тогда аутсорсинг бухгалтерского учета может быть довольно жизнеспособным решением. За счет аутсорсинга бухгалтерских услуг небольшие компании могут воспользоваться профессиональными услугами, не беспокоясь о кадровых затратах.
Юридический аутсорсинг является популярным выбором среди частных лиц и компаний всех размеров и типов. За счет аутсорсинга юридических услуг частные лица и компании могут получить доступ к экспертным знаниям, которые им необходимы в конкретном юридическом вопросе.
Аутсорсинг персонала обеспечивает решение распространенной проблемы неэффективности секретарей, юристов и бухгалтеров. Передавая HR-задачи на аутсорсинг, компании могут улучшить управление персоналом.
Услуги аутсорсинга продаж предлагают решение проблемы поиска профессиональных менеджеров по продажам.
Veeam Backup и копирование на хранилище (S3)
Необходимость в резервных версиях
Поломка системы может произойти совершенно неожиданным образом. И понять, что стало причиной краха, внешние факторы или некомпетентность сотрудников, бывает не всегда возможно. Помимо поломок, специалист, работающий с данными сервера, может совершить ошибку и, например, удалить важные данные. Резервное сохранение — верный способ обезопасить себя от случившихся, или пока еще нет, обстоятельств.
Готовим данные к бэкапу
Вам понадобятся привилегированные права на управление сервером, данные и версии которого необходимо зарезервировать, сервер на Windows Server, на котором будет установлена утилита Veeam Backup и контейнер-хранилище для копий. Грамотно выстроенная система управления версиями — фундамент, на котором базируются бесперебойность и гибкость рабочей системы.
Конфигурация бэкапа
Первым делом осуществите подключение к серверу, объекту бэкапа, по RDP, и скачайте S3-Browser. Затем создайте аккаунт и заполните поля ввода.
Нажмите на New Bucket и откройте новое хранилище S3:
Необходимо установить и инициализировать утилиту для развертывания хранилищ S3, которую можно скачать по ссылке. Далее, после установки, перезагрузите сервер, откройте TNT Drive, выберите создание нового аккаунта и введите учетные данные.
Drives — Add new drive, определите развертывание виртуального хранилища, как локального диска.
На главной странице удостоверьтесь в наличии подготовленного контейнера:
Пришло время открыть Veeam Backup. В разделе Backup Infrastructure добавьте новое место хранения. Точку сохранения лучше привязать к папке, где подключен S3.
Для доступности лучше удалить папку, созданную при установке мест хранения.
Откройте вкладку Home, задайте работу по бэкапу версий компьютера на LINUX.
Mode работы зависит от потребностей в контексте задачи. Удаленные сервера лучше использовать в связке с агентом, который будет развернут на сервере-источнике.
Выберите название работы и установите данные, необходимые для соединения с сервером.
Выберите объект резервации и место сохранения копий.
Выберите частоту резерваций, после сохраните настройки кнопкой Apply.
Установка Seafile на Windows
Облачные сервисы — тренд в информационных технологиях. Это обусловлено тем, что на смену классическим технологиям приходят сквозные, более гибкие и более масштабируемые.
Готовим необходимые компоненты
В основе Seafile используется Python, проверьте, что у вас установлена актуальная версия языка или скачайте на официальном сайте и разверните Python.
Для дальнейших настроек необходимы права администратора. Настройте виртуальное окружение.
Выберите опцию «Переменные среды».
В новом окне отметьте в качестве системной среды Path, выберите «Изменить».
Укажите путь, который вы использовали во время установки Python.
Вы увидите, что программа доступна только на платформе LINUX. Скачайте свежую версию, после разверните на локальном диске папку, в которую поместите архив скачанной утилиты.
Перейдите в директорию Seafile, запустите run.bat.
Перед вами откроется панель, при помощи которой происходит инициализация.
Как только процесс установки завершился, правой кнопкой мыши вызовите меню, отметьте пункт:
После вам необходимо ввести учетные данные для получения доступа к Seafile-серверу.
Следующая задача — изменить конфигурацию рабочей области.
Перейдите в каталог, где лежат файлы сервера, откройте файл ccnet.conf для редактирования, в файле отыщите Service_url, измените значение:
IP измените на IP предполагаемого сервера для использования. Осуществите перезапуск серверной части, через контекстное меню:
Подключитесь
Откройте браузер, в поисковую строку вставьте адрес, указанный ранее в файле ccnet.conf.
В случае, если вы выполнили инструкцию последовательно и правильно, вас встретит страница Seafile, на которой необходимо авторизоваться, чтобы начать настройку работы с хранилищем.
Zabbix — Windows
Софт, предназначенный для контроля локальных ресурсов и приложений в сетевых системах. Может быть установлен на Windows & *nix. Для установки вам необходим сервер Zabbix и узел на базе OS Windows.
В главных настройках необходимо указать IP или хост Zabbix-сервера. При необходимости управления с мастер-сервером, укажите это в настройках (галкой).
Укажите путь установки:
Завершите установку:
Делегирование домена
Делегирование домена возможно только в том случае, если домен 2 уровня. Найдите на сайте Server Space пункт в меню DNS, подпункт «Добавить домен».
Добавьте ваш домен. После чего, у вас есть несколько вариантов, как провести перенос:
укажите IP сервера или выберите виртуальный сервер (с виртуальным сервером необходимо самостоятельно указать записи DNS)
установить автоматический перенос записей DNS
В панели администрирования записями DNS измените параметры записи NS переносимого домена на адреса конечных NS серверов.
Когда вы установили настройки делегирования, вам необходимо подождать некоторое время (от 6 до 24 часов). Как только процесс завершится успешно, вы сможете управлять записями домена.
Перенос 1С в облачное пространство
В погоне за аутсорсингом ПО, многие инструменты переживали миграцию в облако. Облачные решения удобны в использовании, довольно экономически выгодные. Облачная версия 1С позволяет тратить намного меньше ресурсов на приобретение и организацию программного обеспечения. Облачная 1С исключает ИТС. Гибкое масштабирование. Аренда 1С позволяет организовывать базы данных без численного ограничения. Во время случайных инцидентов риск потерять информацию снижается. Информация хранится не на рабочей станции, а в дата-центре. Также, файлы и корпоративные документы могут быть перенесены в общий пул доступа. Доступ к данным может осуществляться независимо от времени, 24/7.
1С в облаке:
арендная плата
интернет
Подобная форма ПО удобна для любых уровней предпринимательства, начиная от свежих стартапов, заканчивая крупными корпорациями.
Доступ к облаку 1C
RemoteApp — мультиплатформенное приложение. Устанавливает соединение посредством SSL. RDP — виртуальное соединение через SSL. Проще говоря, удаленный рабочий стол. Все вычисления происходят на стороне сервера, утилита является лишь туннелем для подключения.
Переход в облако 1С
Первоначально, выберите туннель для подключения в зависимости от поставленной задачи. Создайте профиль в системе 1С, закажите конфигурацию. На почту, которую вы указали при регистрации, отправятся данные для входа.Начните переносить БД самостоятельно или обратитесь к специалистам из технической поддержки.
У вас уже есть лицензия 1С
В случае, если у вас есть 1С, но вы не хотите приобретать еще одну лицензию на облачную версию, вы можете перенести классический 1С на виртуальный сервер. Для этого, обратитесь в службу поддержки и получите программный ключ. Если у вас уже есть ключ, передайте его в 1С Сервер. Вы также получите письмо на электронную почту, в котором найдете данные для входа.
VStack
vStack — современная гиперконвергентная платформа. Подходит для создания виртуального ЦОД корпоративного уровня на базе оборудования потребительского класса.
В его основе — программно-определяемые модули, объединяющие слои хранения, вычислений и сети. Кластерный фреймворк объединяет узлы и обеспечивает резервирование ресурсов.
vStack — полностью отечественный продукт, включенный в реестр российского ПО. Российская разработка является аналогом платформы VMware, но не копирует ее, а выполняет те же задача, иногда более эффективно.
Преимущества российской гиперконвергентной платформы vStack:
высокая производительность во всех слоях,
низкие издержки в слое программно-определяемых вычислений (2-5%), возможность управлять IT-инфраструктурой из общего интерфейса,
гибкость, легкая масштабируемость и возможность заменять вышедшие из строя компоненты без простоев,
отсутствие избыточности в коде,
отсутствие привязки к поставщикам, возможность самостоятельно выбирать оборудование,
возможность оплачивать только те ресурсы, которые используются,
работа в условиях CPU overcommit до 900%,
CPU overhead 2-5% вместо стандартных 10-15%.
Удаленное рабочее место
Удаленное рабочее место — это способ организации процесса работы специалиста, отдела или организации в целом, при котором обеспечивается удаленный доступ к рабочему месту сотрудников.
Способы организации удаленного рабочего места
RDS (терминальный доступ) — множество серверов или один сервер, к которым сотрудник осуществляет удаленное соединение. Многопользовательский доступ к общей виртуальной среде.
VDI (виртуальное рабочее место) — объединенный накопитель, который хранит данные всех сотрудников, но при этом разделенных рабочий стол для каждого специалиста. Эта форма надежнее, чем терминальный доступ.
Для чего нужно УРМ
Удаленное рабочее место способствует повышению уровня безопасности корпоративных данных. Также, использование УРМ позволяет организовывать работу офисов без привязки к геопозиции (мобильность). При частичном переводе сотрудников на УРМ можно воспользоваться услугами вендора. В случае, если вы запланировали полный перевод офиса на УРМ, то стоит воспользоваться своей инфраструктурой.
Как организовать УРМ
Для организации удаленного рабочего места компании обычно обращаются к провайдерам, которые решают вопросы, связанные с логистикой и техническим оснащением. При этом формате возможно существовать без организации собственной сетевой инфраструктуры.
Провайдер
Провайдер — это компания-поставщик, которая обеспечивает доступ к сети интернет и иных услуг.
Услуги провайдера
Провайдер предоставляет услуги как физ. лицам, так и другим организациям. Обеспечение доступа в интернет может происходить с помощью:
Digital Subscriber Line. Реализация интернет-соединения через телефонные линии. Способ постепенно становится неактуальным, многие делают выбор в сторону оптоволокна и витой пары. DSL обеспечивает скорость загрузки от 5 до 35 Мбит/с, скорость выгрузки — от 1 до 10 Мбит/с.э
Использование витой пары (коаксиального кабеля). Данный канал связи характеризуется низкой задержкой, скоростью загрузки от 10 до 500 Мбит/с, скоростью передачи информации — от 5 до 50 Мбит/с.
Оптоволокно. Скорость выше, чем у DSL и витой пары. Скорость загрузки данных по оптоволокну составляет от 250 до 1 000 Мбит/с, скорость передачи данных — от 250 до 1 000 Мбит/с.
Использование спутников. Станции, расположенные на Земле принимают данные в виде интернет-волн от аппаратов, которые находятся на околоземной орбите. Преимущество спутникового интернета — дистанция (более широкий охват территории). Скорость загрузки — от 12 до 100 Мбит/с, скорость выгрузки — 3 Мбит/с.
Кроме основной услуги (доступ в интернет) провайдеры предоставляют дополнительные возможности для клиента. К дополнительным услугам относятся:
веб-хостинг
аренда виртуальных серверов
место для физического оборудования в ЦОД
мобильная коммерция
payment сервисы
регистрация доменов
Работа провайдера
У провайдера есть оборудование, которое необходимо для выхода в сетевое пространство в обслуживаемой геопозиции. Множество провайдеров объединены друг с другом посредством точек доступа к сети. Существуют уровни провайдеров:
Tier-1. Имеют доступ к трансконтинентальным каналам связи, которые обеспечивают интернет-соединение. Провайдеры на этом уровне обладают наибольшим влиянием, способны обрабатывать огромное количество трафика. Организации первого уровня предоставляют доступ к сети провайдерам Tier-2 (второй уровень).
Tier-2. Национальные провайдеры, покрывающие своими услугами территорию определенной страны. Деятельность компаний второго уровня ориентирована на работу с коммерческими клиентами.
Tier-3. Городские или региональные провайдеры, доставляющие трафик для конечного пользователя. Провайдеры третьего уровня покупают доступ у представителей вышележащих уровней, чтобы обеспечить клиентов доступом в интернет.
Виртуализация
Виртуализация — технология, позволяющая совершать запуск множества ОС одновременно на одном оборудовании. При виртуализации локальные ресурсы разделяются, одна часть изолируются. Изолироваться могут как аппаратные ресурсы, так и программные. Первые попытки реализовать идею виртуализации были в 1960-x, технология активно развивается в наши дни.
Аппаратная виртуализация
Виртуализации в случае аппаратных ресурсов могут подлежать:
Не требует использования другой ОС в качестве оболочки. Виртуализация на уровне физического железа, добавляется гипервизор. Гипервизор — операционная система для обеспечения совместного существования множества разделенных сред (виртуальных машин).
Виртуализация второго типа
Физическое железо
ОС (операционная система на носителе)
Гипервизор
ОС для виртуальной машины
При данном типе виртуальное устройство отделяется от основной системы с помощью приложений виртуализации (Hyper V, VirtualBOX). Виртуализация способствует безопасности рабочего стола. Все изменения пользователя внутри изолированной среды не касаются главной системы.
Применение виртуализации
Классическая ситуация: вы скачали файл, но не уверены в том, что источник надежный. Для тестирования скачанной утилиты, создайте виртуальную машину с изоляцией от основной системы. В случае заражения виртуальной машины пользователь может ее удалить или вернуть в исходное состояние (после инициализации).
Виртуальный дата-центр (vDC)
Виртуальный центр обработки данных — совокупность ресурсов в облаке, объединенные для формирования корпоративной вычислительной инфраструктуры.
Виртуальный дата-центр включает в себя:
хранилище (дисковое пространство)
оперативную память
сеть
В результате создания vDC инфраструктура аналогична физическому центру обработки данных, но при этом имеет некоторые преимущества:
отказоустойчивость
доступность
оптимизация
устойчивость к инцидентам
возможности быстрого создания сред для тестового запуска
Виртуальная инфраструктура управляется через веб-интерфейс. У клиента есть возможность гибко настраивать виртуальную среду: создавать новые виртуальные машины, изменять настройки сети, создавать снапшоты и резервные копии.
Протокол S3: подключение
Чтобы подключиться по S3 к хранилищу, установите программу S3Browser. После инсталляции, откройте утилиту, найдите в меню пункт Accounts, перейдите во вкладку Add new account
В поле Account Name введите любое осмысленное название. В поле Account Type выберите S3 Compatible Storage. В пункте REST Endpoint добавьте адрес EndPoint (содержится в панели управления хранилищем). Введите данные в поля Access Key ID и Secret Access Key в соответствии с установленными ключами хранилища.
В Use secure transfer добавьте галочку. Перепроверьте все настройки и создайте новый аккаунт. Чтобы осуществить соединение, в пункте Accounts найдите подпункт для установки подключения.
Установка Netcat на Linux/Windows
Netcat — утилита, предназначенная для мониторинга сети. Является частью очень популярной Nmap.
Windows
Первоначально, вам необходимо подключиться к серверу с правами администратора. После этого, загрузите файл-инсталлятор nmap. Откройте его, отметьте необходимые пункты. Когда перед вами появится страница выбора компонентов, отметьте ncat, начните установку (скриншот ниже).
Откройте cmd, определите версию установленной утилиты ncat:
ncat -v
Работа с Netcat
Откройте два экземпляра cmd. В первом запустите ncat -l <port>. Во втором введите команду:
ncat -C localhost <port>
Nmap Linux
Войдите с правами администратора.
Для начала, обновите все системные файлы и пакеты:
apt-get update; apt install -y netcat
По аналогии с Windows, команды те же, проверьте версию и начните использование утилиты.
VMware
VMware — международный поставщик ПО для виртуализации и облачных вычислений. Виртуализация VMware основана на использовании гипервизора ESX/ESXi с архитектурой x86. Помимо средств виртуализации компания разрабатывает и производит ПО для управления сетями и информационной безопасностью, ПО для программно-определяемых ЦОД и хранения.
Виртуализация серверов предусматривает установку на физическом сервере гипервизора, с помощью которого можно запустить сразу несколько виртуальных машин, использующих общие ресурсы. Каждая виртуальная машина может запускать свою собственную ОС. Благодаря этому на одном физическом сервере может работать несколько операционных систем.
Продукты VMware
VMware NSX — приложение для виртуальных сетей и безопасности, позволяющее виртуализировать сетевые компоненты. Используется для разработки и развертывания виртуальных сетей с помощью ПО.
VMware Cloud Foundation — интегрированный программный стек, объединяющий vSphere, VMware vSAN и VMware NSX в единую платформу.
VMware vSAN — программная функция хранения данных, встроенная в гипервизор ESXi. Ее задача — объединить дисковое пространство с нескольких хостов ESXi. Интегрируется с vSphere High Availability для повышения доступности вычислений и хранилищ.
VMware vCloud NFV — платформа виртуализации для запуска сетевых функций как виртуализированных приложений различных производителей.
VMware Fusion — ПО для виртуализации ОС Windows или Linux на компьютерах Mac.
К преимуществам VMware относится безопасность, основанная на модели нулевого доверия, упрощенное управление и повышение гибкости ЦОД. Среди недостатков — высокая стоимость лицензирования и проблемы с совместимостью оборудования. На данный момент компания полностью приостановила продажи и поддержку своих продуктов в России.
ЦОД
ЦОД — здание или отдельное помещение, которое является местом размещения сетевого оборудования, вычислительных платформ и дисковых хранилищ.
Центр обработки данных — специализированный объект, гарантирующий сохранность данных, а также обеспечивающий их резервное копирование.
Типы ЦОД
Классический ЦОД. Большое здание с размещенным внутри оборудованием. Этот тип появился первым и не потерял актуальность до тех пор.
Облачный ЦОД. Клиент не занимается обслуживанием оборудования, только платит за удаленные ресурсы.
Модульный дата-центр. Удобно использовать в случае частых релокаций.
Контейнерный дата-центр. Используется при сложных условиях эксплуатации. Похож на модульный тип.
Пользователям доступны различные варианты конфигураций. Самый мобильный вариант — облачный ЦОД, а самый надежный — контейнерный, который развернут на территории заказчика.
Избыточность
Каждый центр обработки данных состоит из нескольких узлов, лежащих в основе, которые обеспечивают работоспособность и надежность ЦОДа. Те узлы, которые представляют для системы наибольшую ценность, должны быть продублированы.
Схема N+1
Базовый механизм создания резерва. Инициализируется копия важного (ых) компонента (ов) системы. Если основной компонент выходит из строя (отключается), запасной активируется (выполняет роль главного).
Схема 2N
Два независимых элемента. Когда один их них не способен функционировать, задачи делегируются рабочему компоненту.
Схема 2(N+1)
У каждого компонента есть резерв. При использовании данной схемы инфраструктура приобретает высокие характеристики отказоустойчивости. Но стоит отметить, что данный метод обеспечения избыточности стоит довольно дорого.
Мы используем файлы cookie и системы аналитики для улучшения работы сайта. Продолжая использовать сайт, Вы соглашаетесь с обработкой персональных данных, собираемых посредством Яндекс Метрика, в целях аналитики посещаемости сайта, Политика обработки персональных данных.